Article directory
- Preface
- 1. Let’s look at the conclusion first
-
- 1. From the perspective of Shuffle
- 2. From a functional perspective
- 2. Examples and drawings
-
- 1. What are the functions implemented?
-
- 1).groupByKey implements WordCount
- 2).reduceByKey implements WordCount
- 2. Draw a picture to analyze the difference between the two implementation methods.
-
- 1) groupByKey implements WordCount
- 2).reduceByKey implements WordCount (simple process)
- 3).reduceByKey implements WordCount (ultimate process)
- Summarize
Foreword
Explain Spark using scala language
1. Let’s look at the conclusion first
1. From the perspective of Shuffle
Both reduceByKey and groupByKey have shuffle operations, but reduceByKey can pre-aggregate (combine) the data sets with the same key in the partition before shuffling, which will reduce the amount of data placed on the disk, while groupByKey only performs grouping and does not reduce the amount of data. The problem is that reduceByKey has relatively high performance.
2. From a functional perspective
reduceByKey actually includes the functions of grouping and aggregation; groupByKey can only group, not aggregate, so in the case of group aggregation, it is recommended to use reduceByKey. If it is just grouping without aggregation, then groupByKey can only be used.
2. Examples and drawings
1. What are the functions implemented?
To facilitate understanding, two operators are used to implement the WordCount program. Assuming that the word has been processed into the form of (word,1), I use List((“a”, 1), (“a”, 1), (“a”, 1), (“b”, 1)) as a data source.
1).groupByKey implements WordCount
- Function: groupByKey can group the data source data according to key and value.
First, let’s take a look at what is the return value of using groupByKey alone.
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// Get RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
val reduceRDD = rdd.groupByKey()
reduceRDD.collect().foreach(println)
sc.stop()
/**
* operation result:
* (a,CompactBuffer(1, 1, 1))
* (b,CompactBuffer(1))
*/
}
As you can see, the returned result is RDD[(String, Iterable[Int])], that is, (a, (1,1,1)), (b, (1,1,1)).
To implement WordCount, one more Map operation is required:
def main(args: Array[String]): Unit = {<!-- -->
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// Get RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
val reduceRDD = rdd.groupByKey().map {<!-- -->
case (word, iter) => {<!-- -->
(word, iter.size)
}
}
reduceRDD.collect().foreach(println)
sc.stop()
/**
* operation result:
* (a,3)
*(b,1)
*/
}
2).reduceByKey implements WordCount
Function: reduceByKey can aggregate data into pairs of Values according to the same Key. This aggregation method needs to be specified.
def main(args: Array[String]): Unit = {<!-- -->
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// Get RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
// Specify the calculation formula as x + y
val reduceRDD = rdd.reduceByKey((x,y) => x + y)
reduceRDD.collect().foreach(println)
sc.stop()
/**
* operation result:
* (a,3)
*(b,1)
*/
}
2. The difference between the two implementation methods of drawing analysis
To facilitate the demonstration of the Shuffle process, it is now assumed that there are two partitions of data.
1) groupByKey implements WordCount

Interpretation:
1. The red RDD is the data source, containing (word, 1) data of two partitions
2.Shuffle process (everyone knows that the Shuffle process requires disk IO)
3. RDD after groupByKey, aggregate Value according to key grouping
4.Map operation to calculate WordCount
2).reduceByKey implements WordCount (simple process)
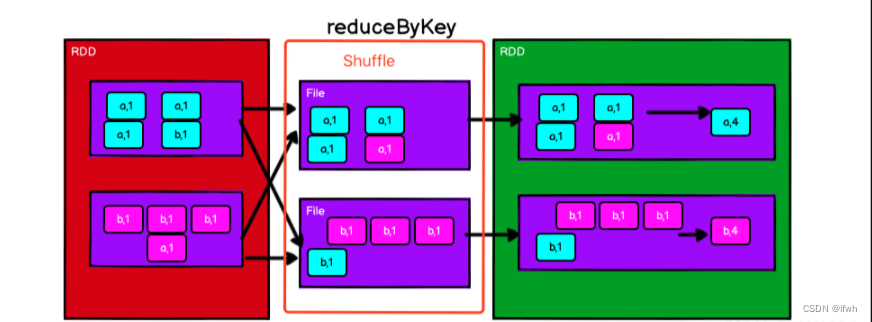
Interpretation:
1. The red RDD is the data source, containing (word, 1) data of two partitions
2.Shuffle process
3. According to the specified aggregation formula, the result of pairwise aggregation of Value is RDD
From this point of view, it seems that the calculation methods of groupbykey and reduceByKey to implement WordCount are similar. In terms of performance, both have Shuffle operations, so there is not much difference in terms of calculation performance; in terms of function, both For grouping, reduceByKey has an aggregation operation, but groupbykey does not have an aggregation operation. Its aggregation is achieved by adding a map operation, so there doesn’t seem to be much difference.
So what is the core difference between the two?
3).reduceByKey implements WordCount (ultimate process)
Let’s introduce the function of reduceByKey again: data can be aggregated in pairs according to the same Key and Value.
Think about a question: Have you found a phenomenon in the picture in 2)? There is the same Key in a partition of the red RDD, and the value can be aggregated. In the implementation process of groupbykey, since groupbykey does not have an aggregation function, the aggregation calculation is implemented by grouping all data and then aggregating it. And reduceByKey has an aggregation function. During the implementation process, the aggregation conditions are also met before grouping (the same key and value can be aggregated). So, does reduceByKey aggregate the data before grouping? (The answer is yes, we call it pre-aggregation operation)
So, its flow chart becomes like this:

Interpretation:
1. The red RDD is the data source, which contains (word, 1) data of two partitions. The data in the partitions are pre-aggregated before grouping
2.Shuffle operation
3. According to the specified aggregation formula, the result of pairwise aggregation of Value is RDD
What changes are there?
1. The data is pre-aggregated before grouping, and the amount of data participating in grouping becomes smaller, that is, the amount of data participating in Shuffle becomes smaller
2. Because the amount of data participating in Shuffle becomes smaller, the number of disk IOs during Shuffle will be reduced
3. The number of quantitative calculations becomes smaller during aggregation calculations
One conclusion can be drawn from this:
reduceByKey supports intra-partition pre-aggregation function, which can effectively reduce the amount of data dropped to disk during Shuffle and improve Shuffle performance.
Summary
If this article is helpful to you, I hope you can
follow,like,collect,comment>Thank you very much for your support!
Please correct me if there is something wrong!!!
Reference 1