Look at index structure selection from the comparison of Hash index, binary tree, B-Tree and B + Tree
- 1. Hash structure
-
- 1.1. About Hash data structure
- 1.2. Why not choose Hash structure for InnoDB index?
- 1.3. About InnoDB providing adaptive Hash index (Adaptive Hash Index)
- 2. Binary search tree
- 3. Balanced binary tree (AVL tree)
- 4. B-Tree (B-tree)
- 5. B + Tree (B + tree)
-
- 5.1. B + Tree structure
- 5.2. B + Tree related thinking questions
Data structures can be said to be commonly used by programmers, but most people don’t know why. This article will sort out and summarize several types of data such as Hash, binary search tree, balanced binary tree, B-Tree, and B + Tree.
1. Hash structure
1.1, About Hash data structure
Hash itself is a function, also known as a hash function, which can greatly improve the efficiency of retrieving data.
-
The Hash algorithm converts input into output through a specific algorithm (such as MD5, SHA1, SHA2, SHA3).
The same input can always get the same output. If there is a slight deviation in the input content, there will usually be different results in the output. -
The length of the Hash value is fixed, but the possibility of input data is unlimited. This will cause different input data to be mapped to the same Hash value. This phenomenon is called
Hash collision. -
Common solutions to solve Hash collisions include open addressing method and linked list method. The open addressing method is to try to find the next available slot to store data when a collision occurs.
The linked list rule is to store data mapped to the same Hash value in a linked list, and solve the collision problem through the linked list. -
When the length of the linked list is too long, query efficiency will be reduced. At this time, you canconvert the linked list into a red-black tree to improve query efficiency. The red-black tree is a self-balancing binary search tree that can ensure that the query time complexity in the worst case is O(log n), where n is the number of nodes.

For example: If you want to verify whether two files are the same, you can directly compare the results calculated by the Hash function of the two files. If the results calculated by the Hash function of the two files are the same, the files are the same, otherwise they are different.
There are two common types of data structures that improve query speed:
Tree, for example: balanced binary tree, the average time complexity of query, insertion, modification and deletion is O(log2N).Hash, for example: HashMap, the average time complexity of query, insertion, modification, and deletion is O(1); (key, value)
The retrieval efficiency using Hash is very high, and the data can basically be found in one retrieval. B + Tree needs to be searched from top to bottom, and the data can be found by visiting the nodes multiple times, which requires multiple I/O operations. In terms of efficiency, Hash is faster than B + Tree.
The storage engines applicable to Hash index are as shown in the table:
| Index/storage engine | InnoDB | MyISAM | Memory |
|---|---|---|---|
| Hash index | Not supported | Not supported | Supported< /strong> |
Usage scenarios of Hash index:
-
① When the repetition of fields is low and
equivalent queryis often required, using Hash index is a good choice. -
② The core of Redis storage is the Hash table.
-
③ InnoDB provides Adaptive Hash Index (Adaptive Hash Index)
1.2. Why not choose Hash structure for InnoDB index?
The Hash structure is highly efficient, so why is the index structure of InnoDB designed as a tree?
- Reason ①,
Hash index can only satisfy (=) (<>) and in queries. If a range query is performed, the time complexity will degrade to O(n), and the ordered characteristics of the tree structure can still maintain the high efficiency of O(log2N). - Reason ②,
Hash index has a flaw, the data is stored in no order. In the case of ORDER BY, using Hash index also requires reordering the data. - Reason ③: For joint indexes, the Hash value is calculated by combining the joint index keys, and it is impossible to query a single key or several index keys.
- Reason ④: For equivalent queries, Hash indexes are usually more efficient,
but if there are many duplicate values in the index column, the efficiency will be reduced. Because when a Hash conflict is encountered, it is necessary to traverse the row pointers in the bucket to compare and find the query keyword, which is very time-consuming. Therefore, Hash indexes are often not used on columns with many repeated values, such as gender, age, etc.
1.3. About InnoDB providing adaptive Hash index (Adaptive Hash Index)
If a certain data is frequently accessed, and when certain conditions are met, the address of the data page will be stored in the Hash table. The next time you query, you will directly find the location of the data page. The purpose of using adaptive Hash index is to speed up the positioning of leaf nodes according to SQL query conditions. Especially when the B + Tree is relatively deep and has many levels, adaptive Hash can significantly improve the data retrieval efficiency.
--Query whether adaptive Hash index is enabled, the default is ON, enabled. show variables like '?aptive_hash_index%';

2. Binary search tree
If we use a binary tree as an index structure, the number of disk IOs is related to the height of the index tree.
Characteristics of binary search trees (binary search trees):
A node can only have two child nodes, that is, the degree of a node cannot exceed 2.Left child node.= this node, the one bigger than me goes to the right, the one smaller than me goes to the left
Search rules for binary search trees:
Binary Search Tree (Binary Search Tree), the rules for searching a node are the same as inserting a node, assuming that the value to be searched and inserted is the key:
- ① If key is greater than the root node, search in the right subtree;
- ② If key is less than the root node, search in the left subtree;
- ③ If key is equal to the root node, that is, the node is found and the root node is returned.
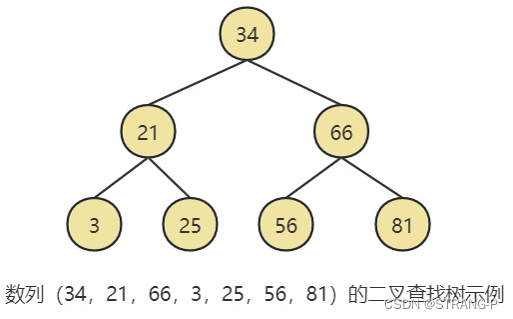

The binary search tree may degenerate into a linked list, and the time complexity of searching for data is O(N), as shown below:

3. Balanced binary tree (AVL tree)
In order to solve the problem that the binary search tree may degenerate into a linked list, the Balanced Binary Tree appeared, also known as the AVL tree (different from the AVL algorithm). It is based on the binary search tree and adds some Constraints: The balanced binary tree is an empty tree, or the absolute value of the height difference between its left and right subtrees does not exceed 1, and the left and right subtrees are both balanced binary trees.
Common balanced binary trees include: Balanced Binary Search Tree, Red-Black Tree, Number Heap, Stretch Tree. Generally, balanced binary trees refer to balanced binary search trees. The time complexity of search is O(log2n). The time of data query mainly depends on the number of disk I/Os. , when n is larger, the query becomes more complex.
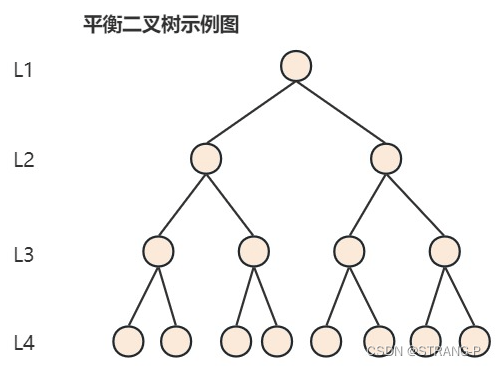
Each time a node is accessed, a disk I/O operation is required. In the example above, 4 I/O operations are required. Although the efficiency of balanced binary trees is high, when the depth of the tree is relatively high, it also means that the number of disk I/O operations is high, which will affect the overall data query efficiency.
4. B-Tree (B-tree)
B-Tree (Balance Tree) is a multi-way balanced search tree, abbreviated as B-Tree (the horizontal bar here is a connector, not a minus sign). The height of a B-Tree is much smaller than the height of a balanced binary tree. The key points of B-Tree are as follows:
-
When B-Tree inserts or deletes nodes, if the tree is unbalanced, it will automatically adjust the position of the nodes to maintain the self-balancing of the tree.
-
The keyword set is distributed throughout the tree. If a magnetic block contains x keywords, the number of pointers is x + 1, and
both leaf nodes and non-leaf nodes store data. The search may end at a non-leaf node. -
The search performance is equivalent to doing a binary search in the complete set of keywords.
-
For a B-Tree of order M (each node can include up to M child nodes), the range of the number of children of the root node is [2, M], and all leaf nodes are on the same level.


Suppose the query key is 8 data.
- ① Compare with the keywords 26 and 36 of the root node, 8 is less than 26, take the P1 pointer of magnetic block 1 and search for the lower node.
- ② Find magnetic block 2 according to the P1 pointer of magnetic block 1, compare the keywords 6 and 21, 8 is greater than 6 and less than 21, take the P2 pointer of magnetic block 2 and search for the lower node.
- ③ Press the P2 pointer of magnetic block 2 to find magnetic block 6, compare keywords 8 and 18 of magnetic block 6, and find keyword 8.
In B-Tree search, the data is read out and then compared in memory, and the comparison time is negligible. Reading the disk block itself requires an I/O operation, which consumes more time than comparing in memory, and is an important factor in data search time. Compared with balanced binary trees, B-Tree has fewer disk I/O operations and is more efficient. As long as the height of the tree is low enough and the number of I/Os is small enough, query performance can be improved.
5. B + Tree (B + tree)
5.1, B + Tree structure
B + Tree is a multi-path search tree, which is improved based on B-Tree. Mainstream DBMS supports B + Tree indexing method. B + Tree has advantages over B-Tree in terms of query efficiency, disk read and write performance, and range queries. B + Tree is more suitable for file index systems than B-Tree.

The difference between B+Tree and B-Tree is mainly reflected in the following three aspects:
-
① How internal nodes store data: Each internal node of B-Tree stores data, while the internal nodes of B+Tree do not store data and are only used as indexes. The data are stored in leaf nodes. superior. Because B + Tree only stores data in leaf nodes, it has better stability and faster query speed.
-
② Linking method of leaf nodes: The leaf nodes of B + Tree are connected through pointers to form an ordered linked list, which facilitates range queries. The leaf nodes of B-Tree are not connected. When B-Tree performs range query, it needs to be implemented through in-order traversal. In range queries, B + Tree is more efficient than B-Tree.
-
③ Disk read and write performance: Compared with B-Tree, B + Tree has more advantages in disk read and write performance. This is because the internal nodes of B+Tree do not have pointers to specific information about keywords, so their internal nodes are smaller than B-Tree. If internal nodes and leaf nodes are stored in the same disk, then the number of nodes contained in the disk block will The number is larger than that of B-Tree, and the more keywords that need to be searched are read into the memory at one time, and the number of IO reads and writes is relatively reduced.
5.2, B + Tree related thinking questions
1. In order to reduce IO, will the B + Tree index tree be loaded at once?
- ① The database index is stored on the disk. If the amount of data is too large, the size of the index will inevitably be large, exceeding several G.
- ② When using index query, it is impossible to load all several G of index data into the memory. Each disk page can only be loaded one by one, so the disk page corresponds to the node of the index tree.
2. What is the storage capacity of B + Tree? Why is it said that generally searching for row records only requires 1 to 3 disk IOs at most?
The default size of the data page in the InnoDB storage engine is 16KB. The primary key type of the general table is int (occupying 4 bytes) or bigint (occupying 8 bytes). The pointer type is generally 4 or 8 bytes, so a The data page of the root node or internal node (a node in B + Tree) stores approximately 16KB/(8B + 8B) = 1K key values. To estimate, if the value of K is 10^3, the data that a B + Tree index with a depth of 3 can maintain is 10^3 * 10^3 * 10^2 = 100 million records (assuming a leaf here The data page of the node can store 100 rows of record data).
In actual situations, each node may not be fully filled, so
in the database, the height of B + Tree is generally 2~4 levels. When MySQL’sInnoDB storage engine is designed, the root node is resident in memory, which means that when searching for a row record of a certain key value, only 1 to 3 disk IO operations are required at most.
3. Why is B+Tree more suitable than B-Tree for file indexing and database indexing of operating systems in practical applications?
B + Tree’s disk read and write costs are lowerThe internal nodes of B + Tree do not have pointers to specific information about keywords, so their internal nodes are smaller than B-Tree. In layman’s terms, B-Tree stores row data in nodes at each level, but B+Tree only stores row data in leaf nodes, and inner nodes store primary keys or non-clustered index fields, so generally speaking, the same data In terms of volume, the level of B + Tree will be lower, the number of disk IO operations will be fewer, and the disk read and write costs will be lower.
B + Tree’s query efficiency is more stableOnly the leaf nodes of B + Tree will have user record row data, so any keyword search must take a path from the root node to the leaf node. The path length of all keyword queries is the same, resulting in the query efficiency of each data being equivalent. .
4. What is the difference between Hash index and B + Tree index?
① Hash index cannot perform range query, but B + Tree can.
② Hash index does not support the leftmost principle of joint index (that is, part of the joint index cannot be used), but B + Tree can.
③ Hash index does not support ORDER BY sorting, but B + Tree can (B + Tree index data is ordered).
④ Hash index does not support fuzzy query. When B + Tree uses LIKE for fuzzy query, the fuzzy query after LIKE (such as ending with %) can play an optimization role.
⑤ InnoDB does not support hash index, but provides adaptive Hash index (Adaptive Hash Index).
5. Are Hash index and B + Tree index manually specified during key indexing?
For MySQL, the InnoDB and MyISAM storage engines use B + Tree indexes by default, and Hash indexes cannot be used. The adaptive Hash provided by InnoDB does not need to be manually specified. If you use Memory/Heap and NDB storage engines, you can choose Hash index.
Series of articles:
1: “Understanding the architecture and execution process of MySql”
Two: “Understanding the index from the data structure of the InnoDB index”
Three: “Look at index structure selection from the comparison of Hash index, binary tree, B-Tree and B + Tree”
Four: “MySQL Index Classification and Design Principles”
Five: “MySQL Optimization Ideas”
Six: “Understanding MySQL log redo, undo, binlog”
Seven: “Problems that may occur at different isolation levels under concurrent transactions”
Eight: “Multi-dimensional sorting out MySQL locks”
Nine: “MySQL Multi-version Concurrency Control MVCC”
.