First of all, there are many ways to match multiple tables to multiple tables in Excel files (VLOOKUP),
1: Import the Excel file into Mysql or other databases, then merge the two tables into one table, and then use the database to match
2: Copy and paste the contents of the two tables together, save each as a table, and then VLOOUP, this is the most common way
3: Make the matching items of multiple tables that you want to match into a json file, then merge multiple json files, and then use the tables you want to match to match the merged json in turn. This has the advantage of speed Fast, and each is separate
What I am sharing today is the third method. Let me use a small example to illustrate my needs:
First of all, I have three virtual tables, the headers are as follows, the field: [document number] is empty, its value is through the name (assuming that the name is an item), go to the other 3 tables to match, Of course it may not match
Below is the original table (the one I encountered at work was 30 tables!!!)

The following three tables are the tables that I want to match (the actual situation I encountered in my work is more than 30 tables, each with more than 900,000 rows)

So at this point, my needs are already obvious. The amount of table data here is relatively small. The actual situation is also mentioned above. The amount of data is very large. So how to solve it, I divided it into 4 steps
Step 1
Convert all data to csv format first

Code
import os
import time
import pandas as pd # import pandas library
def xlsx2csv():
# read xlsx data
t1 = time. time()
for f in os.listdir("Original table/"):
data = pd.read_excel("Original table/" + f, index_col=0) # Set index_col=0, there will be no serial number in the first column when writing to the file
data.to_csv("csv version" + f + '.csv', encoding='utf-8') # write data to csv file
print("Writing completed......")
t2 = time. time()
print(t2 - t1)
xlsx2csv()
Step 2
Convert matching items to json file
The following line of code is ready to make a dictionary. The first parameter in the tuple is the key, and the second parameter is the value (can be spliced, such as d[1] + d[2], or separated by symbols Convenient cutting, such as d[1] + ‘-‘ + d[2])
list_a.append((d[0], d[0])) 1
In fact, my code can contain repeated keys. If it contains repeated keys, it will put multiple values in the list
For details, you can check this article: python one-key multi-value
The index of my value in the video below is wrong, please ignore it, I changed it later, but the video has been recorded and watched

Code
import csv
import os
from collections import defaultdict
def write_json():
for f in os.listdir("./csvversion/"):
with open("./csvversion/" + f, newline='', encoding='utf-8') as csvfile:
# Read the contents of the CSV file
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# Loop through each row of data in the CSV file
print(f, "loaded")
list_a = [] # The list is used to store tuples of (column A, column B), all data
for d in reader:
# process each row of data
# print(d)
list_a.append((d[0], d[0])) # This will not be translated, add data
d = defaultdict(list) # create a dictionary
for key, value in list_a:
d[key].append(value) # Eliminate the if judgment statement and add a dictionary
with open(f"./json file/{<!-- -->f.split('.')[0]}.json", "w", encoding="utf- 8") as f2:
f2.write(json.dumps(d, ensure_ascii=False)) # write json to prevent garbled characters
write_json()
Step 3
Merge the json file from the previous step.
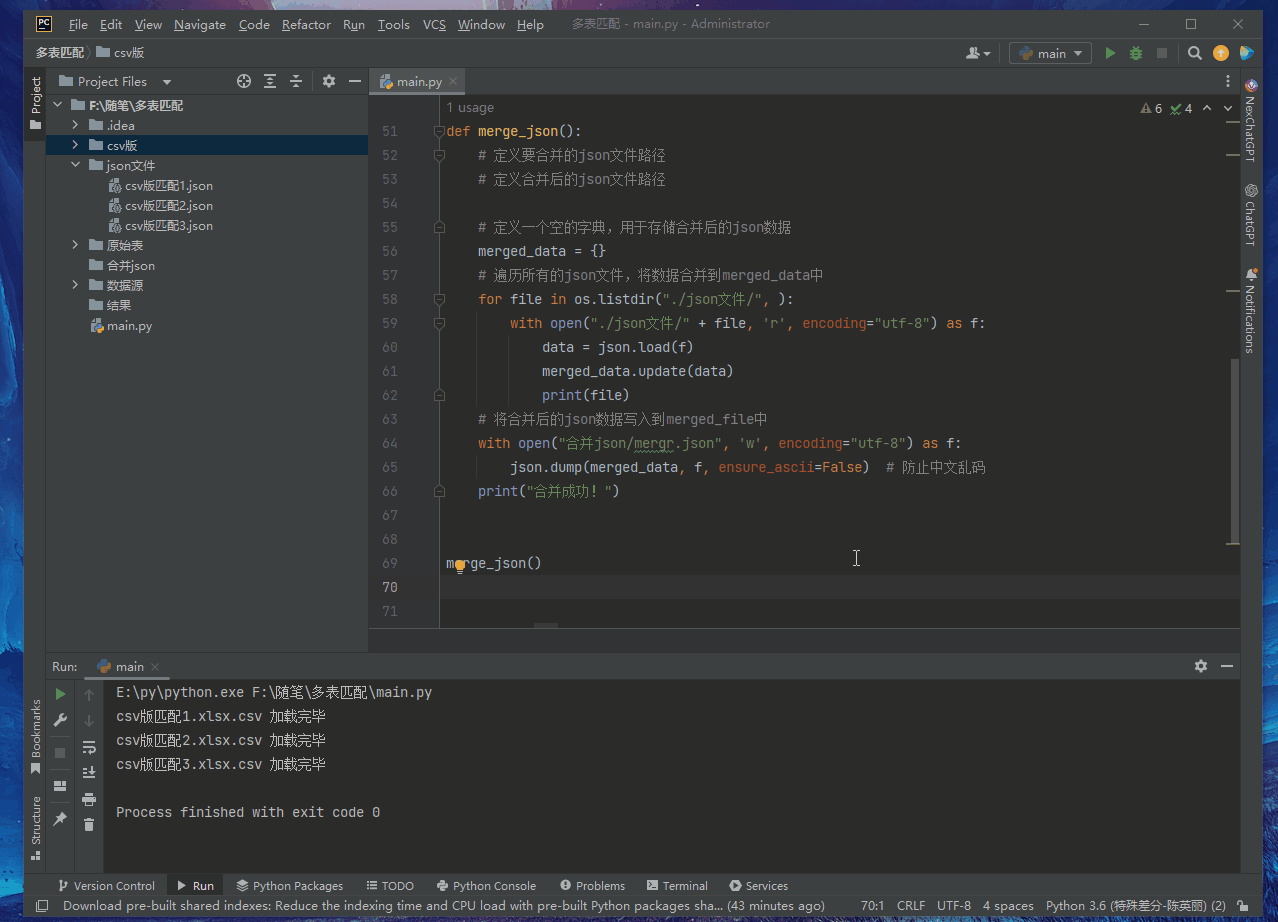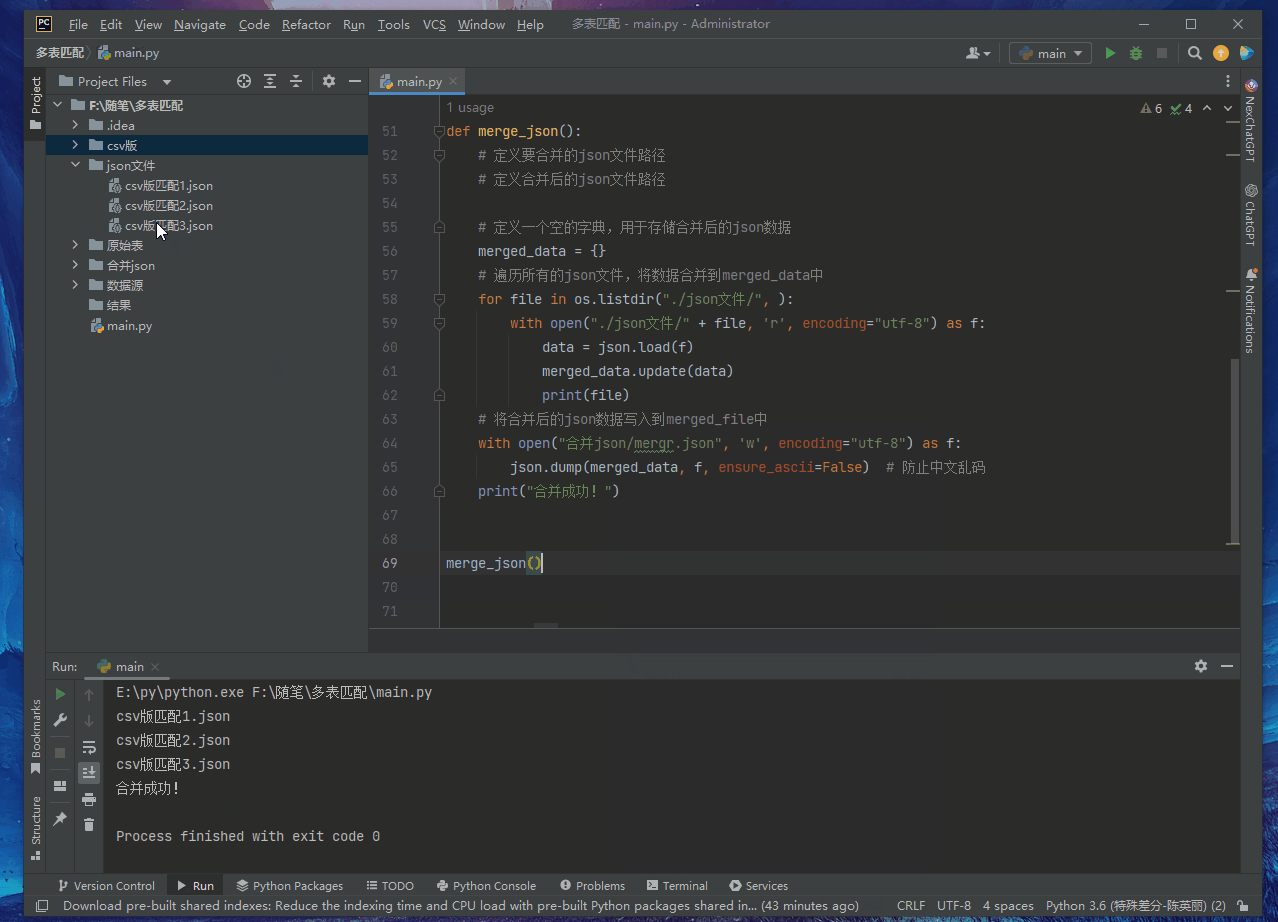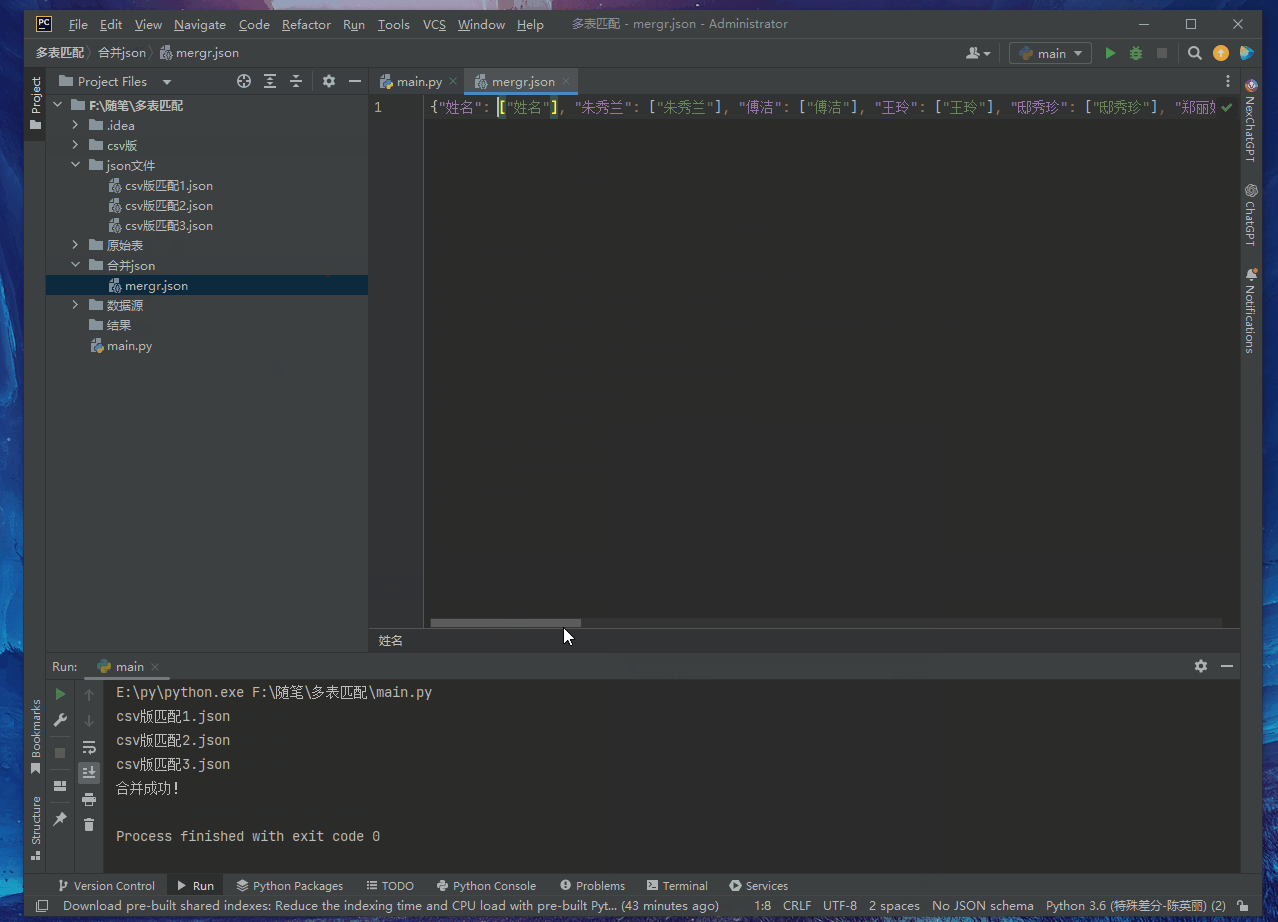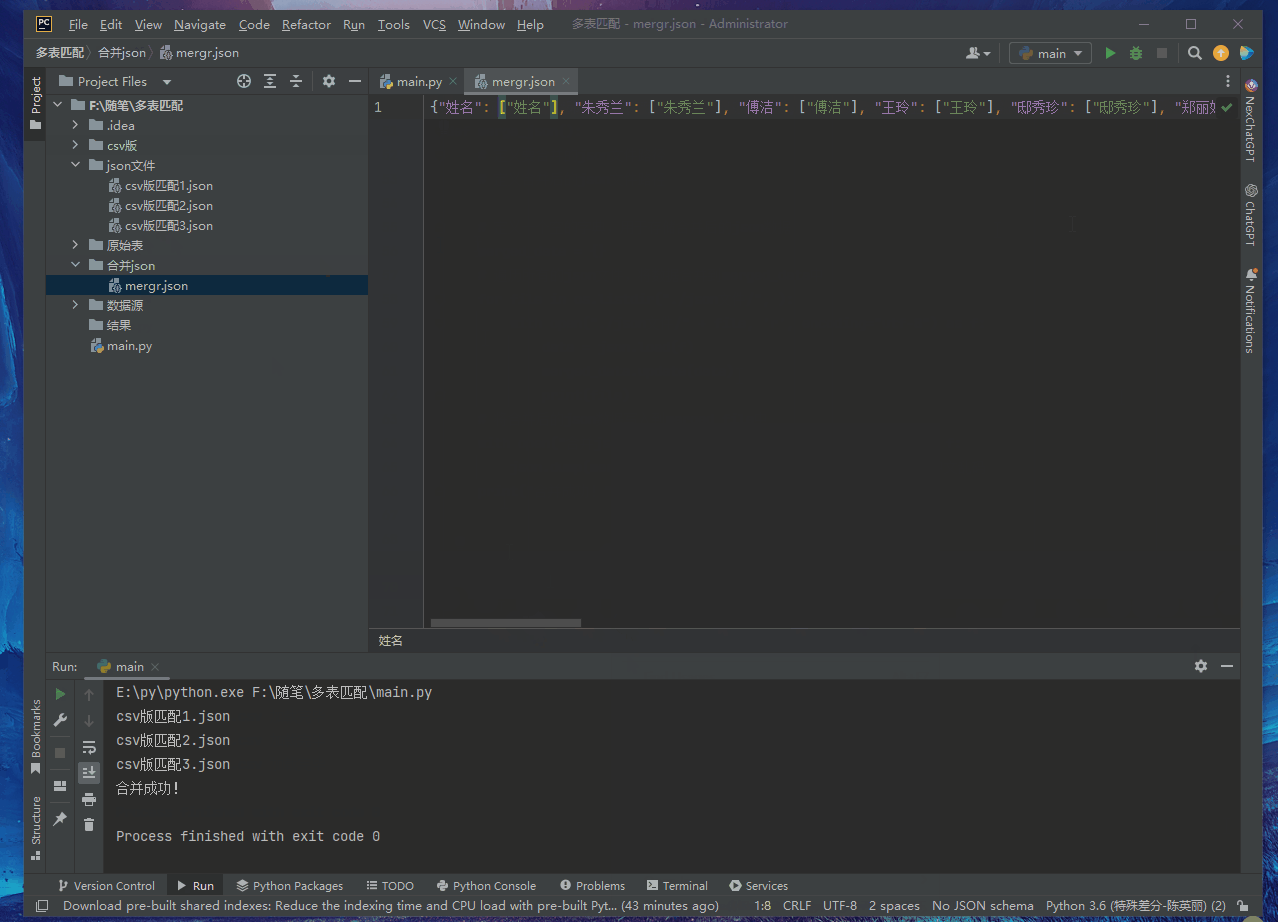
Code
import json
import os
def merge_json():
# Define the path of the json file to be merged
# Define the merged json file path
# Define an empty dictionary for storing the merged json data
merged_data = {<!-- -->}
# Traverse all json files and merge the data into merged_data
for file in os.listdir("./json file/", ):
with open("./json file/" + file, 'r', encoding="utf-8") as f:
data = json. load(f)
merged_data. update(data)
print(file)
# Write the merged json data into merged_file
with open("merge json/mergr.json", 'w', encoding="utf-8") as f:
json.dump(merged_data, f, ensure_ascii=False) # Prevent Chinese garbled characters
print("Merge successfully!")
merge_json()
Step 4, the last step! !
1. Put the successfully converted csv file in the first step into the folder [Data Source] to read
2. Load the newly merged json file
3. Start matching
4. Save

The full version of the code is provided
'''
Author: Xiao Tanhuan for a long time
Mobile: xxxx
'''
# convert xlsx file to csv file
import csv
import json
import os
import time
from collections import defaultdict
import pandas as pd # import pandas library
def xlsx2csv():
# read xlsx data
t1 = time. time()
for f in os.listdir("Original table/"):
data = pd.read_excel("Original table/" + f, index_col=0) # Set index_col=0, there will be no serial number in the first column when writing to the file
data.to_csv("csv version" + f + '.csv', encoding='utf-8') # write data to csv file
print("Writing completed......")
t2 = time. time()
print(t2 - t1)
xlsx2csv()
def write_json():
for f in os.listdir("./csvversion/"):
with open("./csvversion/" + f, newline='', encoding='utf-8') as csvfile:
# Read the contents of the CSV file
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# Loop through each row of data in the CSV file
print(f, "loaded")
list_a = [] # The list is used to store tuples of (column A, column B), all data
for d in reader:
# process each row of data
# print(d)
list_a.append((d[0], d[1])) # This will not be translated, add data
d = defaultdict(list) # create a dictionary
for key, value in list_a:
d[key].append(value) # Eliminate the if judgment statement and add a dictionary
with open(f"./json file/{<!-- -->f.split('.')[0]}.json", "w", encoding="utf- 8") as f2:
f2.write(json.dumps(d, ensure_ascii=False)) # write json to prevent garbled characters
write_json()
def merge_json():
# Define the path of the json file to be merged
# Define the merged json file path
# Define an empty dictionary for storing the merged json data
merged_data = {<!-- -->}
# Traverse all json files and merge the data into merged_data
for file in os.listdir("./json file/", ):
with open("./json file/" + file, 'r', encoding="utf-8") as f:
data = json. load(f)
merged_data. update(data)
print(file)
# Write the merged json data into merged_file
with open("merge json/mergr.json", 'w', encoding="utf-8") as f:
json.dump(merged_data, f, ensure_ascii=False) # Prevent Chinese garbled characters
print("Merge successfully!")
merge_json()
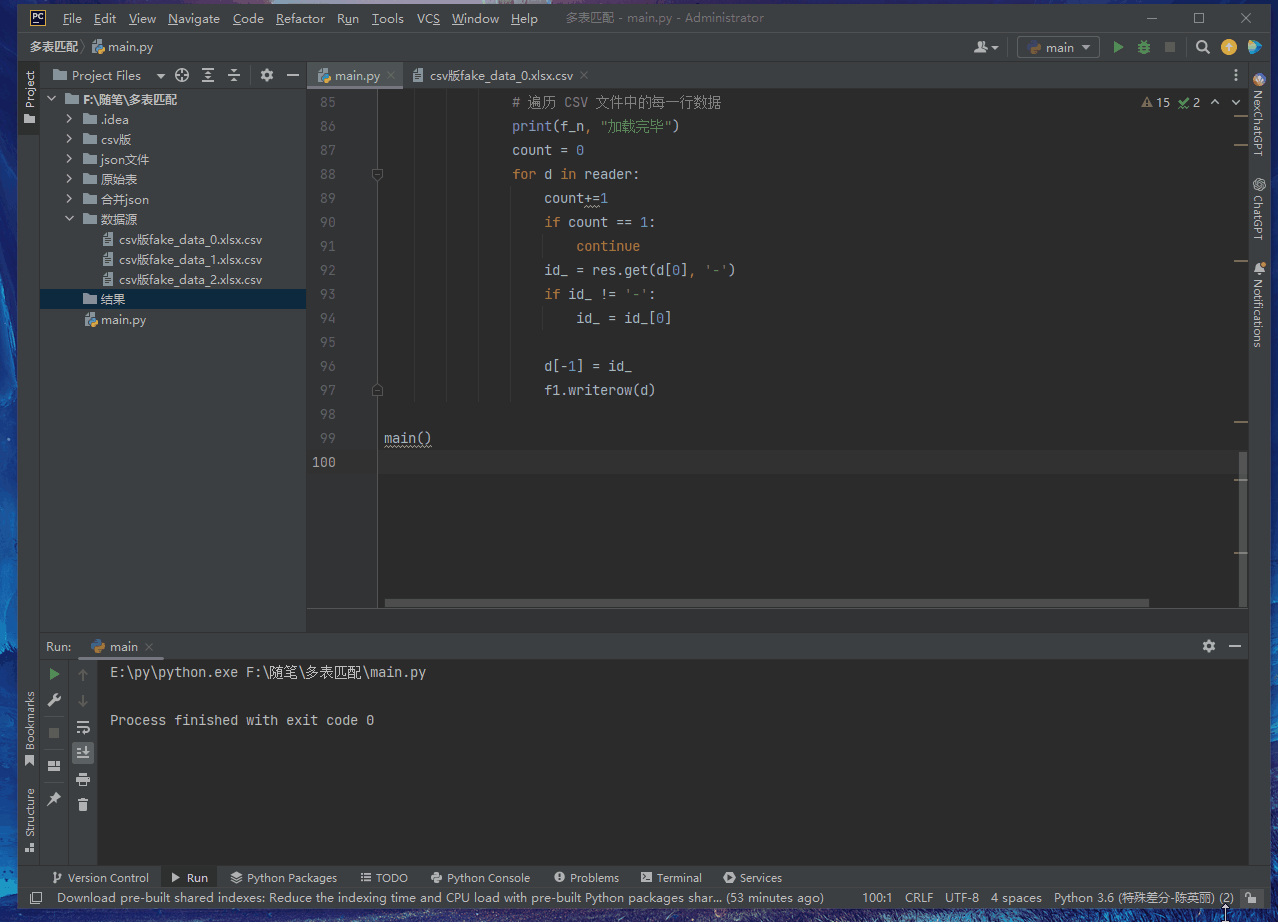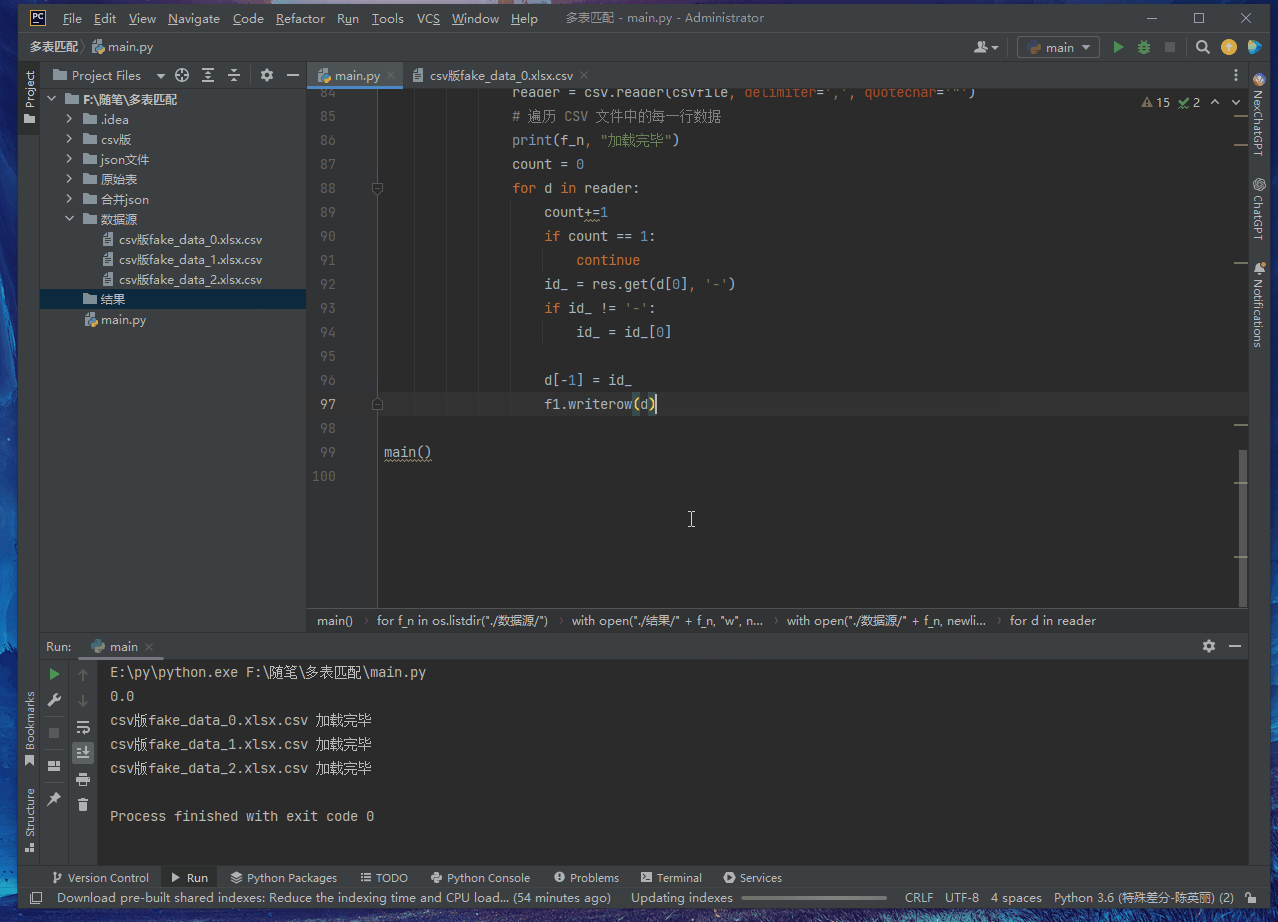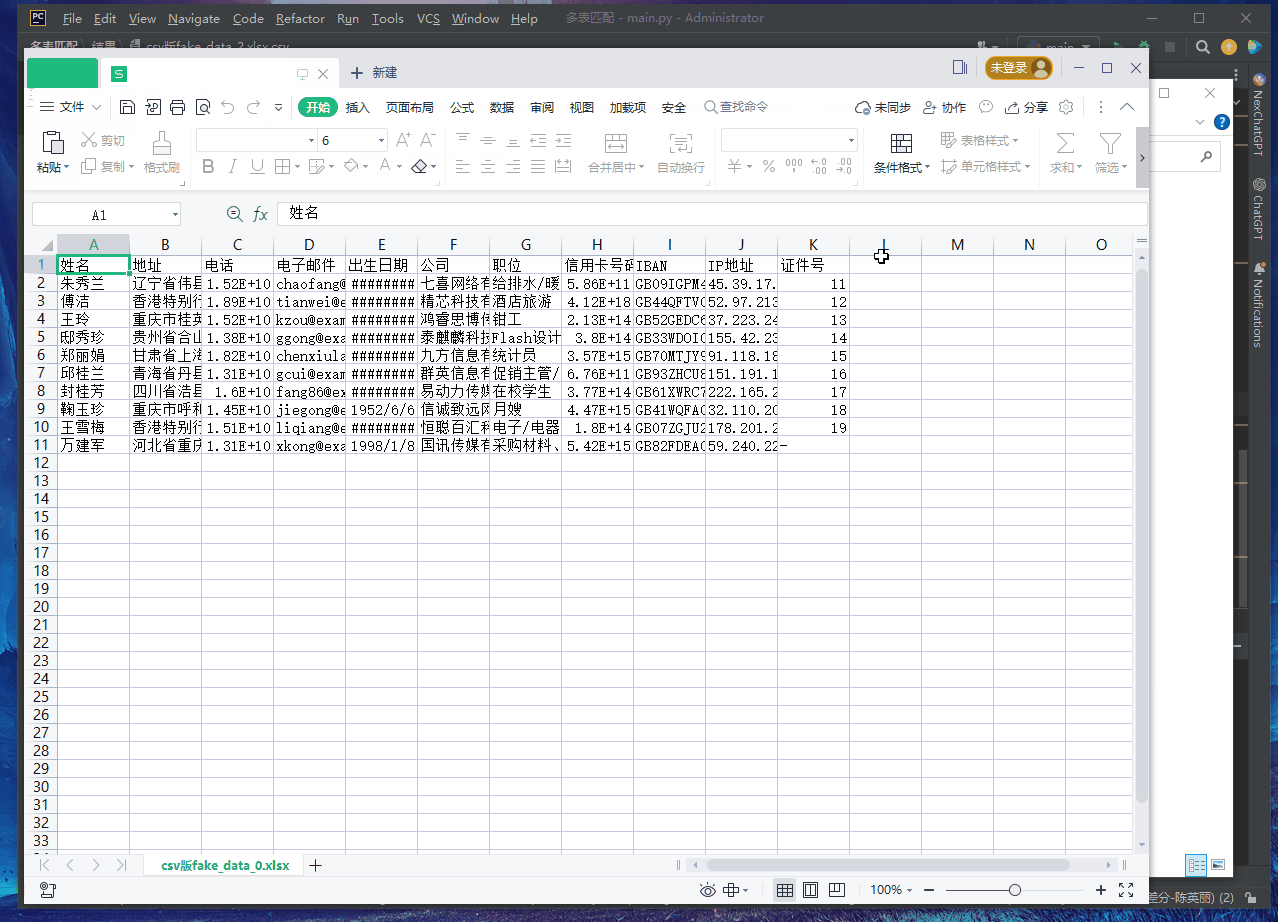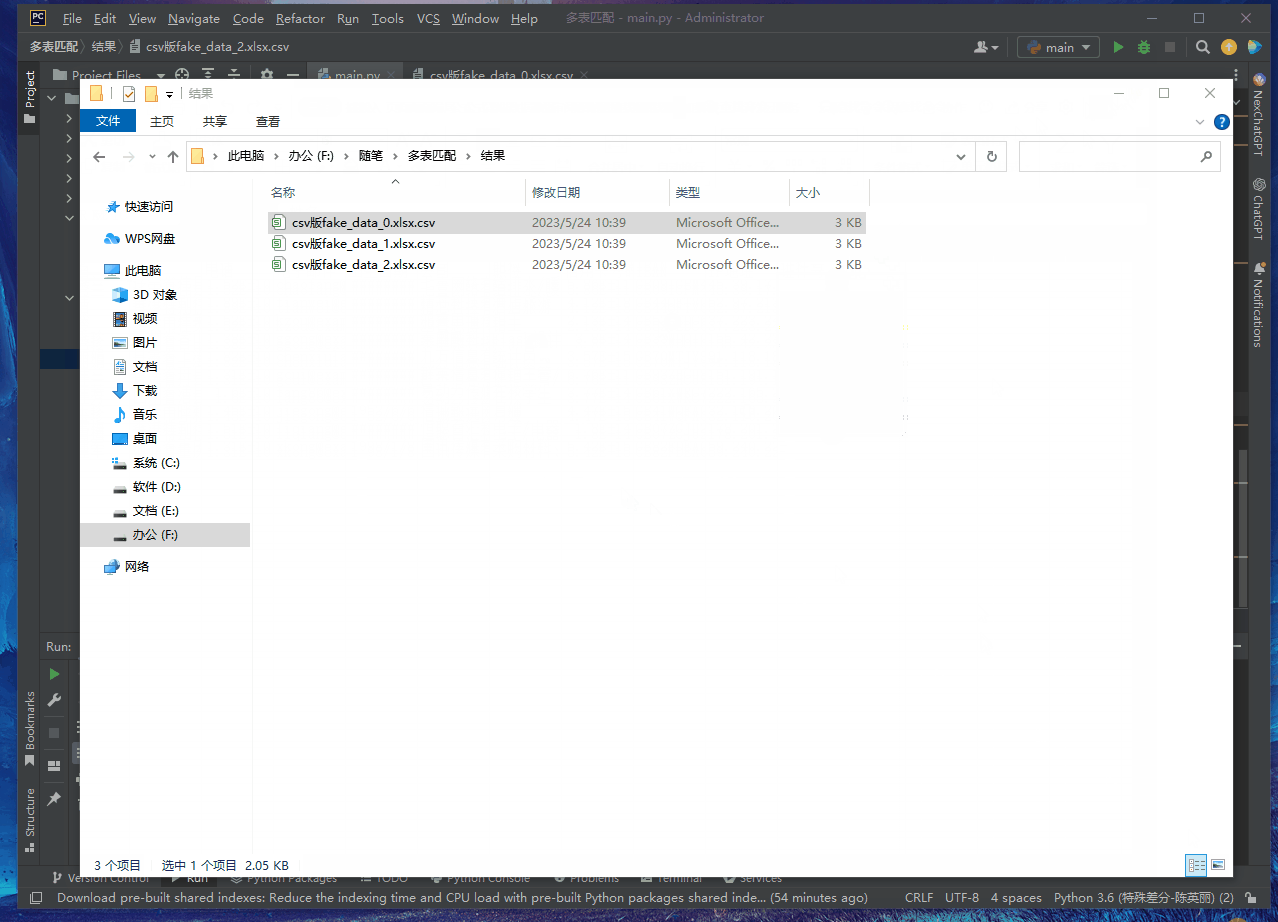
def main():
t1 = time. time()
with open("merge json/mergr.json", "r", encoding="utf-8") as f:
res = json. load(f)
t2 = time. time()
print(t2 - t1)
for f_n in os.listdir("./data source/"):
with open("./result/" + f_n, "w", newline='', encoding="utf-8") as f1:
f1 = csv. writer(f1)
f1.writerow(['name','address','phone','email','date of birth','company','position',\ 'Credit card number','IBAN','IP address','document number'])
with open("./data source/" + f_n, newline='', encoding='utf-8') as csvfile:
# Read the contents of the CSV file
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# Loop through each row of data in the CSV file
print(f_n, "loaded")
count = 0
for d in reader:
count + =1
if count == 1:
continue
id_ = res. get(d[0], '-')
if id_ != '-':
id_ = id_[0]
d[-1] = id_
f1. writerow(d)
main()
This is the small tool shared today, I hope it will be helpful to financial people who face bills and reports all day long! !
A little programmer dedicated to office automation#
I have seen this, follow + like + bookmark = don’t get lost! !
If you want to know more about Python office automation, please pay attention!






