Bean Searcher claims that any complex query can be done with one line of code, but Mybatis Plus seems to have a similar dynamic query function. What is the difference between them?
Difference one (basic)
Mybatis Plus relies on MyBatis, and has CRUD functions, while Bean Seracher does not rely on any ORM, and only focuses on advanced queries.
Only projects using MyBatis will use Mybatis Plus, and people who use Hibernate, Data Jdbc and other ORMs cannot use Mybatis Plus. But all of these projects can use Bean Searcher (with any ORM or on its own).
Using Mybatis Plus requires writing entity classes and Mapper interfaces, while Bean Searcher only needs to write entity classes without writing any interfaces.
This difference is actually of little significance, because if you use Mybatis Plus, you still need to define the Mapper interface when adding, deleting, and modifying.
Difference two (advanced query)
The field operator of Mybatis Plus is static, while that of Bean Searcher is dynamic.
The field operator refers to the condition types of
=,>orlikeused when a field participates in the condition.
Not only Mybatis Plus, the field operators of general traditional ORMs are static, including Hibernate, Spring data jdbc, JOOQ, etc.
The following example illustrates. For a simple entity class with only three fields:
java
copy code
public class User {
private long id;
private String name;
private int age;
// omit Getter Setter
}
1) Query using MyBatis Plus:
rely:
groovy copy code implementation 'com.baomidou:mybatis-plus-boot-starter:3.5.2
First, write a Mapper interface:
java
copy code
public interface UserMapper extends BaseMapper<User> {
}
Then write the query interface in the Controller:
java
copy code
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/mp")
public List<User> mp(User user) {
return userMapper. selectList(new QueryWrapper<>(user));
}
}
At this time, this interface can support three retrieval parameters, id, name, age, for example:
-
GET /user/mp?name=Jack Query the data whose name is equal to Jack
-
GET /user/mp? age=20 Query the data whose age is equal to 20
But the relationship they can express is equal. If you still want to query the data with age > 20, there is nothing you can do unless you add a note to the age field of the entity class:
java
copy code
@TableField(condition = "%s>#{%s}")
private int age;
But after adding annotations, age can only express the relationship that is greater than , and can no longer express equal to. Therefore, the field operator of MyBatit Plus is static and cannot be dynamically specified by parameters.
Of course, we can call different methods of QueryWrapper in the Controller according to the parameters to make it support, but in this way the code is more than one line, and the more complex the retrieval requirements are, the more codes need to be written.
2) Use Bean Searcher to query:
rely:
groovy copy code implementation 'cn.zhxu:bean-searcher-boot-starter:4.1.2'
No need to write any interface, reuse the same entity class, and query directly:
java
copy code
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private BeanSearcher beanSearcher;
@GetMapping("/bs")
public List<User> bs(@RequestParam Map<String, Object> params) {
// Are you biased against the input map? If yes, please look down patiently, there is a plan
return beanSearcher. searchList(User. class, params);
}
}
At this point, this interface can support a lot of retrieval parameters:
-
GET /user/bs?name=Jack Query the data whose name is equal to Jack
-
GET /user/bs?name=Jack & amp; name-ic=true Ignore case when the query name is equal to Jack
-
GET /user/bs? name=Jack & amp; name-op=ct query name contains data of Jack
-
GET /user/bs?age=20 Query the data whose age is equal to 20
-
GET /user/bs? age=20 & amp; age-op=gt Query the data whose age is greater than 20
-
Wait…
It can be seen that the operator used by Bean Searcher for each field can be specified by parameters, and they are dynamic.
Regardless of whether the query requirements are simple or complex, only one line of code is required in the Controller.
What values can the parameterxxx-oppass? See here: bs.zhxu.cn/guide/lates…
Seeing this, if you can understand it, half of the readers should start to feel: Good guy, isn’t this the process of assembling query conditions at the back end to the front end? Whoever uses this framework will not be killed by the front end?
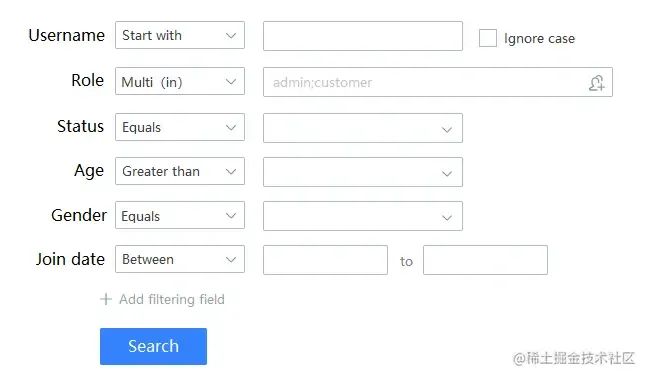
Haha, did I express what you are thinking right now? If you really think so, please review carefully the topic we are discussing: [Advanced Query]! If you can’t understand what an advanced query is, I’ll post another picture to help you think:
Of course, not all retrieval requirements are so complicated. When the front end does not need to control the retrieval method, the xxx-op parameter can be omitted. When omitted, the default expression is equal. If you want to express other methods , just one annotation, for example:
java copy code @DbField(onlyOn = GreaterThan. class) private int age;
At this time, when the front end only passes one age parameter, the executed SQL condition is age > ?, and even if the front end passes an additional age-op code> parameter, also doesn’t work anymore.
This is actually a conditional constraint, which will be discussed below.
Differentiation three (logical grouping)
As far as the code in the above example is concerned, except for the difference between dynamic and static operators, the conditions generated by Mybatis Plus for the received parameters are all and relations, while Bean Searcher is also and by default, but supports logical grouping.
As another example, suppose the query condition is:
( name = Jack and age = 20 ) or ( age = 30 )
At this point, one line of code in MyBatis Plus is powerless, but one line of code in Bean Searcher still works, just pass the parameters like this:
-
GET /user/bs? a.name=Jack & amp; a.age=20 & amp; b.age=30 & amp; gexpr=a|b
Here Bean Searcher divides the parameters into a, b two groups, and uses the new parameter gexpr to express the relationship between these two groups (a or b).
When actually passing parameters, the value of
gexprneeds URLEncode encoding: URLEncode(‘a|b’) => ‘a|b’, because HTTP stipulates that parameters cannot appear on the URL|This special character. Of course, if you like POST, you can put it in the message body.
What scenarios are suitable for using this function? When encountering a demand similar to the one shown in the figure below, it will help you defeat the enemy with one move:

The grouping function is very powerful, but such complex retrieval requirements are indeed rare, so I won’t go into details here. For details, please refer to: bs.zhxu.cn/guide/lates…
Difference four (multi-table joint query)
Without writing SQL, the dynamic query of Mybatis Plus is limited to single table, while Bean Searcher supports both single table and multi-table as well.
This is also a very important difference, because most advanced query scenarios require joining tables.
Of course, some people insist on using a single table for queries. In order to avoid joining tables, many fields are redundant in the main table. This not only causes a sharp increase in the pressure on the database storage space, but also makes the project more difficult to maintain. Because once the source data changes, you must update these redundant fields at the same time. As long as one is missing, the BUG will jump out.
For another example, an order list needs to display information such as order number, order amount, store name, buyer name, etc., using the Bean Searcher entity class can be written as follows:
java
copy code
@SearchBean(
tables = "order o, shop s, user u", // three table association
where = "o.shop_id = s.id and o.buyer_id = u.id", // relationship
autoMapTo = "o" // Fields not annotated by @DbField are mapped to the order table
)
public class OrderVO {
private long id; // Order ID o.id
private String orderNo; // order number o.order_no
private long amount; // order amount o.amount
@DbField("s.name")
private String shop; // shop name s.name
@DbField("u.name")
private String buyer; // buyer name u.name
// omit Getter Setter
}
Interested students will notice that the name of this entity class is not Order, but OrderVO. This is just a suggested naming, because it is essentially a VO (View Object), and its function is only a view entity class, so it is recommended to put it in a different package from the ordinary single-table entity class (this is just a specification) .
Then we still only need one line of code in our Controller:
java
copy code
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private BeanSearcher beanSearcher;
@GetMapping("/index")
public SearchResult<OrderVO> index(@RequestParam Map<String, Object> params) {
// The search method will also return the total number of entries that meet the conditions
return beanSearcher. search(OrderVO. class, params);
}
}
This implements an order interface that supports advanced queries, and it also supports the various retrieval methods shown in Difference 2 and Difference 3 above.
It can be seen from this example that the retrieval result of Bean Searcher is a VO object, not a common single-table entity class (DTO), which saves the conversion process from DTO to VO, and it can be directly returned to the front end.
Difference five (usage scenarios)
MyBatis Plus is recommended for transactional interfaces, and Bean Searcher is recommended for non-transactional retrieval interfaces
-
For example, to create an order interface, there are also many queries inside this interface, such as whether you need to check whether the store is closed, whether the inventory of the product is still sufficient, etc. For these query scenarios, it is recommended to use the original MyBatis Plus or other ORMs. There is no need to use Bean Seracher anymore.
-
Another example is the order list interface, pure query, which may require functions such as paging, sorting, and filtering. At this time, Bean Seracher can be used.
Netizen question
1) This seems to open up a lot of search capabilities, is the risk controllable?
By default, Bean Searcher supports many retrieval methods for each field in the entity class, but we can also restrict it.
Conditions
For example, the name field of the User entity class only allows exact match and post-fuzzy queries, so just add an annotation to the name field:
java
copy code
@DbField(onlyOn = {Equal. class, StartWith. class})
private String name;
Another example: the age field is not allowed to participate in the where condition, then you can:
java copy code @DbField(conditional = false) private int age;
Reference: bs.zhxu.cn/guide/lates…
Sorting constraints
Bean Searcher allows sorting by all fields by default, but it can be constrained in the entity class. For example, to only allow descending sorting by the age field:
kotlin
copy code
@SearchBean(orderBy = "age desc", sortType = SortType. ONLY_ENTITY)
public class User {
//...
}
Or, disable sorting:
kotlin
copy code
@SearchBean(sortType = SortType. ONLY_ENTITY)
public class User {
//...
}
Reference: bs.zhxu.cn/guide/lates…
2) After using Bean Searcher, the input parameter of Controller must be of Map type?
Answer: This is not necessary, but the retrieval method of Bean Searcher accepts this type of parameter. If you use a POJO to receive it in the Controller entry, you only need to use another tool class to convert it into a Map, but just write an extra class for nothing, for example:
java
copy code
@GetMapping("/bs")
public List<User> bs(UserQuery query) {
// Convert the UserQuery object to a Map and pass it in for retrieval
return beanSearcher.searchList(User.class, Utils.toMap(query));
}
Why not use the User entity class directly to receive it here? Because Bean Searcher supports many parameters by default, and the original
Userentity class does not have enough fields, if it is used to receive, many parameters will not be received. If our retrieval requirements are relatively simple and do not require the front-end to specify those parameters, we can directly use theUserentity class to receive them.
Here UserQuery can be defined like this:
java
copy code
// Inherit the fields in User
public class UserQuery extends User {
// Additional: sort parameters
private String order;
private String sort;
// Additional: pagination parameters
private Integer page;
private Integer size;
// Additional: Field Derived Parameters
private String id_op; // Since the field name cannot have a dash, here is an underscore instead
private String name_op; // When the front end passes parameters, it cannot pass name-op, but name_op
private String name_ic;
private String age_op;
// omit other additional fields...
// omit Getter Setter method
}
Then the toMap method of the Utils tool class can be written like this (this tool class is universal):
java
copy code
public static Map<String, Object> toMap(Object bean) {
Map<String, Object> map = new HashMap<>();
Class<?> beanClass = bean. getClass();
while (beanClass != Object. class) {
for (Field field : beanClass. getDeclaredFields()) {
field.setAccessible(true);
try {
// Convert underscores to dashes
Strubg name = field.getName().replace('_', '-');
map. put(name, field. get(bean));
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
beanClass = beanClass. getSuperclass();
}
return map;
}
That’s it, the interface can still support many retrieval methods:
-
GET /user/bs?name=Jack Query the data whose name is equal to Jack
-
GET /user/bs?name=Jack & amp; name_ic=true Ignore case when the query name is equal to Jack
-
GET /user/bs? name=Jack & amp; name_op=ct query name contains data of Jack
-
GET /user/bs?age=20 Query the data whose age is equal to 20
-
GET /user/bs? age=20 & amp; age_op=gt Query the data whose age is greater than 20
-
Wait…
Note that the parameter used is
name_op, notname-opanymore
The above method should meet the expectations of some obsessive-compulsive disorder patients, but the cost is to write an extra UserQuery class, which makes us think: is it worth it?
Of course, there are some advantages to writing it like this:
-
Easy to check parameters
-
Easy to generate interface documentation
but:
-
This is a non-transactional retrieval interface, is parameter verification really that necessary? It is possible to request without parameters. If the parameters are wrongly passed, the system will automatically ignore them. Is it okay?
-
If you understand the Bean Searcher parameter rules, can you generate documents without using this
UserQueryclass, or summarize in one sentence in the document that the interface is the Bean Searcher retrieval interface, please pass the parameters according to the rules, right? OK?
Therefore, my suggestion is: everything should be based on the real needs, and don’t go to the specification for the sake of specification, and increase the code inexplicably.
Seeing this, you may have prepared a lot of words in your heart to refute me. Don’t worry, let’s review what was mentioned in the previous [Multi-table joint query] chapter:
-
The entity class (SearchBean) in the Bean Searcher is actually a VO (View Ojbect) that can directly have a cross-table mapping relationship with the DB. It represents a retrieval service. It is conceptually the same as the traditional ORM entity class (Entity) Or domain class (Domain) has an essential difference!
This sentence expresses the soul of Bean Searcher. It seems simple, but in fact it is difficult to understand. If you are not the kind of genius who is rare in the ages and is born with psychics, it is strongly recommended to read the Introduction > Design Ideas (Starting Point) chapter of the official document, where there is a detailed explanation of this sentence.
3) If you want to manually add or modify parameters, can you only put to Map? Is there an elegant way to write it?
Answer: Of course there is. Bean Searcher provides a parameter builder that can be used by backend personnel who want to manually add or modify search parameters. For example:
java
copy code
@GetMapping("/bs")
public List<User> bs(@RequestParam Map<String, Object> params) {
params = MapUtils.builder(params) // Based on the original parameters
.field(User::getAge, 20, 30).op(Between.class) // add an age interval condition
.field(User::getName).op(StartWith.class) // Modify the operator of the name field to StartWith, and the parameter value is still the parameter passed from the front end
.build();
return beanSearcher. searchList(User. class, params);
}
4) Is there a risk of SQL injection if the front end passes random parameters?
Answer: No, Bean Searcher is a read-only ORM, and it also has object-relational mapping. The parameters passed are the Java attribute names defined in the entity class, not the field names in the database table (the entity class passed by the current end is not Defined field parameters are automatically ignored).
It can also be said that retrieval parameters are decoupled from database tables.
5) Can you pass parameters at will, will it make users get data that they shouldn’t see?
Answer: No, because the request that the user can obtain the most data is the request without parameters. Any parameter that the user tries will only narrow the data range, and it is impossible to expand it.
If you want to do data permissions, return different data according to different users: you can uniformly inject conditions into the permission fields in the parameter filter (the premise is that there must be a data permission field in the entity class, which can be defined in the base class).
6) Although the efficiency has been improved, what about the performance?
Some time ago, many friends read this article and privately asked me about the performance of Bean Searcher. I did a comparison test at home this weekend, and the results are as follows:
-
5~10 times higher than Spring Data Jdbc
-
2~3 times higher than Spring Data JPA
-
1~2 times higher than native MyBatis
-
2~5 times higher than MyBatis Plus
Full report:
-
github.com/troyzhxu/be…
-
gitee.com/troyzhxu/be…
The above tests are based on the H2 memory database
Test the source code address, you can test and compare by yourself:
-
github.com/troyzhxu/be…
-
gitee.com/troyzhxu/be…
7) Which databases are supported?
As long as it supports normal SQL syntax, it is supported. In addition, Bean Searcher has four built-in dialect implementations:
-
A database with the same paging syntax as MySQL, supported by default
-
For databases with the same paging syntax as PostgreSql, just use the PostgreSql dialect
-
For databases with the same paging syntax as Oracle, just use the Oracle dialect
-
For databases with the same paging syntax as SqlServer (v2012 + ), select the SqlServer dialect
If the pagination syntax is original, you only need to implement a method to customize a dialect, refer to: Advanced > SQL Dialect chapter.
Summary
The various differences mentioned above do not mean that MyBatis Plus and Bean Searcher are better or worse, but that their areas of focus are indeed different (BS will not replace MP).
When Bean Searcher was first born, it was specially used to deal with the particularly complex retrieval requirements (as shown in the example above), and is generally used in the management background system.
But after using it, we found that Bean Searcher is also very easy to use for ordinary pagination query interfaces with less complicated retrieval requirements.
The code is much simpler to write than the traditionalORM, only one entity class and a few lines of code inController,Serviceandcode>Daoall disappeared, and the result it returns isVO, no further conversion is needed, and it can be returned directly to the front end.
Use them together in the project, use MyBatis Plus in the transaction, use Bean Searcher in the list retrieval scene, and you will be even more powerful.
In fact, it is easier to integrate Bean Searcher in old projects. Existing single-table entity classes can be reused directly, and VO object classes associated with multiple tables can have powerful retrieval capabilities only by adding corresponding annotations.
Regardless of whether the original ORM of the project is MyBatis, MP, Hibernate, Data Jdbc, etc., or whether the web framework is Spring Boot, Spring MVC, Grails, or Jfinal, as long as it is a java project, it can be used to enable advanced queries for the system .
Add Xiaobian WeChat, reply 40 free prostitution 40 sets of java/spring/kafka/redis/netty tutorials/codes/videos, etc.
Scan the QR code, add me on WeChat, reply: 40 Be careful not to reply indiscriminately That's right, it's not a robot, remember to wait, waiting for good things