Table of Contents
1 Divide and conquer thinking
2Fork/Join
2.1 Introduction
2.2 Application scenarios
1 Recursive decomposition task
2 Array processing
3 Parallelization Algorithm
4 Big data processing
2.3 Use
2.3.1 ForkJoinPool
Constructor
Task submission method
Compared with ordinary thread pool
2.3.2 ForkJoinTask
call method
2.3.3 Handling recursive tasks
2.3.4 Handling blocking tasks
2.4 Principles
2.4.1 Worker thread
2.4.2 Job theft
1 The idea of divide and conquer
Divide and conquer idea: A problem of size N is decomposed into K sub-problems of size. The sub-problems are independent of each other and have the same properties as the original problem. If you find the solution to the sub-problem, you can get the solution to the original problem.
Steps to divide and conquer thinking:
break down
Solve
merge

2 Fork/Join
2.1 Introduction
Parallel computing framework, used to support the divide-and-conquer task model. Fork corresponds to task decomposition in the divide-and-conquer task model, and Join corresponds to result merging.

2.2 Application Scenario
1 Recursive decomposition task
Sorting, merging, traversing, etc., usually large tasks can be decomposed into several sub-tasks
2 array processing
For sorting, searching, statistics, etc. of a large array, split it into several sub-arrays, process each sub-array in parallel, and finally merge it into a large ordered array.
3 Parallelization Algorithm
Parallel image processing algorithms, parallel machine learning algorithms, etc., split the task into several sub-problems
4 Big Data Processing
Large log file processing, large database query, etc., divide the data into several shards and process each shard in parallel
2.3 Use
Main components: ForkJoinPool, ForkJoinTask
ForkJoinPool: used to manage the execution of tasks
ForkJoinTask: tasks can be divided into smaller
Steps for usage:
1 To build a task, you need to inherit RecursiveAction (no return value) or RecursiveTask (with return value), rewrite the compute() method to implement the execution logic of the task, and finally call invokeAll in the method to start executing the task.
2 Build a forkJoin thread pool and call forkJoin.invoke() to submit the task
2.3.1 ForkJoinPool
Threads used to manage Fork/Join tasks
Constructor
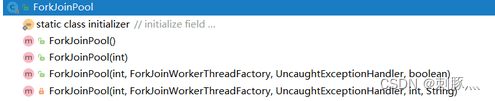
int parallelism: Specifies the parallelism level and determines the number of worker threads. If not set, use Runtime.getRuntime().availableProcessors() to set the parallelism level.
ForkJoinWorkerThreadFactory: When creating a thread, it is created through this factory. If it is not set, the default DefaultForkJoinWorkerThreadFactory is used to be responsible for the creation of the thread.
UncaughtExceptionHandler: Specify the exception handler. When luck goes wrong, it will be handled by the set handler.
asyncMode: The working mode of the queue, true=first in first out, false=last in first out
Task submission method

Comparison with ordinary thread pool
Work stealing algorithm: Ordinary thread pools are implemented using task queues; after threads in FockJoinPool have completed executing tasks, they can obtain tasks from the queues of other threads and execute them.
Decomposition and merging of tasks: ForkJoinPool can decompose a large task into multiple small tasks, execute these small tasks in parallel, and finally merge the results; while ordinary threads can only execute them one by one in the order of submitted tasks.
Number of worker threads: ForkJoinPool automatically sets the number of worker threads based on the number of CPU cores in the current system to maximize the CPU performance advantage; ordinary threads need to manually set the thread pool size, and its rationality must be considered
Task type: ForkJoinPool is suitable for performing large-scale task parallelization; ordinary thread pool is suitable for performing some short tasks, such as processing requests
2.3.2 ForkJoinTask
Define the basic interface for performing tasks
Implement your own task class by inheriting the ForkJoinTask class, and rewrite the compute() method to define the execution logic of the task. When implementing, you only need to inherit its subclass:
RecursiveAction: recursively executes but does not need to return a result
RecursiveTask: The results that need to be returned for recursive execution
CountedCompleter: Custom hook function triggered after the task completes execution.
Calling method
fork() —- Submit task
Submit the task to the thread pool where the current task is running; the current thread is of type ForkJoinWorkerThread and will be put into the work queue of this thread, otherwise it will be put into the work queue of the common thread pool.
join() —- Get task execution results
Used to obtain the execution result of the task; when calling the method, the current thread will be blocked until the corresponding subtask completes running and returns the result.
2.3.3 Processing recursive tasks
public class Fibonacci extends RecursiveTask<Integer> {
final int n;
public Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 2);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 1);
return f2.compute() + f1.join();
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
Fibonacci fibonacci = new Fibonacci(100);
Integer result = pool.invoke(fibonacci);
System.out.println(result);
}
}
Problems with the above code: it will lead to long program running time, stack overflow when the recursion depth is too large, etc.
When using ForkJoinPool to process recursive tasks, special consideration should be given to recursion depth and task granularity to avoid memory consumption caused by scheduling.
2.3.4 Handling blocking tasks
1 Prevent thread starvation: When a thread is executing a blocking task, it will wait for the task to be completed. If no other thread can steal the task, the thread will remain blocked; in ForkJoinPool, avoid submitting a large number of blocking tasks (use this thread The purpose of the pool is to divide and conquer, and a large number of blocking tasks will reduce the use value and performance of ForkJoinPool)
2 Use a specific thread pool: ThreadPoolExecutor, use it as the executor of ForkJoinPool, let it perform blocking tasks; ForkJoinPool performs non-blocking tasks
3 Do not block the working thread: If you must submit a blocking task, make sure the task does not block the working thread, otherwise it will cause the performance of the entire thread pool to degrade. To avoid this situation, you need to submit the blocking task to a new thread pool, or use Asynchronous programming tools such as CompletableFuture to handle blocking tasks
public class BlockingTaskDemo {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(5);
return "xxx";
} catch (InterruptedException e) {
return null;
}
}, pool);
try {
String result = future.get();
System.out.println(result);
} catch (Exception e) {
pool.shutdown();
}
}
}
2.4 Principle
There are multiple task queues inside ForkJoinPool (one work thread corresponds to one work queue). When the invoke and submit methods are called to submit a task, the task will be submitted to the task queue according to certain routing rules. Subtasks are created during task execution. Then Submit subtasks to the task queue as well
Even if the thread task queue is empty, it can still obtain the tasks of other threads and execute them through the “Task Stealing” mechanism
2.4.1 Worker Thread
ForkJoinWorkerThread is a thread specifically used for execution in ForkJoinPool. When this thread is created, it will register a WorkQueue to ForkJoinPool, which is specifically used to store its own tasks Queue; stored in odd bits of WorkQueue[]
The WorkQueue[] array is used to store the WorkQueue of all threads; the even-numbered positions store tasks submitted by external threads (this is why CompletableFuture can be placed in the ForkJoinPool thread pool, and the WorkQueue[] in the even-numbered positions saves the general logic of the thread pool)

In ForkJoinPool, only the odd-numbered bits of WorkQueue[] belong to ForkJoinWorkerThread, and the stealing task is also stolen at this position.
2.4.2 Work theft
Allow idle threads to get tasks from odd bits of WorkQueue[]
push, pop: current thread operation; poll: steal the WorkQueue of other threads