NoSQL database
NoSQL databases are non-relational databases that do not use Structured Query Language (SQL) for data manipulation. Instead, they use other data models for access and data storage. SQL databases are often used to handle structured data, but they may not be the best choice for unstructured or semi-structured data.
NoSQL databases provide the ability to store and retrieve large amounts of data quickly and efficiently. They support multiple data types such as hierarchical data, documents, graphs, and key-value pairs. Common examples of NoSQL databases include document databases and key-value stores.
When to use a NoSQL database?
NoSQL databases are suitable for specific use cases where traditional SQL databases may not be suitable. Here are some situations where NoSQL databases can be useful:
Handling large-scale data
NoSQL databases are best suited for large-scale unstructured or semi-structured data. This could be data that doesn’t follow a strict format, such as social media posts, user-generated content, IoT device data, or machine logs. NoSQL databases are designed to handle large amounts of data and are highly scalable.
High scalability
NoSQL databases are great when you have to deal with databases that need to handle thousands or more concurrent connections, or when you need to process and store fast-flowing and changing data. They provide automatic sharding, replication, and other features that help scale out across hundreds or thousands of commodity servers.
Flexibility to change data schema
NoSQL databases are very flexible and can adapt to changes in data schema because they do not enforce the consistency rules imposed by traditional relational databases. This means that it is much easier to update or add new fields to a data model in a NoSQL database than in a SQL database. This makes NoSQL databases an excellent choice for businesses that need to quickly adapt their data models to new types of data or changing business needs.
Cost-effective scaling
Another great reason to use a NoSQL database is to save costs associated with scaling. Because NoSQL databases scale horizontally across multiple commodity servers, they are often a more cost-effective solution than traditional SQL databases that require vertical scaling, which involves purchasing more powerful hardware. As your data grows, you can easily add more servers to your NoSQL cluster to meet demand.
How do NoSQL databases work?
NoSQL databases, also known as non-relational databases are designed to handle large amounts of unstructured or semi-structured data. The term “NoSQL” stands for “Not Only SQL” and refers to the Structured Query Language (SQL) used by NoSQL databases that are not limited to traditional relational databases.
NoSQL databases use a variety of data models to store and access data. Some common data models include:
- Document database: Stores data in semi-structured documents, usually in JSON or XML format. Examples of document databases include MongoDB and Couchbase.
- Key-value database: stores data as a collection of key-value pairs, where the key is a unique identifier for the data. Examples of key-value databases include Riak and Redis.
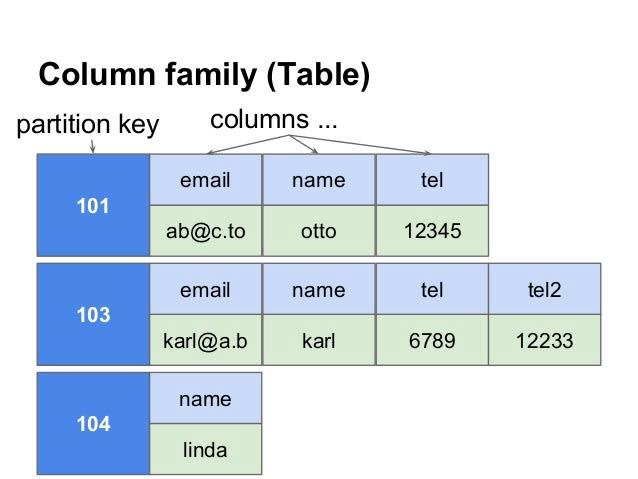
- Column Family Database: Stores data as column families, where each column family contains a set of related columns. Examples of column family databases include Apache Cassandra and HBase.
- Graph database: Store data as nodes and edges, where nodes represent entities and edges represent relationships between entities. Examples of graph databases include Neo4j and OrientDB.
NoSQL databases are highly scalable and can handle large amounts of data across multiple servers. They are commonly used in big data applications to store and process large amounts of unstructured data, such as social media feeds, user-generated content, and clickstream data.
How to use NoSQL database?
To use NoSQL databases in your code, you first need to choose a NoSQL database that suits your requirements. Some popular examples of NoSQL databases are MongoDB, Cassandra, Redis, and DynamoDB. Each of these databases has its own set of APIs and drivers that can be used to interact with them. Here, I will take MongoDB as an example to illustrate how to use Python and its PyMongo package for CRUD operations.
Setting up MongoDB
First, you need to have MongoDB installed on your system. You can refer to the official MongoDB documentation for instructions on how to do this.
Once MongoDB is installed, you can start it by running the following command in Terminal:
mongod
Connect to MongoDB using Python
Next, you need to install the pymongo library, which is the official Python client library for MongoDB. You can install it with pip:
pip install pymongo
After installing pymongo, you can use the following code to connect to your MongoDB instance:
import pymongo
# Create a MongoClient
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Create a database
db = client["your_datebase_name"]
This code creates a MongoClient object, which represents a MongoDB instance on your system, and a MongoDatabase object, which represents a database within that instance.
Create collection and insert documents
Once connected to a database, you can create a collection in that database with the following code:
# Create a collection collection = db["mycollection"]
This code creates a MongoCollection object, which represents a collection in the database. insert_oneYou can then use this object to insert documents into the collection using the or method insert_many:
# Insert a single document
document = {"name": "John", "age": 30}
result = collection. insert_one(document)
print(result. inserted_id)
# Insert multiple documents
documents = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 35},
{"name": "Charlie", "age": 45}
]
result = collection. insert_many(documents)
print(result. inserted_ids)
The insert_one method inserts a single document into the collection and returns an InsertOneResult object containing information about the operation. The inserted_id property of this object contains the _id of the inserted document.
The insert_many method inserts multiple documents into the collection and returns an InsertManyResult object containing information about the operation. The object’s properties contain a list of values inserted_ids for the inserted document. _id
Read documents from a collection
To retrieve one or more documents from a collection, you can use the following find method:
# Find a single document
query = {"name": "John"}
document = collection. find_one(query)
print(document)
# Find multiple documents
query = {"age": {"$gt": 30}}
documents = collection. find(query)
for document in documents:
print(document)
The find_one method retrieves a single document from the collection that matches the query and returns a dict object representing that document.
The find method retrieves multiple documents from the collection that match the query and returns a Cursor object that can be used to iterate over the documents. The parameter query is the object of dict specifying the query condition. In the second example, the query retrieves all documents where the field age is greater than 30.
Update documents in a collection
To update one or more documents in a collection, use the update_one or update_many method:
# Update a single document
query = {"name": "John"}
new_value = {"$set": {"age": 32}}
result = collection. update_one(query, new_value)
print(result. modified_count)
# Update multiple documents
query = {"age": {"$lt": 30}}
new_value = {"$inc": {"age": 1}}
result = collection. update_many(query, new_value)
print(result. modified_count)
The first example uses the update_one method to update a single document in the collection that matches the query. The query parameter specifies the criteria for selecting documents to update, and the new_value parameter specifies the changes to be made to the document. Here, the $set operator is used to set the age field to 32.
The second example uses the update_many method to update multiple documents in the collection that match the query. In this example, the $lt operator is used to select documents whose field age is less than 30, and the $inc operator is used for age
Removing documents from a collection
To delete one or more documents from a collection, use the delete_one or delete_many method:
# Delete a single document
query = {"name": "John"}
result = collection. delete_one(query)
print(result. deleted_count)
# Delete multiple documents
query = {"age": {"$gt": 40}}
result = collection. delete_many(query)
print(result. deleted_count)
The first example uses the delete_one method to delete a single document matching the query from the collection. The deleted_count property of the object returned by this method indicates the DeleteResult number of documents that were deleted.
The second example uses the delete_many method to delete multiple documents matching the query from the collection. Here $gt uses the operator to select documents whose field age is greater than 40.
Advantages
- NoSQL databases are highly scalable and designed to handle large amounts of data and complex queries.
- They provide a flexible data model where fields can be easily added or removed without changing the database schema.
- NoSQL databases can handle high volume transactions with faster read and write speeds than relational databases.
- They are generally less expensive to run than relational databases because they can run on low-cost commodity hardware.
Disadvantages:
- NoSQL databases may not provide features such as joins or ACID transactions, which can be a problem for some use cases.
- Unlike relational databases, NoSQL databases do not have well-defined standards, which can lead to data consistency and portability issues.
- NoSQL databases have a smaller developer and user community than SQL databases, which means fewer resources and support are available.
- Due to their different designs and use cases, NoSQL databases have a steeper learning curve and require specialized skills to operate effectively.