1 Overview
Redis is an in-memory database. That is, when the server is running, the system allocates a portion of memory to store data. When the service area suddenly goes down, the data in the database will be lost. In order to deal with this situation, persistence must be used. way to save data from memory to disk, as shown in the following figure:
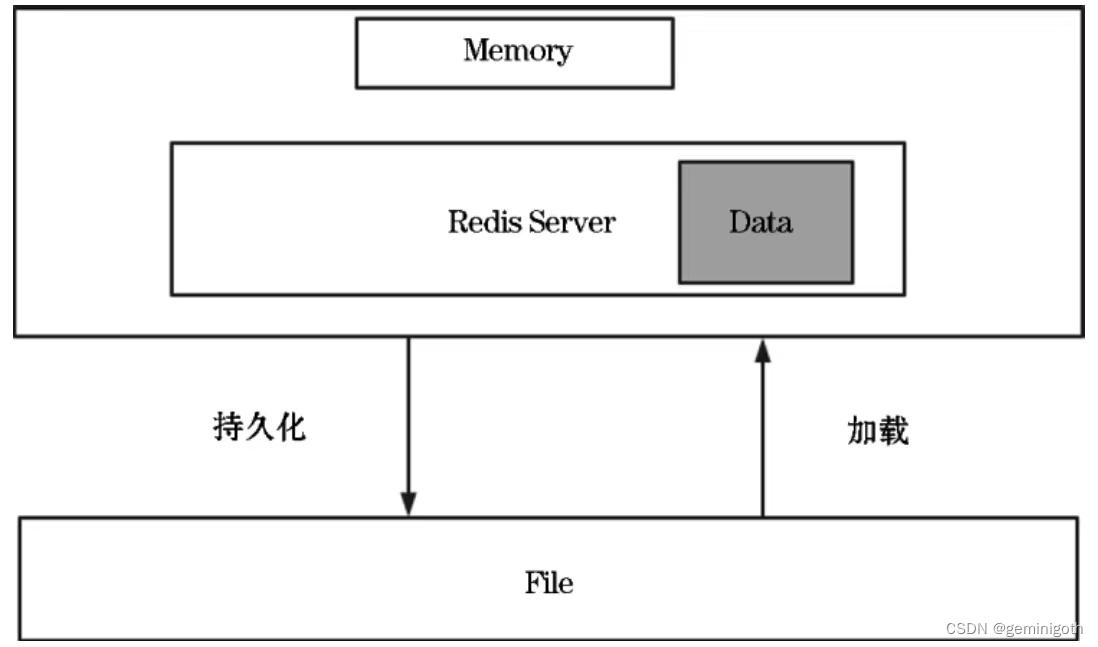
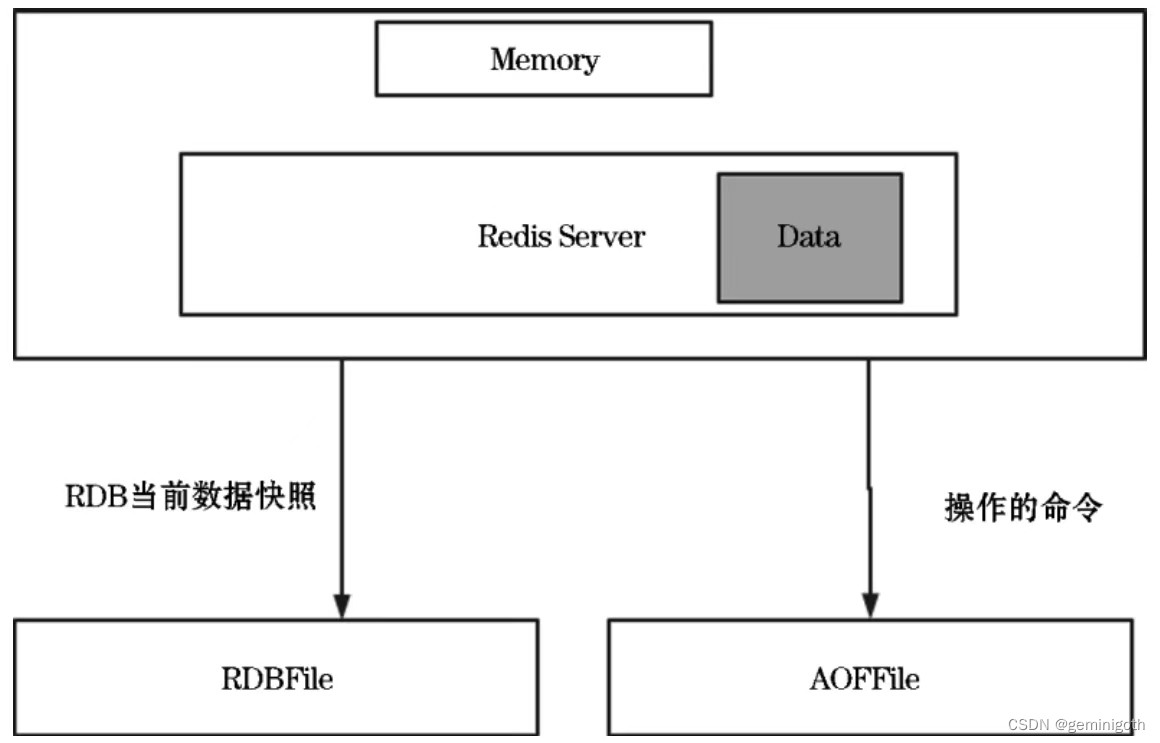
There are two solutions for Redis persistent storage: RDB (RedisDataBase) and AOF (Append-Only File). RDB stores snapshots of data in memory to disk, and AOF records all operations in Redis through logs. Redis 4 and later supports AOF + RDB hybrid persistence. Combining the advantages of the two, you can turn on the hybrid persistence function through the aof-use-rdb-preamble configuration.
Redis provides a different range of persistence options:
RDB persistence stores point-in-time snapshots of the data set at specified intervals.
AOF persistence records every write operation received by the server, which will be “played” again when the server starts to reconstruct the original data set. Commands are recorded using the same format as the Redis protocol, and only in append mode. When the log is too large, Redis will rewrite the log in the background.
The RDB and AOF diagram of Redis persistence is as follows:
2 RDB persistence
2.1 RDB Overview
RDB stores snapshots of data in Redis memory to disk and is the default persistence solution for Redis. RDB persistence has three strategies by default, which can be configured in redis.conf. The snapshot operation will be triggered based on the number of modifications within a period of time. The snapshot file name is dump.rdb. Whenever the Redis server is restarted, the data will be loaded into memory from this file.
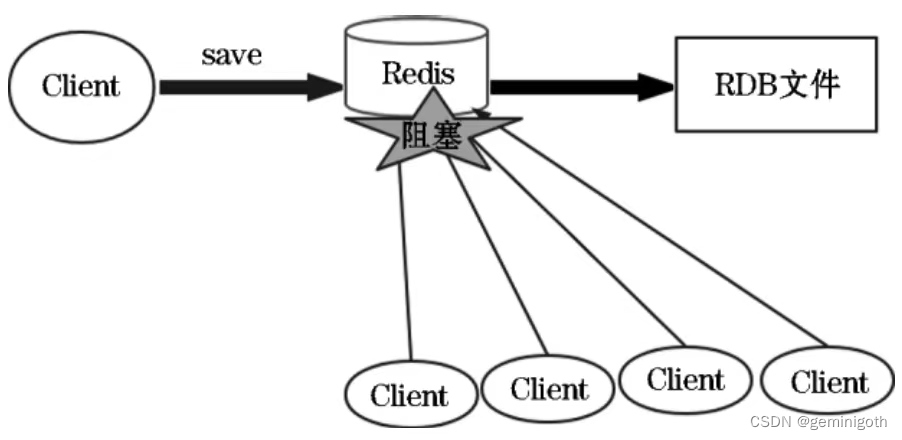
In addition to being triggered according to the policies in the configuration, RDB persistence can also be triggered manually using the save and bgsave commands. The difference between these two commands is that save blocks the server process. During the execution of the save command, the server cannot process any requests, but the bgsave command will perform RDB persistence of data in the background through a word. Essentially, both save and bgsave call the rdbsave function, so Redis does not allow save and bgsave to be executed at the same time to avoid inconsistency in RDB file data.
2.2 save triggering method
The source code of the save command is as follows:
void saveCommand(client *c) {
//When the bgsave command is executed, the save command cannot be executed.
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
return;
}
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo( & amp;rsi);
//Call rdbsave function for backup
if (rdbSave(server.rdb_filename,rsiptr) == C_OK) {
addReply(c,shared.ok);
} else {
addReply(c,shared.err);
}
}
The save command saves the image of memory data as an RDB file. Since Redis executes commands in a single-threaded manner, the Redis service process will be blocked during the execution of the save command, and the Redis service will no longer process any commands until the RDB file creation is completed. It is generally not recommended to use the save command to perform persistence. As shown below:
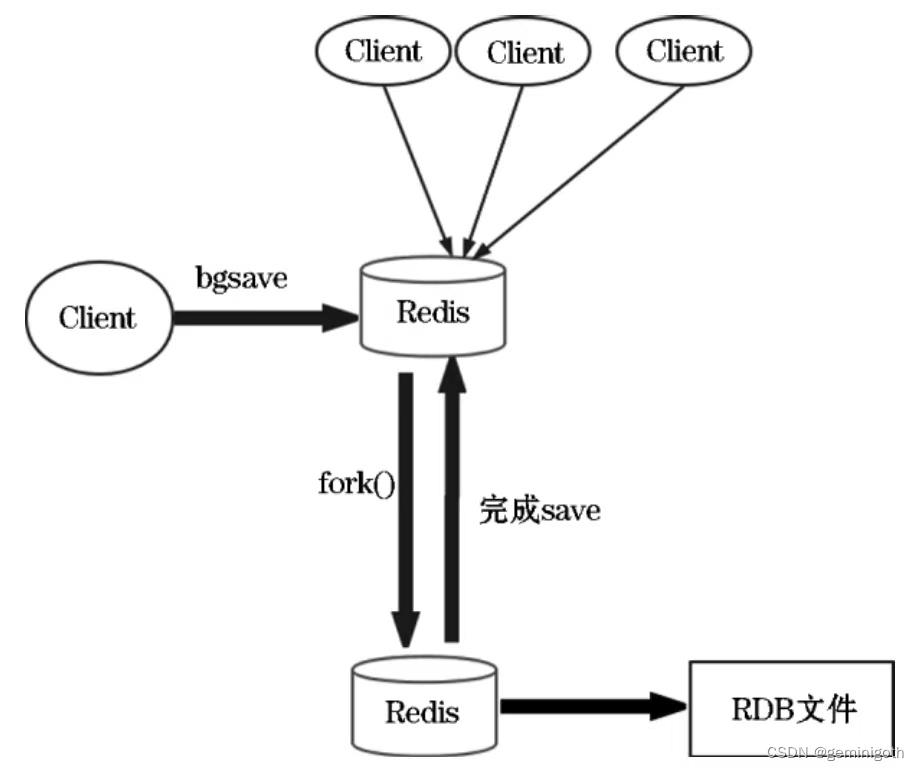
2.3 bgsave trigger
When executing the bgsave command, the processing flow of the Redis server is as follows:
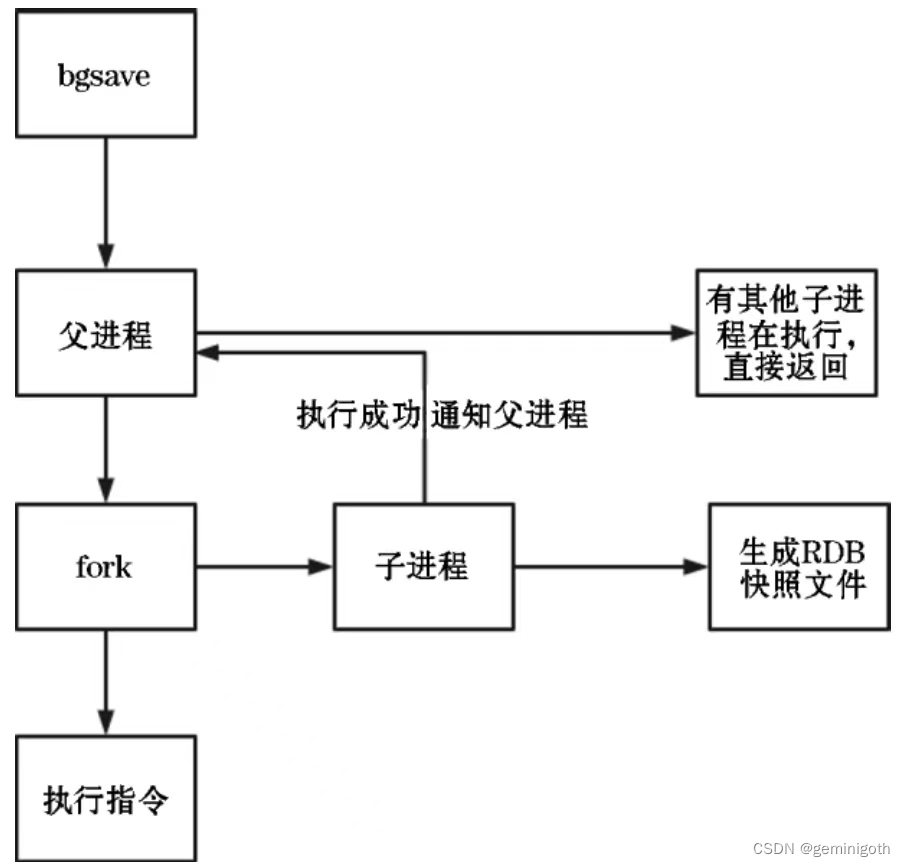
The bgsave command uses the CopyOnWrite mechanism to perform copy operations while writing. A child process writes the latest data in the memory to a temporary file in sequence. At this time, the parent process is still processing the client’s operations. When the child process completes execution, the temporary file is Rename to dump.rdb. Therefore, regardless of whether the bgsave command is executed successfully, dump.rdb will not be affected. Therefore it is recommended to use bgsave.
The source code of the bgsave command is as follows:
void bgsaveCommand(client *c) {
int schedule = 0;
/* When AOF is being executed, bgsave will be executed after AOF is completed */
if (c->argc > 1) {
//The parameter can only be schedule
if (c->argc == 2 & amp; & amp; !strcasecmp(c->argv[1]->ptr,"schedule")) {
schedule = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo( & amp;rsi);
//When the bgsave command is being executed, the save command will not be executed.
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
} else if (hasActiveChildProcess()) {
if (schedule) {
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c,"Background saving scheduled");
} else {
addReplyError(c,
"Another child process is active (AOF?): can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenever "
"possible.");
}
}
//Otherwise call rdbSaveBackground to perform backup operation
else if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK) {
addReplyStatus(c,"Background saving started");
} else {
addReply(c,shared.err);
}
}
When executing the bgsave command, Redis can continue to process client operations, as shown below
2.4 Background trigger
The following is the configuration file for RDB persistence:
#Timing persistence rules save 900 1 save 300 10 save 60 10000 #The default value is yes. When RDB is enabled and the last time saving data in the background fails, Redis should stop receiving data. #yes means you can continue to write data. no means it will not write and notify the user that there is an error in persistence. stop-writes-on-bgsave-error yes #Whether persistent data is compressed rdbcompression yes #Whether the stored snapshots are subject to CRC64 algorithm data verification. If you want to obtain the maximum performance improvement, you can turn off this function. rdbchecksum yes #Set the file name of the snapshot, the default is dump.rdb dbfilenamedump.rdb
There are three default RBD persistence strategies:
1. RDB persistence is triggered if there are 10,000 operations within 60 seconds.
2. When the above conditions are not met, persistence will be triggered if there is one operation within 900 seconds.
3. When the second condition is not met, persistence will be triggered if there are 10 operations within 300 seconds.
Similarly, you can manually modify parameters or add new strategies.
#If there are changes data operations within seconds, RDB persistence will be triggered. save <seconds> <changes>
The source code that triggers persistence is as follows:
struct saveparam {
//Record seconds
time_t seconds;
//Record the number of operations and clear them after each RDB execution.
int changes;
};
/* Persistence related objects*/
//Record data changes after the last save
long long dirty; /* Changes to DB from the last save */
//Used to restore dirty data on failed bgsave
long long dirty_before_bgsave; /* Used to restore dirty on failed BGSAVE */
//The child process number of the RDB process
pid_t rdb_child_pid; /* PID of RDB saving child */
//Data points stored in RDB operation
struct saveparam *saveparams; /* Save points array for RDB */
//Save the stored points
int saveparamslen; /* Number of saving points */
//RDB file name
char *rdb_filename; /* Name of RDB file */
//Whether to compress the file
int rdb_compression; /* Use compression in RDB? */
//Whether to verify the file
int rdb_checksum; /* Use RDB checksum? */
int rdb_del_sync_files; /* Remove RDB files used only for SYNC if
the instance does not use persistence. */
//Record the time of the last successful save
time_t lastsave; /* Unix time of last successful save */
//The UNIX time of the last attempt to save
time_t lastbgsave_try; /* Unix time of last attempted bgsave */
//The time it took for the last RDB operation to run
time_t rdb_save_time_last; /* Time used by last RDB save run. */
//Current RDB operation start time
time_t rdb_save_time_start; /* Current RDB save start time. */
//Mark whether RDB operations can be performed
int rdb_bgsave_scheduled; /* BGSAVE when possible if true. */
//RDB subprocess operation type
int rdb_child_type; /* Type of save by active child. */
//The result of the last RDB operation
int lastbgsave_status; /* C_OK or C_ERR */
//If it cannot be saved, writing is not allowed
int stop_writes_on_bgsave_err;
From the source code above, we can see that the counter records how many write operations Redis has performed after the last successful persistence. Its value is incremented by 1 after each write operation. The record will be cleared after the configuration conditions are met and persistence is completed. zero. Redis also has a periodic operation function, which is executed every 100ms by default. One of its tasks is to check whether the conditions for automatically triggering the bgsave command are established. The following is the relevant source code for some operations:
for (j = 0; j < server.saveparamslen; j + + ) {
struct saveparam *sp = server.saveparams + j;
/* Determine whether to trigger the bgsave operation based on the configured time and execution time */
if (server.dirty >= sp->changes & amp; & amp;
server.unixtime-server.lastsave > sp->seconds & amp; & amp;
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo( & amp;rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
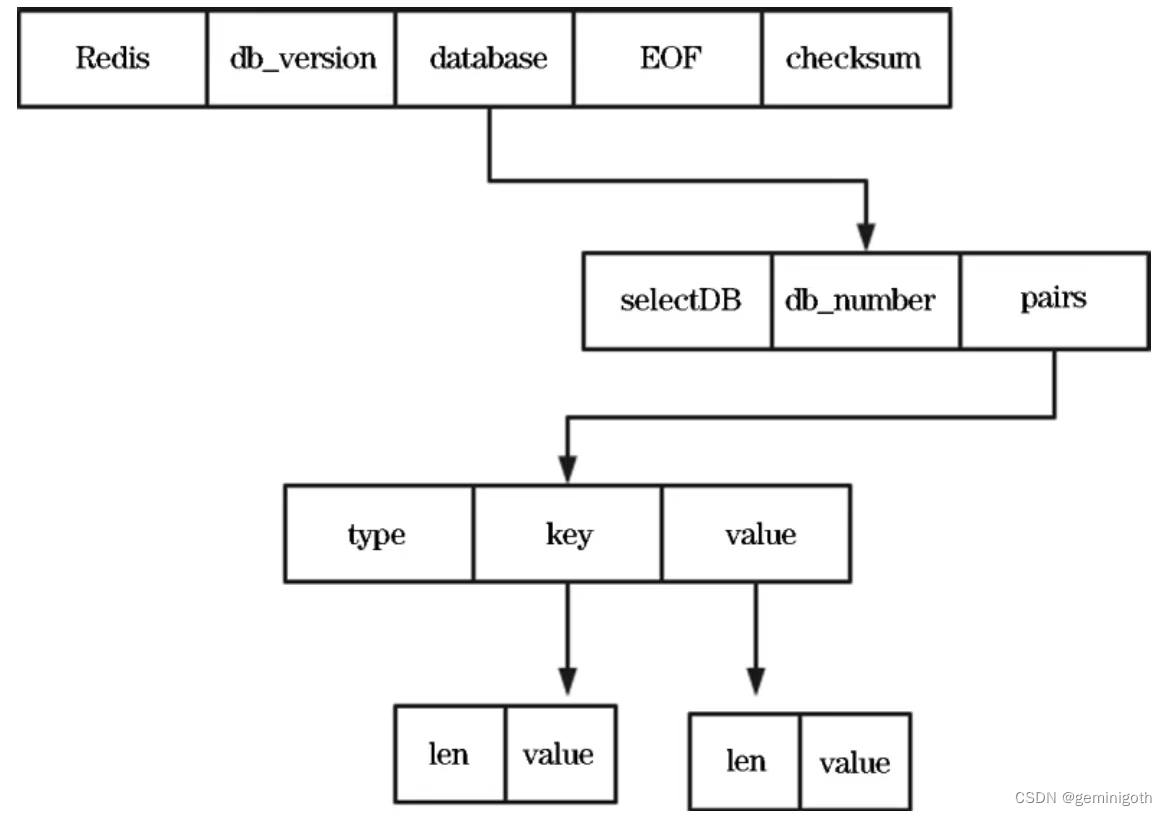
The RDB file structure is as follows:
2.5 Application scenarios of RDB backup
RDB is a compact data file saved by time point in Redis, which is very suitable for backup. For example, archive data (as an RDB file) every hour for the last 24 hours, and save an RDB snapshot every day for 30 days, so that in the event of a disaster, you can easily restore the data set to a backup at a different point in time. data.
An RDB is a compact file that is useful for disaster recovery and can be transferred to a remote data center.
RDB maximizes the performance of Redis because the only work the Redis parent process does for persistence is to dispatch a child process and leave the rest of the work to the child process. The parent process will never perform anything similar to disk I Operations such as /O can give Redis the ability to restore data faster.
Using an RDB is ideal if you need to minimize the possibility of data loss. Different rules can be set when generating the RDB (for example, 100 writes to the data set within five minutes, resulting in multiple save points), and RDB snapshots are usually created every 5 minutes or more. If Redis stops working without shutting down properly, at most some data after one backup operation will be lost.