Let’s talk about the conclusion first: the optimizer is changed to AdaFactor
Recently, I used the Google T5model model for some semantic recovery experiments. I referenced some codes on github. At the beginning, I used the T5-base model to train on the server. I used a 30-series graphics card with a video memory of 8192MiB and batch_size. 32. There is no problem with the full video memory during training, and the effect is not bad.
Then I saw that some papers used the T5-large model, and the effect would be better than the T5-base model. After all, there are more parameters, so I thought about changing the ‘t5-base’ to ‘t5-large’ when calling the model. The big deal is that the batch_size is small. A little, can you run too?
model = T5ForConditionalGeneration.from_pretrained('t5-large')
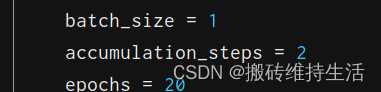
Then I found that batch_size = 1 does not work, just OOM, go to huggingface to find some tips for training T5, there is a suggestion to change the optimizer AdamW to AdaFactor to run T5-large. Purpose of AdaFactor: To propose a low-cost, memory-intensive alternative to general adaptive optimization methods for large models with a huge number of parameters. A reference parameter is given below.
optimizer = Adafactor(
model.parameters(),
lr=1e-3,
eps=(1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
relative_step=False,
scale_parameter=False,
warmup_init=False
)
Although it can only run a small amount of data in the last time, it can at least run, and can compare the difference between base and large. So finetune T5-large still needs powerful hardware support.