Pyspark
Note: If you think the blog is good, don’t forget to like and collect it. I will update the content related to artificial intelligence and big data every week. Most of the content is original, Python Java Scala SQL code, CV NLP recommendation system, etc., Spark Flink Kafka, Hbase, Hive, Flume, etc. are all pure dry goods, and the interpretation of various top conference papers makes progress together.
Continue to share Pyspark_SQL5 with you today
#博学谷IT Learning Technical Support
Article directory
- Pyspark
- foreword
- 1. Complete the UDF function based on Pandas
- 2. Implement custom UDAF function based on Pandas
- 3. Comprehensive case of implementing custom UDF and UDAF based on Pandas
- Summarize
Foreword
Continue to share Pyspark_SQL5 today.
1. Complete UDF function based on Pandas
Requirements for custom Python functions: SeriesToSeries
import pandas as pd
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import Window as win
if __name__ == '__main__':
print("spark pandas udf")
spark = SparkSession.builder.appName("spark pandas udf").master("local[*]")\
.config('spark.sql.shuffle.partitions', 200) \
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)
schema = StructType(). add("a", IntegerType()) \
.add("b", IntegerType())
df = spark.createDataFrame([
(1, 5),
(2, 6),
(3, 7),
(4, 8),
], schema=schema)
df. createTempView("t1")
# For DSL format
@F.pandas_udf(returnType=IntegerType())
def sum_ab(a: pd.Series, b: pd.Series) -> pd.Series:
return a + b
# For SQL format
spark.udf.register("sum_ab", sum_ab)
spark.sql("""
select
*,
sum_ab(a,b) as sum_ab
from t1
""").show()
df. select("*", sum_ab("a", "b"). alias("sum_ab")). show()
spark. stop()

2. Implement custom UDAF function based on Pandas
Requirements for custom Python functions: SeriesTo scalar
import pandas as pd
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import Window as win
if __name__ == '__main__':
print("spark pandas udaf")
spark = SparkSession.builder.appName("spark pandas udaf").master("local[*]")\
.config('spark.sql.shuffle.partitions', 200) \
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)
schema = StructType(). add("a", IntegerType()) \
.add("b", IntegerType())
df = spark.createDataFrame([
(1, 5),
(2, 6),
(3, 7),
(4, 8),
], schema=schema)
df. createTempView("t1")
df. show()
# For DLS format
@F.pandas_udf(returnType=FloatType())
def avg_column(a: pd.Series) -> float:
return a. mean()
# For SQL format
spark.udf.register("avg_column", avg_column)
spark.sql("""
select
*,
avg_column(a) over(order by a) as a_avg,
avg_column(b) over(order by b) as b_avg
from t1
""").show()
df. select("*",
avg_column("a").over(win.orderBy("a")).alias("a_avg"),
avg_column("b").over(win.orderBy("b")).alias("b_avg")).show()
spark. stop()

3. Comprehensive case of implementing custom UDF and UDAF based on Pandas
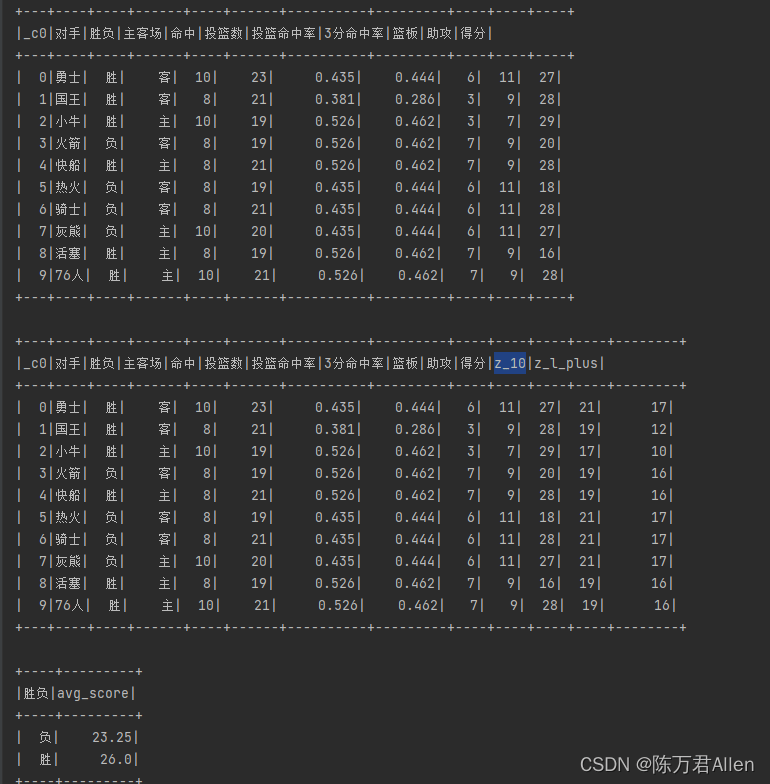
data:
_c0,opponent,win,home and away,hits,number of shots,shooting percentage,3-point shooting percentage,rebounds,assists,scoring
0, Warriors, Win, Guest, 10, 23, 0.435, 0.444, 6, 11, 27
1, king, win, guest, 8, 21, 0.381, 0.286, 3, 9, 28
2,Mavericks,Win,Lord,10,19,0.526,0.462,3,7,29
3, rocket, negative, guest, 8, 19, 0.526, 0.462, 7, 9, 20
4, Clippers, Win, Main, 8, 21, 0.526, 0.462, 7, 9, 28
5, heat, negative, off, 8, 19, 0.435, 0.444, 6, 11, 18
6, cavaliers, negative, guest, 8, 21, 0.435, 0.444, 6, 11, 28
7, Grizzlies, Negative, Main, 10, 20, 0.435, 0.444, 6, 11, 27
8,pistons,win,main,8,19,0.526,0.462,7,9,16
9, 76 people, win, master, 10, 21, 0.526, 0.462, 7, 9, 28
# Requirement 1: Assist column + 10
# Requirement 2: Number of rebounds + assists
# Requirement 3: The average score of the statistical outcome
import pandas as pd
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import Window as win
if __name__ == '__main__':
print("spark pandas udf example")
spark = SparkSession.builder.appName("spark pandas udf example").master("local[*]")\
.config('spark.sql.shuffle.partitions', 200) \
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)
df = spark.read.format("csv")\
.option("header", True).option("inferSchema", True) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/data.csv")
df. createTempView("t1")
df. printSchema()
df. show()
# Requirement 1: Assist column + 10
# Requirement 2: Number of rebounds + assists
# Requirement 3: The average score of the statistical outcome
@F.pandas_udf(returnType=IntegerType())
def method01(score: pd.Series) -> pd.Series:
return score + 10
@F.pandas_udf(returnType=IntegerType())
def method02(score1: pd.Series, score2: pd.Series) -> pd.Series:
return score1 + score2
@F.pandas_udf(returnType=FloatType())
def method03(score: pd.Series) -> float:
return score. mean()
spark.udf.register("method01", method01)
spark.udf.register("method02", method02)
spark.udf.register("method03", method03)
spark.sql("""
select
*,
method01(`Assists`) as z_10,
method02(`assists`,`rebounds`) as z_l_plus
from t1
""").show()
#
spark.sql("""
select
`Outcome`,
method03(`score`) as avg_score
from t1
group by `winner`
""").show()
df. select("*",
method01("Assists").alias("z_10"),
method02("Assist", "Rebound").alias("z_l_plus")
).show()
df.select("win or lose", "score").groupBy("win or lose").agg(
method03("score").alias("avg_score")
).show()
spark. stop()
Summary
Today I mainly share pandas UDF and UDAF with you.