Author: Wu Zhuo, Intel AI Evangelist
Speaking of generative AI, it has become popular since last year. I believe that whether you are a developer in the AI field or not, you are no stranger to this concept. Speaking of typical application scenarios and models in the field of generative AI, I believe the first thing that comes to mind is the scenario of Vincentian diagrams, and a series of latent diffusion models (LDMs) behind it. With the powerful capabilities of these models, everyone can become a designer or illustrator and create beautiful pictures by simply inputting a piece of text. However, when calling the Vincent diagram model, if you choose to call the API running on the cloud, you may need to pay and may also face problems such as waiting in line. If you choose to run it on a local machine, it will have higher requirements on the machine’s computing power and memory, and it will also require a long wait. After all, these models often need to be iterated dozens of times before they can generate a relatively beautiful picture. .
Recently, a model called LCMs (Latent Consistency Models) came out, making it possible to quickly generate images of Vincent diagram models. Inspired by Consistency Models (CM), Latent Consistency Models (LCMs) enable fast inference with minimal steps on any pre-trained latent diffusion model, including Stable Diffusion. Consistency models are a new family of generative models that enable one-step or a small number of step generation. The core idea is to learn the function of the solution of PF-ODE (the trajectory of the probability flow of ordinary differential equations). By learning consistent maps that maintain the consistency of points on ODE trajectories, these models allow single-step generation, eliminating the need for computationally intensive iterations. However, CM is limited to the pixel-space image generation task and is therefore not suitable for synthesizing high-resolution images. LCMs employ a consistency model in the image latent space to generate high-resolution images. Think of the guided back-diffusion process as the process of solving PF-ODE. LCMs are designed to directly predict the solution of such ODEs in the latent space, reducing the need for a large number of iterations and enabling fast, high-fidelity sampling. Utilizing image latent space in large-scale diffusion models (such as Stable Diffusion) effectively enhances image generation quality and reduces computational load, making it possible to rapidly generate images. (More details about the proposed method and model can be found on the project page Latent Consistency Models: Synthesizing High-Resolution Images with Few-step Inference, the paper https://arxiv.org/abs/2310.04378 and the original repository GitHub – luosiallen /latent-consistency-model: Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference.)
Of course, our OpenVINO can fully optimize, compress, infer, accelerate and deploy such a magical LCMs Vincent graph model. Next, let us learn more about the specific steps through the Jupyter Notebook code and disassembly of the LCMs model in our commonly used OpenVINO Notebooks warehouse (Jupyter notebook code address https://github.com/openvinotoolkit/openvino_notebooks/tree/ main/notebooks/263-latent-consistency-models-image-generation ).
Step 1: Install the corresponding tool package, load the model and convert to OpenVINO IR format
%pip install -q "torch" --index-url https://download.pytorch.org/whl/cpu %pip install -q "openvino>=2023.1.0" transformers "diffusers>=0.22.0" pillow gradio "nncf>=2.6.0" datasets
- Model download. Similar to the traditional Stable Diffusion pipeline, the LCMs model also contains three models: Text Encoder, U-Net, and VAE Decoder. in
- The Text Encoder model is responsible for creating the conditions for image generation from the text prompt.
- The U-Net model is responsible for the initial denoising of the latent image representation
- Autoencoder (VAE) Decoder is used to decode the latent space into the final image
Therefore, these three models need to be downloaded respectively. Part of the code is as follows:
import gc
import warnings
from pathlib import Path
from diffusers import DiffusionPipeline
warnings.filterwarnings("ignore")
TEXT_ENCODER_OV_PATH = Path("model/text_encoder.xml")
UNET_OV_PATH = Path("model/unet.xml")
VAE_DECODER_OV_PATH = Path("model/vae_decoder.xml")
def load_orginal_pytorch_pipeline_componets(skip_models=False, skip_safety_checker=True):
skip_conversion = (
TEXT_ENCODER_OV_PATH.exists()
and UNET_OV_PATH.exists()
and VAE_DECODER_OV_PATH.exists()
)
(
scheduler,
tokenizer,
feature_extractor,
safety_checker,
text_encoder,
unet,
Vae,
) = load_orginal_pytorch_pipeline_componets(skip_conversion)
- Model conversion includes converting the above three models into OpenVINO IR format.
Step 2: Prepare the inference pipeline based on OpenVINO
The pipeline is shown in the figure below.
The entire pipeline utilizes a latent image representation and a text hint, which is converted into text embeddings through CLIP’s text encoder as input. The initial latent image representation is generated using a random noise generator. Unlike the original Stable Diffusion process, LCMs also use bootstrap scaling to obtain time-step conditional embeddings as input to the diffusion process, whereas in Stable Diffusion it is used to scale the latent representation of the output.
Next, U-Net iteratively denoises random latent image representations while conditioning on text embeddings. The output of U-Net is the noise residual, which is used to calculate the denoised latent image representation through the scheduling algorithm. LCMs introduce their own scheduling algorithm that extends the non-Markov guidance introduced in denoising diffusion probabilistic models (DDPMs). The denoising process will be repeated multiple times (note: the default is 50 times in the original SD process, but forLCM, only small steps of about 2-8 times are needed! ) to gradually obtain better latent image representations. Once completed, the latent image representation will be decoded by the variable VAE decoder into the final image output.

Define classes related to LCMs inference pipeline. Part of the code is as follows:
from typing import Union, Optional, Any, List, Dict
from transformers import CLIPTokenizer, CLIPImageProcessor
from diffusers.pipelines.stable_diffusion.safety_checker import (
StableDiffusionSafetyChecker,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.image_processor import VaeImageProcessor
class OVLatentConsistencyModelPipeline(DiffusionPipeline):
Step 3: Configure the inference pipeline
- First, create an instance of the OpenVINO model and compile it with the selected device. Select the device from the drop-down list to run inference using OpenVINO.
core = ov.Core()
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="CPU",
description="Device:",
disabled=False,
)
device
text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device.value)
unet_model = core.compile_model(UNET_OV_PATH, device.value)
ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device.value, ov_config)
The model tokenizer and scheduler are also important parts of the pipeline. The pipeline can also use a security checker, a filter used to detect whether the corresponding generated images contain “Not Safe for Work” (nsfw) content. The nsfw content detection process requires the use of CLIP models to obtain image embeddings, so additional feature extractor components need to be added to the pipeline. We reuse the tagger, feature extractor, scheduler and security checker from the original LCMs pipeline.
?ov_pipe = OVLatentConsistencyModelPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_model,
vae_decoder=vae_decoder,
scheduler=scheduler,
feature_extractor=feature_extractor,
safety_checker=safety_checker,
)
?
Step 4: Text to image generation
prompt = "a beautiful pink unicorn, 8k"
num_inference_steps = 4
torch.manual_seed(1234567)
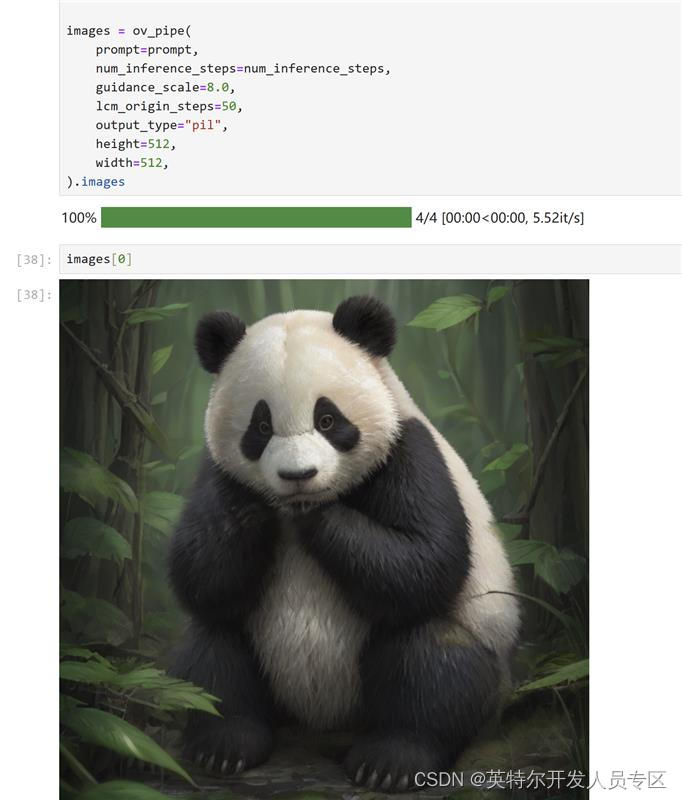
images = ov_pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
).images
On my local machine, I used my 12th generation Core CPU,

And Ruixuan ARC A770m independent graphics card runs model inference, and the picture is generated in the blink of an eye!
Of course, in order to facilitate the use of developers, our notebook code has also designed a more user-optimized interface based on Gradio for everyone.
Step Fifth:UseNNCF Quantitative compression of the model
In addition, if you have further needs for model size compression and memory footprint compression, our notebook also provides code examples for quantitative compression based on NNCF.
The process of quantization compression is divided into the following three steps:
- Create a calibration data set for quantification
- Run nncf.quantize() to get the quantized model
- Use openvino.save_model() to save the model quantized into INT8 format
Part of the code is as follows:
%%skip not $to_quantize.value
importnncf
from nncf.scopes import IgnoredScope
if UNET_INT8_OV_PATH.exists():
print("Loading quantized model")
quantized_unet = core.read_model(UNET_INT8_OV_PATH)
else:
unet = core.read_model(UNET_OV_PATH)
quantized_unet = nncf.quantize(
model=unet,
subset_size=subset_size,
preset=nncf.QuantizationPreset.MIXED,
calibration_dataset=nncf.Dataset(unet_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
advanced_parameters=nncf.AdvancedQuantizationParameters(
disable_bias_correction=True
)
)
ov.save_model(quantized_unet, UNET_INT8_OV_PATH)
The running effect is as follows:

According to the same text prompt, check the generation effect of the quantized model:

Of course, how can the performance in inference time be improved? We also welcome everyone to use the following code to test it on your own machine:
%%skip not $to_quantize.value
import time
validation_size = 10
calibration_dataset = datasets.load_dataset("laion/laion2B-en", split="train", streaming=True).take(validation_size)
validation_data = []
while len(validation_data) < validation_size:
batch = next(iter(calibration_dataset))
prompt = batch["TEXT"]
validation_data.append(prompt)
def calculate_inference_time(pipeline, calibration_dataset):
inference_time = []
pipeline.set_progress_bar_config(disable=True)
for prompt in calibration_dataset:
start = time.perf_counter()
_ = pipeline(
prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
)
end = time.perf_counter()
delta=end-start
inference_time.append(delta)
return np.median(inference_time)
Summary:
That’s the whole process! Start following the code and steps we provide now and try using Open VINO?![]() and LCMs.
and LCMs.
For more information about the Intel OpenVINOTM open source tool suite, including the more than 300 verified and optimized pre-trained models we provide, please click https://www.intel.com/content/www/us/ en/developer/tools/openvino-toolkit/overview.html
In addition, in order to facilitate everyone to understand and quickly master the use of OpenVINOTM, we also provide a series of open source Jupyter notebook demos. By running these notebooks, you can quickly understand how to use OpenVINOTM to implement a series of computer vision, speech and natural language processing tasks in different scenarios. The resources of OpenVINOTM notebooks can be downloaded and installed from GitHub: https://github.com/openvinotoolkit/openvino_notebooks.
The knowledge points of the article match the official knowledge files, and you can further learn related knowledge. OpenCV skill tree Home page Overview 23998 people are learning the system