Trie
Trie, also known as dictionary tree or prefix tree, is a tree-shaped data structure for efficient storage and retrieval of strings. Its main feature is to use the common prefix of strings to reduce storage space and improve query efficiency. The following is an introduction to common operations on Tries:
Insertion: Insert a string into the Trie. Starting at the root node, checks the string character by character and acts accordingly based on whether the character exists in the current node’s child nodes. If the character does not exist, a new node is created and linked to the current node’s children.
Deletion: Delete a string from the Trie. Similar to the insert operation, the string is checked character by character and the corresponding node is found. In the deletion operation, we need to pay attention to retaining the structural integrity of the Trie, that is, if after deleting a node, its parent node has no other child nodes and does not represent the prefix of other strings, the parent node needs to be deleted as well.
Search: Search for a string in the Trie. Checks the string character by character, starting at the root node. A string exists in a Trie if all characters are present in the Trie and the node corresponding to the last character marks the end of the string.
Prefix Search: Searches the Trie for all strings with the specified prefix. Starting at the root node, the prefix is checked character by character. If all characters of a prefix are present in the Trie, all strings beginning with that prefix can be found by traversing the children of the Trie.
Count Prefixes (Count Prefixes): Count the number of strings starting with the specified prefix. Similar to prefix search, starting from the root node, the prefix is checked character by character, and the node that reaches the end of the prefix is tracked. Then the child nodes of this node can be traversed to count the number of strings starting with this prefix.
These operations are the basic operations of Trie, and by taking advantage of the characteristics of the Trie data structure, we can perform these operations in constant time, thereby achieving efficient string storage and retrieval. In practical applications, Trie has a wide range of applications in word search, prefix matching, automatic completion, spell checking and other fields.
Example 1:
Select two of the given N integers A1, A2…AN to perform xor (exclusive OR) operation, what is the maximum result obtained?
Input format Input an integer N in the first line Input N integers A1~AN in the second line
Output Format Output an integer representing the answer.
Data range 1≤N≤105 0≤Ai<231
Input example: 3 1 2 3
Sample output: 3
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
?
const int N = 1e5 + 10;
?
int tr[N * 30][2],idx;
int n;
int a[N];
?
void insert(int v)
{
int p = 0;
for(int i = 31; ~i; i --)
{
int c = v >> i & 1;
if(tr[p][c] == 0) tr[p][c] = + + idx;
p = tr[p][c];
}
}
?
int query(int v)
{
int p = 0;
int ans = 0;
for(int i = 31; ~i; i --)
{
int c = v >> i & 1;
if(tr[p][!c])
{
ans + = (1 << i);
p = tr[p][!c];
}
else p = tr[p][c];
}
return ans;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i ++ )
{
cin >> a[i];
insert(a[i]);
}
int ans = -1 << 30;
for(int i = 1; i <= n; i ++ )
{
ans = max(ans ,query(a[i]));
}
cout << ans;
return 0;
}
?
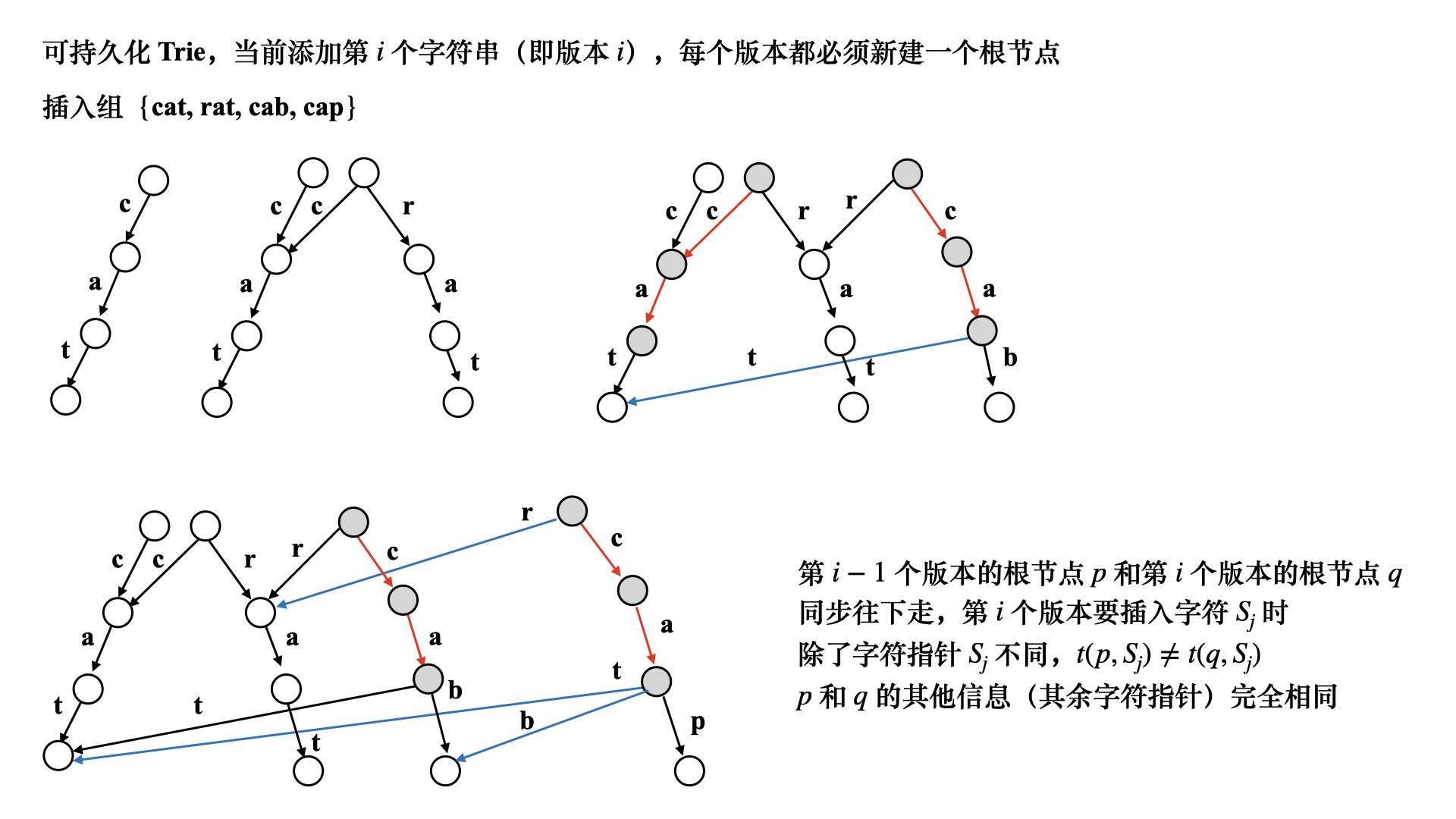
Persistent Trie
Persistible Trie is an extension based on the Trie data structure, which allows us to retain historical versions in Trie, not just operations on the current state. A persistent Trie can efficiently support query and modification operations between different versions.
In the traditional Trie data structure, each time a word is inserted or deleted, the operation will be performed directly on the current Trie, which makes it impossible to go back to the previous state. However, in a persistent Trie, we will use a persistent way to record each version of the Trie and retain all modification operations of each version.
In a persistent Trie, each node contains an array or pointer to child nodes, and each node also records a version number. When an insertion or deletion is required, we create a new node to represent the new version and apply the changes to the new node while leaving the old version unchanged.
In this way, the persistent Trie realizes the ability to query historical versions. We can go back to any version as needed and perform corresponding query operations without affecting the data of other versions.
Persistent Tries play an important role in many applications, such as version management of strings, history records, undo/redo of text editors, etc. It provides an efficient and reliable way to handle scenarios that require time travel of data structures.
It should be noted that a persistent Trie has a certain overhead in time and space, because each version requires additional space to store a copy of the node. Therefore, in practical applications, we need to weigh the pros and cons of time and space according to specific needs, and choose whether to use a persistent Trie.
To sum up, persistent Trie is a Trie data structure extension that can retain historical versions and support backtracking. It provides the ability to query historical states and is suitable for many application scenarios that require time travel of data structures.
Reference: AcWing 256. Maximum XOR Sum – AcWing
example:
Given a sequence a of non-negative integers with initial length N. There are M operations, and there are the following two types of operations: A x: Add operation, which means adding a number x at the end of the sequence, and the length N of the sequence increases by 1 Q l r x: Query operation, you need to find a position p that satisfies l≤ p≤r, so that: a[p] xor a[p + 1] xor … xor a[N] xor x is the largest, and output this maximum value.
Input format The first line contains two integers N, M, meaning as shown in the problem description. The second line contains N non-negative integers, representing the initial sequence A followed by M lines, each line describes an operation, and the format is as described in the title.
Output Format Each query operation outputs an integer representing the answer to the query. Each answer occupies one line.
Data range N,M≤3×105,0≤a[i]≤107
Problem-solving ideas:
1. According to the nature of the xor operation, it can be found that maintaining the XOR and the S array in a way similar to the addition prefix sum is also true
2. The original problem is transformed into the known integer val = s[N] xor x, find a position p (l – 1 <= p <= r - 1), so that s[p] xor val is the largest
3. Restriction 1: p <= r - 1, can be directly maintained with a persistent Trie, and the answer can be found from root[r - 1]
4. Restriction 2: p >= l – 1, maintain the max_id of each point. The meaning is: the maximum subscript i used to update the current point in the current version
(p >= l – 1 is equivalent to the largest i greater than l – 1)
Recursive implementation It is convenient to count max_Id, and readers can experience it by themselves. In fact, every time insert is executed, a new root node will be reopened, which is a new version. And recursively insert each binary bit of s[i]. For all newly inserted nodes, their max_id will be updated to i; if it is not a newly inserted point, directly copy the previous version of the information, the previous version of the information also contains the max_id of the historical version.
In short, when querying a certain version of the trie, all newly inserted points will be updated to i, while the old points will inherit the historical version information
#include <cstring>
#include <algorithm>
using namespace std;
?
const int N = 600010, M = N * 25;
?
int n,m;
int tr[M][2],max_id[M],idx;
int root[N];
int s[N];
void insert(int i, int k, int p, int q)
{
if(k < 0)
{
max_id[q] = i;
return;
}
?
int v = s[i] >> k & 1;
?
if(p) tr[q][v^1] = tr[p][v^1];
//If p exists, directly copy the historical version opposite to the current extended node
tr[q][v] = + + idx;
?
insert(i, k - 1, tr[p][v], tr[q][v]);
max_id[q] = max(max_id[tr[q][0]], max_id[tr[q][1]]);
}
?
int query(int root, int C, int L)
{
int q = root;
?int ans = 0;
for(int i = 23; ~i; i --)
{
int v = C >> i & 1;
//If the opposite node of the current node node
//if node is updated by version >= L
if(max_id[tr[q][!v]] >= L)
{
q = tr[q][!v];
ans += 1 << i;
}
else q = tr[q][v];
}
?
return ans;
}
?
int main()
{
cin >> n >> m;
//0 is also a legal solution
root[0] = + + idx;
max_id[0] = -1;
/*
In a persistent Trie
max_id[q] is used to record the maximum subscript of the string represented by the current node q.
When the value of max_id[q] is -1
Indicates that the node does not represent any string, that is, the node is not a valid node.
In the code, the purpose of max_id[0] = -1 is to initialize the root node as an invalid node
Because the root node does not represent any string.
Thus, in the insert function, when a new node is created,
By initializing max_id[q] to -1, it is ensured that new nodes do not represent any strings.
So initializing max_id[0] to -1 is the right thing to do instead of initializing it to 0.
*/
//23 is because of the data range of 1e7
insert(0, 23, 0, root[0]);
?
for(int i = 1; i <= n; i ++ )
{
int a; cin >> a;
s[i] = s[i - 1] ^ a;
?
root[i] = + + idx;
insert(i, 23, root[i - 1], root[i]);
}
?
for(int i = 1; i <= m; i ++ )
{
char op[2];
scanf("%s", op);
?
if(op[0] == 'A')
{
int x; cin >> x;
n + + ;
s[n] = s[n - 1] ^ x;
root[n] = + + idx;
insert(n, 23, root[n - 1], root[n]);
}
else
{
int l,r,x;
cin >> l >> r >> x;
int val = x ^ s[n];
cout << query(root[r - 1], val, l - 1) << endl;
}
}
return 0;
}