The article comes from the column of Wang Zheng, a former Google engineer at Geek Time.
The query efficiency of hash tables cannot be generally said to be O(1). It is related to hash functions, load factors, hash collisions, etc. If the hash function is poorly designed or the load factor is too high, it may increase the probability of hash conflicts and reduce query efficiency.
In extreme cases, some malicious attackers may use carefully constructed data to cause all data to be hashed into the same slot after passing through the hash function. If we use a linked list-based conflict resolution method, then at this time, the hash table will degenerate into a linked list, and the query time complexity will degenerate from O(1) to O(n).
If there are 100,000 pieces of data in the hash table, the query efficiency of the degraded hash table will drop by 100,000 times. This may cause the system to be unable to respond to other requests because the query operation consumes a large amount of CPU or thread resources, thereby achieving the purpose of a denial of service attack (DOS). This is the basic principle of hash table collision attack.
Question: How to design an industrial-grade hash table that can cope with various abnormal situations, avoid a sharp decline in hash table performance in the case of hash conflicts, and resist hash collision attacks?
How to design a hash function?
The quality of the hash function design determines the probability of hash table collisions and directly determines the performance of the hash table.
First, the design of the hash function cannot be too complex. An overly complex hash function will inevitably consume a lot of calculation time, which will indirectly affect the performance of the hash table.
Second, the values generated by the hash function should be as random and evenly distributed as possible. In this way, hash conflicts can be avoided or minimized. Even if a conflict occurs, the data hashed into each slot will be relatively even, and there will not be a particularly large amount of data in a certain slot.
In student sports meets, the last two digits of the entry number are used as the hash value. The hash function processes mobile phone numbers. The first few digits of the mobile phone number are very likely to be repeated, and the last few digits are more random. The last four digits of the mobile phone number can be used as the hash value. This method of designing hash functions is generally called the “data analysis method”.
How to implement the spell check function in Word. The hash function can be designed like this: add the ASCII code value of each letter in the word with “carry”, and then calculate the remainder and modulo the size of the hash table as the hash value. For example, for the English word nice, the hash value converted by the hash function is:
hash("nice")=(("n" - "a") * 26*26*26 + ("i" - "a")*26*26 + ("c" - "a")*26 + ("e"-"a")) / 78978
The design methods of hash functions include direct addressing method, square-centering method, folding method, and random number method, which need to be understood.
What should I do if the load factor is too large?
The larger the load factor, the more elements there are in the hash table and the fewer free positions, and the greater the probability of hash conflict. Not only does the process of inserting data require multiple searches or a long chain, the search process will also become very slow.
Dynamic hash table, data collection changes frequently.
For hash tables, when the load factor is too large, dynamic expansion can be performed, a larger hash table can be reapplied, and the data can be moved to this new hash table. The load factor is also halved.
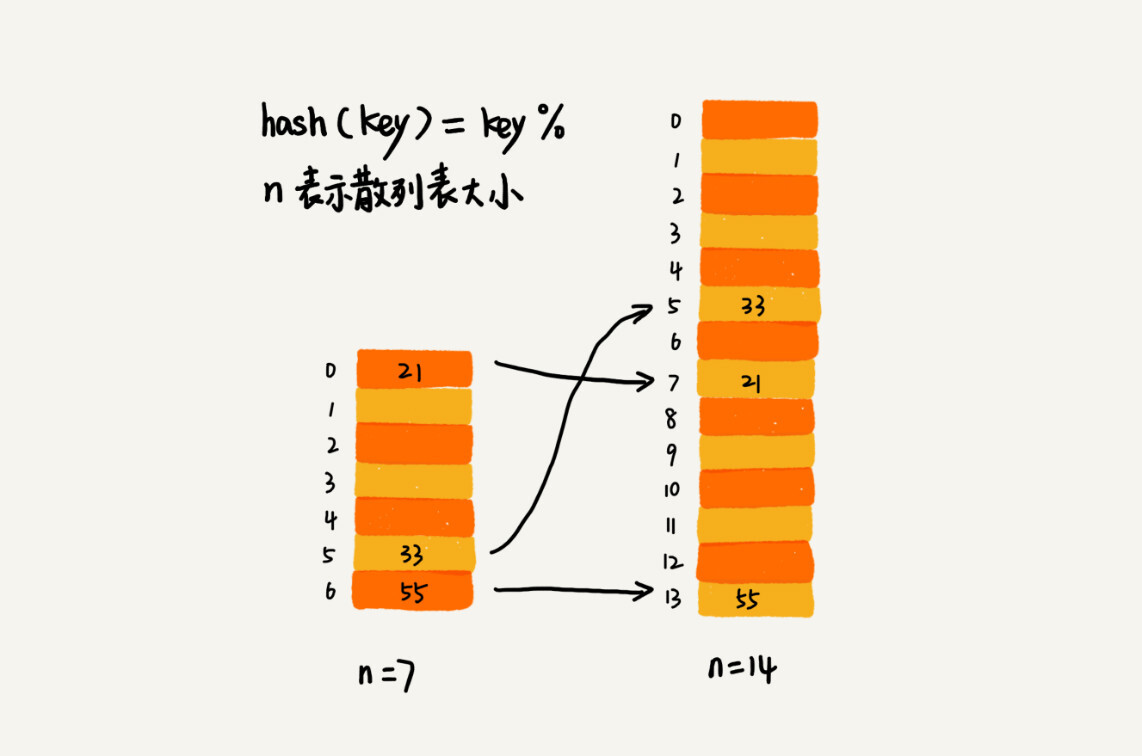
For array expansion, data movement operations are relatively simple. However, for the expansion of the hash table, the data movement operation is much more complicated. Because the size of the hash table has changed and the storage location of the data has also changed, we need to recalculate the storage location of each data through the hash function.
As shown in the figure below, in the original hash table, the element 21 was originally stored at the position with subscript 0. It is moved to the new hash table and stored at the position with subscript 7.
Needs review: The time complexity of dynamically expanding data structures such as arrays and stacks.
Insert a piece of data:
- Best: O(1)
- Worst case: The hash factor is too high, start expansion, re-apply for memory space, recalculate the hash position, move data, the time complexity is O(n)
- Average: In the case of equal sharing, the time complexity is close to the best case, which is O(1)
If memory is tight, for dynamic hash tables, as data is deleted, there will be more and more free space. We can start dynamic scaling after the load factor is less than a certain value.
The loading factor threshold needs to be chosen appropriately. If it is too large, it will cause too many conflicts; if it is too small, it will cause serious waste of memory.
How to avoid inefficient expansion?
Problem: When the load factor has reached the threshold, it needs to be expanded before data is inserted. At this time, inserting data will become very slow or even unacceptable.
For example, if the current size of the hash table is 1GB and you want to expand it to twice the original size, you need to recalculate the hash value of the 1GB data and move it from the original hash table to the new hash table. This sounds like Very time consuming!
If our business code directly serves users, although in most cases the operation of inserting a piece of data is very fast, a very few insert operations that are very slow will crash the user. At this time, the “One-time” expansion mechanism is not appropriate.
Solution: Intersperse the expansion operation during the insertion operation and complete it in batches. When the load factor reaches the threshold, we only apply for new space, but do not move the old data to the new hash table.

Through such an amortization method, the cost of one-time expansion is evenly spread over multiple insertion operations, thus avoiding the situation where one-time expansion takes too much time. In this implementation, the time complexity of inserting a piece of data is O(1) in any case.
How to choose a conflict resolution?
There are two main solutions to hash conflicts, the open addressing method and the linked list method. Both solutions are very commonly used in actual software development. For example, LinkedHashMap in Java uses the linked list method to resolve conflicts, and ThreadLocalMap uses the open addressing method of linear detection to resolve conflicts. What are the advantages and disadvantages of these two conflict resolution methods, and what scenarios are they suitable for?
1. Open addressing method
Advantages of open addressing method:
The data in the hash table are stored in arrays, which can effectively use the CPU cache to speed up queries. Moreover, the hash table implemented by this method is relatively simple to serialize. The linked list method contains pointers and is not so easy to serialize. What is data structure serialization? How to serialize? Why serialize?
Disadvantages of open addressing method:
The open addressing method resolves conflicting hash tables. Deleting data is troublesome and requires special marking of deleted data. In the open addressing method, all data is stored in an array, and conflicts are more costly than in the linked list method. Therefore, for hash tables that use open addressing to resolve conflicts, the upper limit of the load factor cannot be too large. This also causes this method to waste more memory space than the linked list method.
Summary: When the amount of data is relatively small and the load factor is small, the open addressing method is suitable. This is the reason why ThreadLocalMap in java uses open addressing method to resolve hash conflicts.
2. Linked list method
The linked list method has higher memory utilization than the open addressing method. Because linked list nodes can be created when needed, there is no need to apply in advance like open addressing method. In fact, this is where linked lists are better than arrays.
The open addressing method is only applicable when the load factor is less than 1. When it is close to 1, there may be a large number of hash conflicts, resulting in a large number of detection, re-hashing, etc., and the performance will drop a lot. But for the linked list method, as long as the value of the hash function is random and uniform, even if the loading factor becomes 10, it is only the length of the linked list. Although the search efficiency has decreased, it is still much faster than sequential search.
Because linked lists need to store pointers, the storage of relatively small objects (the memory footprint of large object pointers can be ignored) consumes more memory, and may double the memory consumption. The nodes in the linked list are scattered in the memory and are not continuous, so they are not friendly to the CPU cache. This aspect also affects the execution efficiency.
A more efficient hash table can be achieved by slightly modifying the linked list method. We transform the linked list in the linked list method into other efficient dynamic data structures, such as skip lists and red-black trees. In this way, even if a hash conflict occurs, in extreme cases, all data is hashed into the same bucket, and the search time of the final degraded hash table is only O(logn). This effectively avoids the hash collision attack mentioned earlier.

Summary: The hash conflict processing method based on linked lists is more suitable for hash tables that store large objects and large amounts of data. Compared with open addressing, it is more flexible and supports more optimization strategies, such as using red-black trees instead of linked lists.
Example analysis of industrial-grade hash tables
HashMap in java
1.Initial size
The default initial size of HashMap is 16. Of course, this default value can be set. If you know the approximate amount of data in advance, you can modify the default initial size to reduce the number of dynamic expansions, which will greatly improve the performance of HashMap.
2. Loading factor and dynamic expansion
The default maximum load factor is 0.75. When the number of elements in the HashMap exceeds 0.75*capacity (the capacity of the hash table), expansion will be started, and each expansion will be twice the original size.
3. Hash conflict resolution
The bottom layer of HashMap uses the linked list method to resolve conflicts. Even if the load factor and hash function are designed reasonably, the zipper will inevitably be too long. Once the zipper is too long, it will seriously affect the performance of HashMap.
Therefore, in JDK1.8 version, in order to further optimize HashMap, red-black trees were introduced. When the length of the linked list is too long (more than 8 by default), the linked list is converted into a red-black tree, using the characteristics of the red-black tree to quickly add, delete, modify, and query to improve the performance of HashMap. When the number of red-black tree nodes is less than 8, the red-black tree will be converted into a linked list. Because when the amount of data is small, the red-black tree needs to maintain balance. Compared with the linked list, the performance advantage is not obvious.
4. Hash function
The hash function pursues simplicity, efficiency, and even distribution.
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & amp; (capitity -1); //capicity represents the size of the hash table
}
hashCode() returns the hash code of the java object. For example, the hashCode() of a String type object is as follows:
public int hashCode() {
int var1 = this.hash;
if(var1 == 0 & amp; & amp; this.value.length > 0) {
char[] var2 = this.value;
for(int var3 = 0; var3 <this.value.length; + + var3) {
var1 = 31 * var1 + var2[var3];
}
this.hash = var1;
}
return var1;
}
Answer opening
How to design an industrial-grade hash function?
Think first: What is an industrial-grade hash table? What characteristics should an industrial-grade hash table have?
According to the hashing knowledge that has been learned, there should be the following requirements:
- Supports fast query, insertion, and deletion operations
- The memory usage is reasonable and no excessive memory space is wasted.
- The performance is stable, and in extreme cases, the performance of the hash table will not degrade to an unacceptable level.
How to do it?
- Design a suitable hash function
- Define load factor thresholds and design dynamic expansion strategies
- Choosing the appropriate hash collision resolution
Thinking
Which data types in Java are implemented based on hash tables? How to design hash function? In what ways are hash conflicts resolved? Does it support dynamic expansion?