Table of Contents
1. Consumer confirmation
2. Failure retry mechanism
2.1. Failure handling strategy
3. Business idempotence
3.1. Unique message ID
3.2. Business judgment
3.3. Cover-up plan
1. Consumer Confirmation
RabbitMQ provides a consumer confirmation mechanism (Consumer Acknowledgement). That is: when the consumer finishes processing the message, it should send a receipt to RabbitMQ to inform RabbitMQ of its message processing status. The return receipt has three optional values:
- ack: The message is successfully processed and RabbitMQ deletes the message from the queue
- nack: Message processing failed, RabbitMQ needs to deliver the message again
- Reject: The message processing fails and the message is rejected. RabbitMQ deletes the message from the queue.
Generally, the reject method is rarely used, unless there is a problem with the message format, then it is a development problem. Therefore, in most cases we need to capture the message processing code through the try catch mechanism. When the message processing is successful, ack is returned, and when the processing fails, nack is returned.
Since the message receipt processing code is relatively unified, SpringAMQP helps us implement message confirmation. And allows us to set the ACK processing method through the configuration file. There are three modes:
- none: Not processed. That is, if the message is acked immediately after it is delivered to the consumer, the message will be deleted from MQ immediately. Very unsafe and not recommended to use
manual: Manual mode. You need to call the api yourself in the business code and sendackorreject. There is business intrusion, but it is more flexible.auto: Automatic mode. SpringAMQP uses AOP to make surround enhancements to our message processing logic. When the business is executed normally,ackis automatically returned. When an exception occurs in the business, different results are returned based on the exception judgment:- If it is a business exception,
nackwill be returned automatically; - If it is a message processing or verification exception, it will automatically return
reject;
- If it is a business exception,
SpringAMQP’s ACK processing method can be modified through the following configuration:
spring:
rabbitmq:
host: 192.168.200.129 # Your virtual machine IP
port: 5672 #Port
virtual-host: / # virtual host
username: admin # Username
password: 123 # Password
listener:
simple:
prefetch: 1 # Only one message can be obtained at a time, and the next message cannot be obtained until the processing is completed.
acknowledge-mode: none
When using none mode
The producer sends a message

An exception is thrown when the consumer receives the message


The test can find that when an exception occurs in message processing, the message is still deleted by RabbitMQ.
Modify the confirmation mechanism to auto
spring:
rabbitmq:
host: 192.168.200.129 # Your virtual machine IP
port: 5672 #Port
virtual-host: / # virtual host
username: admin # Username
password: 123 # Password
listener:
simple:
prefetch: 1 # Only one message can be obtained at a time, and the next message cannot be obtained until the processing is completed.
acknowledge-mode: auto
Send message again


Break the point at the abnormal position and send the message again. When the program is stuck at the breakpoint, you can find that the message status is unacked (undetermined status):

When we change the configuration to auto, after the message processing fails, it will return to RabbitMQ and re-deliver to the consumer.

2. Failure retry mechanism
When an exception occurs to the consumer, the message will be continuously requeued (re-queued) to the queue and then re-sent to the consumer. If the consumer still fails when executing again, the message will be requeueed to the queue and delivered again until the message is processed successfully. In the extreme case, if the consumer has been unable to execute successfully, then the message requeue will loop infinitely, causing MQ’s message processing to soar and causing unnecessary pressure.
In order to deal with the above situation, Spring provides a consumer failure retry mechanism: local retry is used when the consumer encounters an exception, instead of unlimited requeue to the mq queue.
Modify the application.yml file of the consumer service and add content
spring:
rabbitmq:
host: 192.168.200.129 # Your virtual machine IP
port: 5672 #Port
virtual-host: / # virtual host
username: admin # Username
password: 123 # Password
listener:
simple:
prefetch: 1 # Only one message can be obtained at a time, and the next message cannot be obtained until the processing is completed.
acknowledge-mode: auto #Message confirmation
retry:
enabled: true # Fail to open the consumer and try again
initial-interval: 1000ms # The waiting time for failure of first acquaintance is 1 second
multiplier: 1 # Multiple of failed waiting time, next waiting time = multiplier * last-interval
max-attempts: 3 # Maximum number of retries
stateless: true # true is stateless; false is stateful. If the business contains transactions, change this to false

Restart the consumer service and repeat the previous test. It can be found:
- After the consumer failed, the message did not return to MQ for infinite re-delivery, but retried locally three times.
in conclusion:
- When local retry is enabled, an exception is thrown during message processing and will not be requeued to the queue, but will be retried locally on the consumer.
- After the maximum number of retries is reached, Spring will return reject and the message will be discarded.
2.1. Failure handling strategy
In previous tests, messages were discarded after the local test reached the maximum number of retries. This is obviously not suitable in some business scenarios that require high message reliability.
Therefore, Spring allows us to customize the message processing strategy after the number of retries is exhausted. This strategy is defined by the MessageRecovery interface, which has 3 different implementations:
RejectAndDontRequeueRecoverer: After the retries are exhausted, directlyrejectand discard the message. This is the defaultImmediateRequeueMessageRecoverer: After the retries are exhausted,nackis returned and the message is re-enqueued.RepublishMessageRecoverer: After the retries are exhausted, the failed message is delivered to the specified switch.
Create an exception message configuration class in the consumer
@Configuration
@Slf4j
//The configuration class only takes effect when the spring.rabbitmq.listener.simple.retry.enabled property in the configuration file is true
@ConditionalOnProperty(name = "spring.rabbitmq.listener.simple.retry.enabled", havingValue = "true")
public class ErrorMessageConfig {
//Message processing failed switch
@Bean
public DirectExchange errorMessageExchange(){
return new DirectExchange("error.direct");
}
//Message processing failure queue
@Bean
public Queue errorQueue(){
return new Queue("error.queue", true);
}
//Binding relationship
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){
return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
//Define a RepublishMessageRecoverer and associate the queue and switch
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){
log.error("Loading RepublishMessageRecoverer");
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
}
When an exception occurs when receiving a message, the error.queue queue will be created.

Exception information can be viewed

3. Business idempotence
What is idempotence? Idempotence is a mathematical concept, which is described by a function expression as follows: f(x) = f(f(x)), for example, finding the absolute value function. In program development, it means that the same business, executed once or multiple times, has the same impact on the business status. For example:
- Delete data based on id
- Query data
- Add new data
However, data updates are often not idempotent, and may cause different consequences if repeated. for example:
- Cancel orders and restore inventory. If restored multiple times, inventory will increase repeatedly.
- Refund business. Repeated chargebacks will cause financial losses to merchants.
Therefore, we must avoid repeated execution of business as much as possible. However, in actual business scenarios, businesses often are executed repeatedly due to accidents, such as:
- When the page freezes, frequent refreshes result in repeated form submissions.
- Retries of inter-service calls
- Repeated delivery of MQ messages
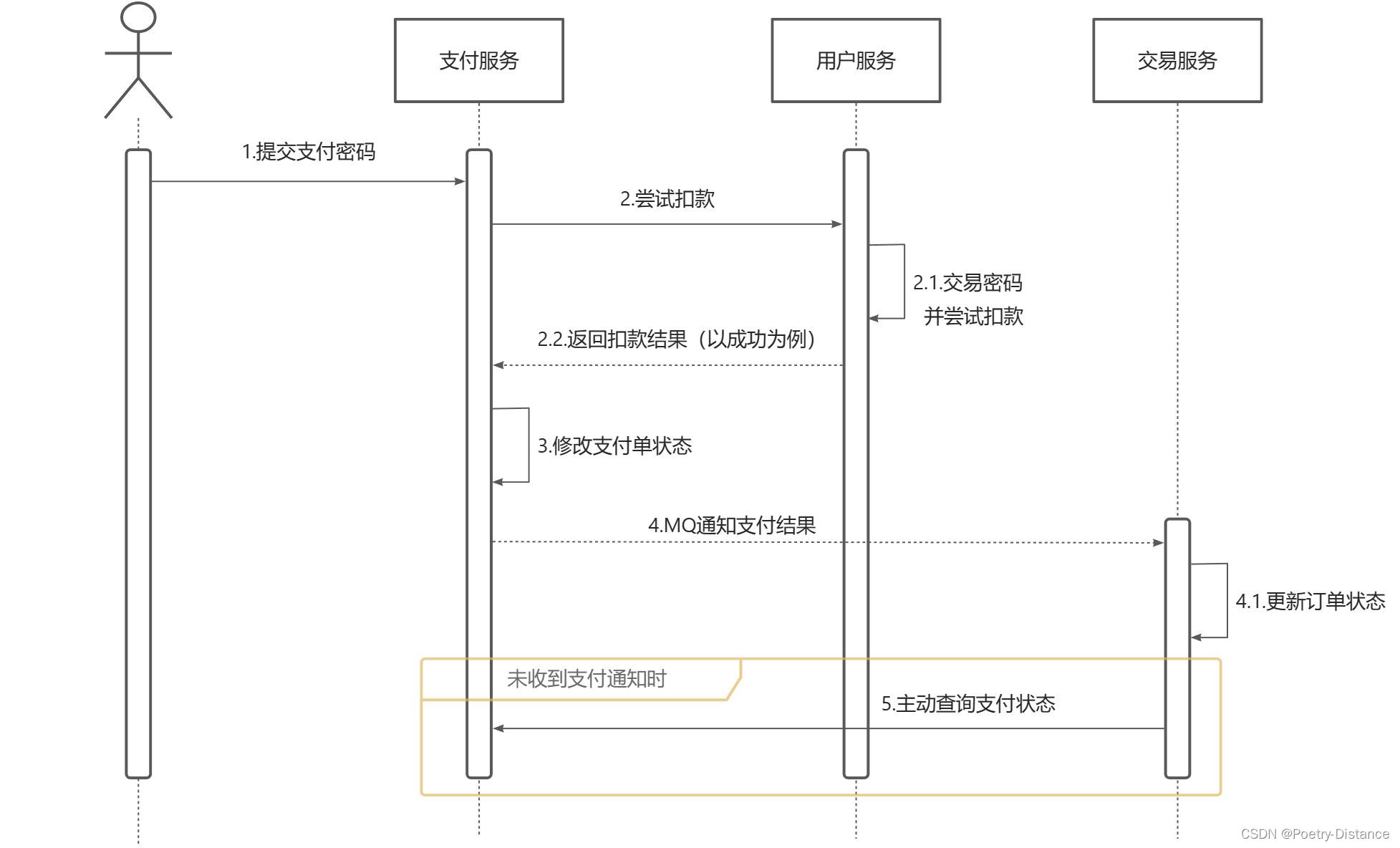
After the user successfully pays, we will send an MQ message to the transaction service and modify the order status to paid. This may cause repeated delivery of the message. If the consumer does not make a judgment, it is very likely that the message will be consumed multiple times and a business failure will occur. Example:
- If the user has just completed payment and delivers a message to the transaction service, the transaction service changes the order to the Paid status.
- Due to some reason, such as network failure, the producer did not receive confirmation, and it was re-delivered to the transaction service after a period of time.
- However, before the newly delivered message was consumed, the user chose a refund and changed the order status to Refunded status.
- After the refund is completed and the newly delivered message is consumed, the order status will be changed to Paid again. Business abnormality.
Therefore, we must find ways to ensure the idempotence of message processing. Two options are given here:
- Unique message ID
- Business status judgment
3.1, Unique Message ID
- Each message generates a unique ID and is delivered to the consumer together with the message.
- After receiving the message, the consumer processes its own business. After the business processing is successful, the message ID is saved to the database.
- If the same message is received next time, go to the database to check whether it exists. If it exists, it will be a duplicate message and will be discarded.
SpringAMQP’s MessageConverter comes with the MessageID function. We only need to enable this function. Take Jackson’s message converter as an example
Add a configuration to the startup class of the producer and consumer
@Bean
public MessageConverter messageConverter(){
// 1. Define message converter
Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();
// 2. Configure the automatically created message ID to identify different messages. You can also determine whether it is a duplicate message based on the ID in the business.
jjmc.setCreateMessageIds(true);
return jjmc;
}
When the test producer sends a message, an id will be generated

3.2. Business Judgment
Business judgment is to judge whether there are repeated requests or messages based on the logic or status of the business itself. The ideas for judgment are different in different business scenarios. For example, in our current case, the business logic for processing messages is to change the order status from unpaid to paid. Therefore, we can determine whether the order status is unpaid when executing the business. If not, it proves that the order has been processed and there is no need to process it again.

In comparison, the message ID solution requires the transformation of the original database, so I recommend the business judgment solution.
Taking the payment and order modification business as an example, we need to modify the markOrderPaySuccess method in OrderServiceImpl:
@Override
public void markOrderPaySuccess(Long orderId) {
// 1. Query order
Order old = getById(orderId);
// 2. Determine order status
if (old == null || old.getStatus() != 1) {
// The order does not exist or the order status is not 1, give up processing
return;
}
// 3. Try to update the order
Order order = new Order();
order.setId(orderId);
order.setStatus(2);
order.setPayTime(LocalDateTime.now());
updateById(order);
}
The above code logically meets the requirements of idempotent judgment, but since judgment and update are two-step actions, there may be thread safety issues with a very small probability.
@Override
public void markOrderPaySuccess(Long orderId) {
// UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1
lambdaUpdate()
.set(Order::getStatus, 2)
.set(Order::getPayTime, LocalDateTime.now())
.eq(Order::getId, orderId)
.eq(Order::getStatus, 1)
.update();
}
Note that the above code is equivalent to this SQL statement:
UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1
In addition to judging the id, we also added the condition that status must be 1 in the where condition. If the conditions do not match (indicating that the order has been paid), the SQL cannot match the data and will not be executed at all.
3.3. Cover-up plan
We can set up scheduled tasks in the transaction service to check the order payment status regularly. In this way, even if the MQ notification fails, scheduled tasks can be used as a fallback solution to ensure the final consistency of the order payment status.