Hello everyone, the editor is here to answer the following questions for you, how to use python to proofread text, and the shortcut keys for adjusting alignment in python. Now let us take a look!
Use Python to process Word files
- Install the external module python-docx
pip install python-docx
1. View Word file structure from Python
In the python-docx module, the Word file structure is divided into 3 layers:
- Document: The highest level, representing the entire Word file.
- Paragraph: A Word file consists of many paragraphs. In Python, the definition of the entire file is Document, and the definition of these paragraphs is the Paragraph object. Jiangsu Deputy Senior Professional Title Thesis Journal Requirements. In Python, a paragraph represents a
Paragraph object, all paragraphs exist as a list of Paragraph objects. - Run: Things to consider in Word files include font size, font style, color, etc., which are collectively called styles. A Run object refers to consecutive text of the same style in the Paragraph object. If the style of the text changes, Python will represent it with a new Run object.
2. Read the content of Word file
- Read simple word file
# author:mlnt
#createdate:2022/8/15
import docx #Import docx module
# 1. Create docx object
document = docx.Document('test.docx')
# 2. Obtain the number of Paragraph and Run
# Use the len() method to obtain the number of Paragraphs
paragraph_count = len(document.paragraphs)
print(f'Number of paragraphs: {paragraph_count}')
for i in range(0, paragraph_count):
# Get the number of Paragraph Runs
paragraph_run_count = len(document.paragraphs[i].runs) # i is the Paragraph number
print(document.paragraphs[i].text) #Print Paragraph content
print(document.paragraphs[i].runs[i].text) # Print the i-th Run content of the i-th paragraph
def getFile(filename):
"""Reading files and moderately editing files"""
document = docx.Document(filename) # Create a Word file object
content = []
for paragraph in document.paragraphs:
print(paragraph.text) # Output the Paragraph content read from the file
content.append(paragraph.text) # Combine each paragraph into a list
return '\\
\\
'.join(content) # Convert the list into a string and output it on alternate lines
print(getFile('test.docx'))
# store file
document.save('out_test.docx') # Copy the file to a new file
test.docx: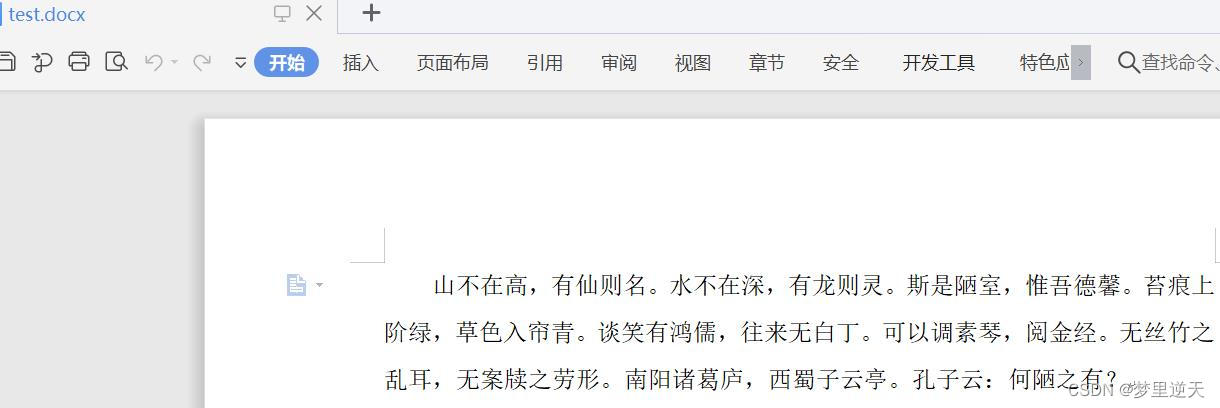
out_test.docx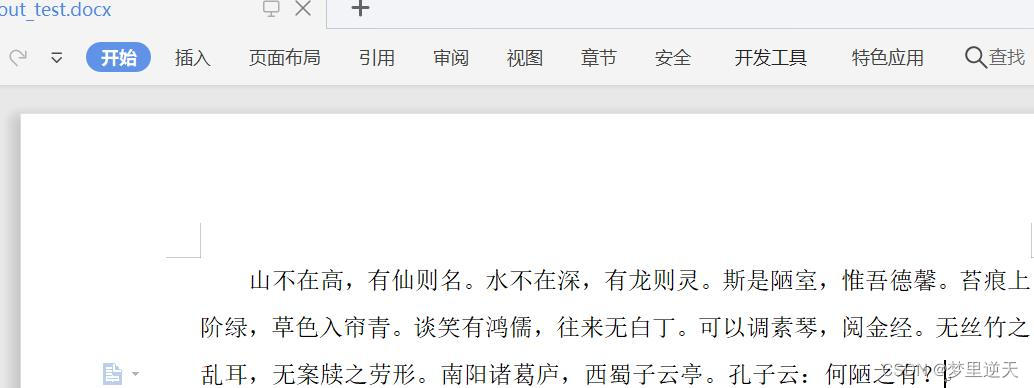
- Read the content of a word document containing tables
# author:mlnt
#createdate:2022/8/15
import docx #Import docx module
from docx.document import Document
from docx.oxml import CT_P, CT_Tbl
from docx.table import _Cell, Table, _Row
from docx.text.paragraph import Paragraph
def iter_block_items(parent):
"""
Traverse the document content in sequence
Generates references to each paragraph and table child in the parent in document order.
Each return value is an instance of a table or paragraph.
The parent object is usually a reference to the main document object, but also applies to _Cell objects, which can themselves contain paragraphs and tables.
:param parent:
:return:
"""
# Determine whether the passed in is a word document object, if so, get all sub-objects of the document content
if isinstance(parent, Document):
parent_elm = parent.element.body
# Determine whether the passed in cell is a cell, if so, get all sub-objects in the cell
elif isinstance(parent, _Cell):
parent_elm = parent.tc
# Determine whether it is a table row
elif isinstance(parent, _Row):
parent_elm = parent.tr
else:
raise ValueError("something's not right")
# Traverse all sub-objects
for child in parent_elm.iterchildren():
# Determine whether it is a paragraph, if so, return the paragraph object
if isinstance(child, CT_P):
yield Paragraph(child, parent)
# Determine whether it is a table, if so, return the table object
if isinstance(child, CT_Tbl):
yield Table(child, parent)
# 1. Create docx object
document = docx.Document('test.docx')
# Traverse the word document, and stop traversing when the last function call does not return a value
for block in iter_block_items(document):
# Determine whether it is a paragraph
if isinstance(block, Paragraph):
print(block.text)
# Determine whether it is a table
elif isinstance(block, Table):
for row in block.rows:
row_data = []
for cell in row.cells:
for paragraph in cell.paragraphs:
row_data.append(paragraph.text)
print("\t".join(row_data))
Test documentation:
Reading effect:
3. Create file content
-
Create docx object
# 1. Create docx object document = docx.Document()
-
Settings page
# Set header run_header = document.sections[0].header.paragraphs[0].add_run("test") document.sections[0].header.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment -
Add title
# 2. Add title """ add_heading(): Create a heading - document.add_heading('content_of_heading', level=n) """ document.add_heading('Xia Ke Xing', level=1) # Title 1 format document.add_heading('Li Bai', level=2) # Title 2 format -
Add paragraph
# 3. Add paragraphs #Create paragraph object """ add_paragraph(): Create paragraph Paragraph content - document.add_paragraph('paragraph_content') """ paragraph_object = document.add_paragraph('Zhao Keman Hu Ying, Wu Gou Shuang Xueming.') document.add_paragraph('The silver saddle shines on the white horse, rustling like a shooting star.') document.add_paragraph('Kill one person in ten steps, leave no trace in a thousand miles.') document.add_paragraph('When the matter is over, he brushes off his clothes and goes away, hiding his body and name.') document.add_paragraph('After leisurely drinking in Xinling, I took off my sword and stretched my knees forward.') document.add_paragraph('He will eat Zhu Hai and hold a cup to persuade the marquis to win.') document.add_paragraph('Three cups of Turanuo, the five mountains are lighter.') document.add_paragraph('After the eyes are dazzled and the ears are hot, the spirit and spirit are born.') document.add_paragraph('Save Zhao with a golden mallet, Handan was shocked first.') document.add_paragraph('Two heroes from the Qianqiu period, the great Daliang City.') document.add_paragraph('Even if you die as a hero, you will not be ashamed of being a hero in the world.') document.add_paragraph('Who can write your Excellency, Baishou Taixuan Sutra.') prior_paragraph_object = paragraph_object.insert_paragraph_before('') # Insert a new paragraph before paragraph -
Create Run content and set styles
# 4. Create Run content """ Paragraph is composed of Run. Use the add_run() method to insert content into Paragraph. The syntax is as follows: paragraph_object.add_run('run_content') """ run1 = prior_paragraph_object.add_run('*'*13) run2 = prior_paragraph_object.add_run('%'*13) # Set the style of Run """ bold: bold italic: italic underline: underline strike: delete line """ run1.bold = True run2.underline = True # Set paragraph center alignment for i in range(len(document.paragraphs)): document.paragraphs[i].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment -
Add form feed
# 5. Add page feed character # add_page_break() document.add_page_break()
-
Insert picture
# 6. Insert pictures # add_picture(), to adjust the picture width and height you need to import the docx.shared module document.add_picture('libai.jpeg', width=Pt(200), height=Pt(300)) # Set center alignment document.paragraphs[len(document.paragraphs)-1].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment -
Create a table, add data and set simple styles
# 7. Create a table """ add_table(rows=n, cols=m) """ table = document.add_table(rows=2, cols=5) #Add table content #Add the first row of data row = table.rows[0] row.cells[0].text = 'Name' row.cells[1].text = 'word' row.cells[2].text = 'number' row.cells[3].text = 'Era' row.cells[4].text = 'Alias' #Add the 2nd row of data row = table.rows[1] row.cells[0].text = 'Li Bai' row.cells[1].text = 'Taibai' row.cells[2].text = 'Qinglian Jushi' row.cells[3].text = 'Tang Dynasty' row.cells[4].text = 'Shixian' # insert row new_row = table.add_row() # Add table rows new_row.cells[0].text = 'Bai Juyi' new_row.cells[1].text = 'Rakuten' new_row.cells[2].text = 'Xiangshan Jushi' new_row.cells[3].text = 'Tang Dynasty' new_row.cells[4].text = 'Shimo' #Insert column new_column = table.add_column(width=Inches(1)) # Add table columns new_column.cells[0].text = 'Masterpiece' new_column.cells[1].text = '"Xia Ke Xing", "Quiet Night Thoughts"' new_column.cells[2].text = '"Song of Everlasting Sorrow", "Pipa Play"' # Calculate the length of rows and cols of the table rows = len(table.rows) cols = len(table.columns) print(f'rows: {rows}') print(f'columns: {cols}') #Print table content # for row in table.rows: # for cell in row.cells: # print(cell.text) # Set table style # table.style = 'LightShading-Accent1' # UserWarning: style lookup by style_id is deprecated. Use style name as key instead. table.style = 'Light Shading Accent 1' # Loop to set each row and column to center for r in range(rows): for c in range(cols): table.cell(r, c).vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # Vertical centering table.cell(r, c).paragraphs[0].paragraph_format.alignment = WD_TABLE_ALIGNMENT.CENTER # Horizontally centered -
Set page number and save
# Set page number add_page_number(document.sections[0].footer.paragraphs[0]) # save document document.save('test2.docx') -
Code to set page number (page_num.py)
from docx import Document from docx.enum.text import WD_PARAGRAPH_ALIGNMENT from docx.oxml import OxmlElement, ns def create_element(name): returnOxmlElement(name) def create_attribute(element, name, value): element.set(ns.qn(name), value) def add_page_number(paragraph): paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER page_run = paragraph.add_run() t1 = create_element('w:t') create_attribute(t1, 'xml:space', 'preserve') t1.text = 'Page ' page_run._r.append(t1) page_num_run = paragraph.add_run() fldChar1 = create_element('w:fldChar') create_attribute(fldChar1, 'w:fldCharType', 'begin') instrText = create_element('w:instrText') create_attribute(instrText, 'xml:space', 'preserve') instrText.text = "PAGE" fldChar2 = create_element('w:fldChar') create_attribute(fldChar2, 'w:fldCharType', 'end') page_num_run._r.append(fldChar1) page_num_run._r.append(instrText) page_num_run._r.append(fldChar2) of_run = paragraph.add_run() t2 = create_element('w:t') create_attribute(t2, 'xml:space', 'preserve') t2.text = ' of ' of_run._r.append(t2) fldChar3 = create_element('w:fldChar') create_attribute(fldChar3, 'w:fldCharType', 'begin') instrText2 = create_element('w:instrText') create_attribute(instrText2, 'xml:space', 'preserve') instrText2.text = "NUMPAGES" fldChar4 = create_element('w:fldChar') create_attribute(fldChar4, 'w:fldCharType', 'end') num_pages_run = paragraph.add_run() num_pages_run._r.append(fldChar3) num_pages_run._r.append(instrText2) num_pages_run._r.append(fldChar4) -
Complete code
import docx from docx.enum.table import WD_TABLE_ALIGNMENT, WD_CELL_VERTICAL_ALIGNMENT from docx.enum.text import WD_PARAGRAPH_ALIGNMENT from docx.shared import Pt, Inches from page_num import add_page_number # 1. Create docx object document = docx.Document() # Set header run_header = document.sections[0].header.paragraphs[0].add_run("test") document.sections[0].header.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment print(len(document.sections)) # 2.Add title """ add_heading(): Create a heading - document.add_heading('content_of_heading', level=n) """ document.add_heading('Xia Ke Xing', level=1) # Title 1 format document.add_heading('Li Bai', level=2) # Title 2 format # 3. Add paragraph #Create paragraph object """ add_paragraph(): Create paragraph Paragraph content - document.add_paragraph('paragraph_content') """ paragraph_object = document.add_paragraph('Zhao Keman Hu Ying, Wu Gou Shuang Xueming.') document.add_paragraph('The silver saddle shines on the white horse, rustling like a shooting star.') document.add_paragraph('Kill one person in ten steps, leave no trace in a thousand miles.') document.add_paragraph('When the matter is over, he brushes off his clothes and goes away, hiding his body and name.') document.add_paragraph('After leisurely drinking in Xinling, I took off my sword and stretched my knees forward.') document.add_paragraph('He will eat Zhu Hai and hold a cup to persuade the marquis to win.') document.add_paragraph('Three cups of Turanuo, the five mountains are lighter.') document.add_paragraph('After the eyes are dazzled and the ears are hot, the spirit and spirit are born.') document.add_paragraph('Save Zhao with a golden mallet, Handan was shocked first.') document.add_paragraph('Two heroes from the Qianqiu period, the great Daliang City.') document.add_paragraph('Even if you die as a hero, you will not be ashamed of being a hero in the world.') document.add_paragraph('Who can write your Excellency, Baishou Taixuan Sutra.') prior_paragraph_object = paragraph_object.insert_paragraph_before('') # Insert a new paragraph before paragraph # 4. Create Run content """ Paragraph is composed of Run. Use the add_run() method to insert content into Paragraph. The syntax is as follows: paragraph_object.add_run('run_content') """ run1 = prior_paragraph_object.add_run('*'*13) run2 = prior_paragraph_object.add_run('%'*13) # Set the style of Run """ bold: bold italic: italic underline: underline strike: delete line """ run1.bold = True run2.underline = True # Set paragraph center alignment for i in range(len(document.paragraphs)): document.paragraphs[i].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment # 5. Add page feed character # add_page_break() document.add_page_break() # print(len(document.paragraphs)) # 6. Insert picture # add_picture(), to adjust the picture width and height you need to import the docx.shared module document.add_picture('libai.jpeg', width=Pt(200), height=Pt(300)) # Set center alignment document.paragraphs[len(document.paragraphs)-1].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # Center alignment # 7.Create table """ add_table(rows=n, cols=m) """ table = document.add_table(rows=2, cols=5) #Add table content #Add the first row of data row = table.rows[0] row.cells[0].text = 'Name' row.cells[1].text = 'word' row.cells[2].text = 'number' row.cells[3].text = 'Era' row.cells[4].text = 'Alias' #Add the 2nd row of data row = table.rows[1] row.cells[0].text = 'Li Bai' row.cells[1].text = 'Taibai' row.cells[2].text = 'Qinglian Jushi' row.cells[3].text = 'Tang Dynasty' row.cells[4].text = 'Shixian' # insert row new_row = table.add_row() # Add table rows new_row.cells[0].text = 'Bai Juyi' new_row.cells[1].text = 'Rakuten' new_row.cells[2].text = 'Xiangshan Jushi' new_row.cells[3].text = 'Tang Dynasty' new_row.cells[4].text = 'Shimo' #Insert column new_column = table.add_column(width=Inches(1)) # Add table columns new_column.cells[0].text = 'Masterpiece' new_column.cells[1].text = '"Xia Ke Xing", "Quiet Night Thoughts"' new_column.cells[2].text = '"Song of Everlasting Sorrow", "Pipa Play"' # Calculate the length of rows and cols of the table rows = len(table.rows) cols = len(table.columns) print(f'rows: {rows}') print(f'columns: {cols}') #Print table content # for row in table.rows: # for cell in row.cells: # print(cell.text) # Set table style # table.style = 'LightShading-Accent1' # UserWarning: style lookup by style_id is deprecated. Use style name as key instead. table.style = 'Light Shading Accent 1' # Loop to set each row and column to center for r in range(rows): for c in range(cols): table.cell(r, c).vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # Vertical centering table.cell(r, c).paragraphs[0].paragraph_format.alignment = WD_TABLE_ALIGNMENT.CENTER # Horizontally centered # Set page number add_page_number(document.sections[0].footer.paragraphs[0]) # save document document.save('test2.docx')Effect:


Reference:
- Python – library docx (seven: page settings, header and footer paper) 1.16_python docx library insert header_EUDI’s blog-CSDN blog
- Add page numbers using pythondocx – Q&A – Python Chinese website
- [python-docx] Insert pictures, delete pictures, set picture size, extract pictures_python docx insert pictures_Icy Hope’s Blog-CSDN Blog
- python office automation (5) python-docx adds documents, tables, pictures, sets paragraphs and font styles – CSDN Blog
- python docx | Center table elements vertically and horizontally_python-docx center alignment_Sea Urchin Sur’s Blog-CSDN Blog
- python-docx official documentation: python-docx – python-docx 0.8.11 documentation
- python_docx reads the content of word_python docx search_yma16’s blog-CSDN blog
- https://www.cnblogs.com/wl0924/p/16531087.html
- Python reads the content of docx documents_python reads docx tables_Jiangxi Normal University-20th Class-Wu You’s Blog-CSDN Blog
- python-docx gets tables from paragraphs | Problems encountered