Article directory
- Preface
-
- Example: Google classic interview questions
- The principle and implementation of dictionary tree
-
- definition
- Dictionary tree structure
- Dictionary tree operations
-
- String insertion
- String query
- Implementation of dictionary tree
-
- Character set array method
-
- Node class structure design
-
- Node interface
- character map
- Code implementation of node class
- Dictionary tree structure design
-
- Dictionary tree interface implementation
- Character set mapping method (wide applicability)
-
- Node class structure design
-
- Code implementation of node class
- Dictionary tree structure design
Foreword
We have learned many string query algorithms, such as Baosou, KMP, BM, RK and other string matching algorithms. These are all used to find our pattern strings in text. When we enter in the input field of the search engine, we often only enter the prefix. Here are several search terms containing this prefix. Is this also our string matching algorithm? By studying the dictionary tree Trie, I believe you will understand this.
Example: Google classic interview questions
Classic interview questions: Search tips (auto-complete)

How to extract some keywords that the user may want from our corpus based on the keywords entered by the user and present them to the user?
Use a dictionary tree to store some corpora, and give us the corresponding string according to the prefix entered by the user.
The principle and implementation of dictionary trees
Definition
Dictionary tree, also known as trie tree, is a tree-shaped data structure. It can be used as word frequency statistics and uses the common prefix of strings to reduce query time. Generally used to find whether a certain string S is in a string collection.
The structure of the dictionary tree
Suppose we use a dictionary tree to store the following word set: to, a, tea, ted, test, ice
Then the corresponding dictionary tree is as follows:
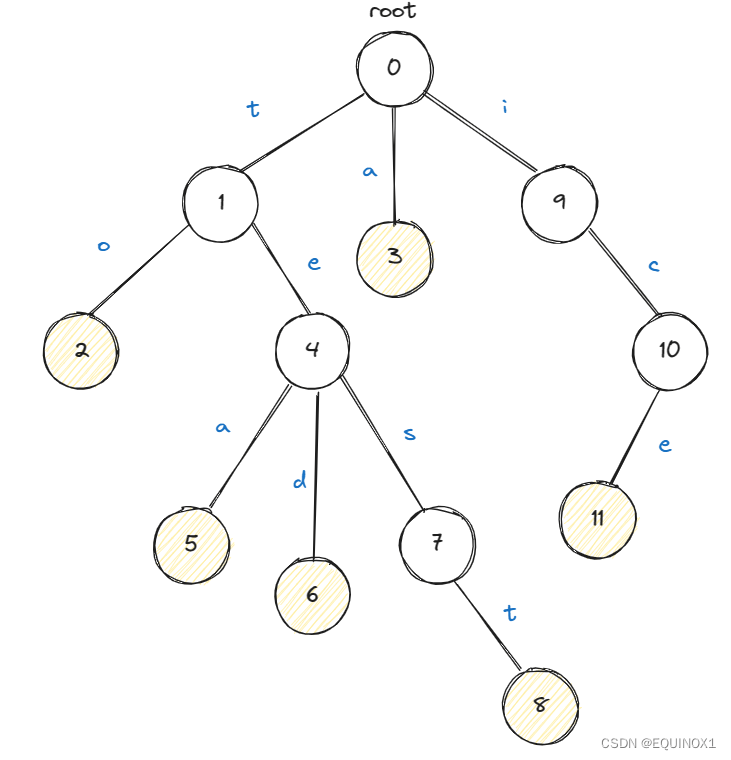
For the picture above:
- Each node has a corresponding subscript for easy access
- The subscript starts from 0, and root is marked with 0
- Nodes do not store characters, edges store characters
- The yellow node indicates that the string ends at the node
Dictionary tree operations
Dictionary trees generally provide two operations, insertion and deletion, which only require one traversal of the string.
String insertion
The insertion of a string is the traversal of the string.
The insertion algorithm is implemented as follows:
- Define the current node as the root node root of the dictionary tree, and traverse the given string s;
- For the i-th character s[i] of the string, query whether the current node has the child node s[i];
- If it does not exist, create a new node;
- If it exists, it will not be processed;
- Update the current node to the i-numbered child node of the original current node;
- After traversing the string s, put a mark on the current node to identify the end node;
Taking the previous example as an example, the following animation shows the string insertion process:

Initially, there is only one root node. The first inserted string is “to”, and the root is expanded into the following single-chain structure.

Insert “a”. Since root does not have an ‘a’ child node, another ‘a’ is created.

Insert “tea”. Due to the existence of the common prefix “t”, we only need to create additional ‘e’, ‘a’

Similar for “ted” and “test”

Insert “ice”

In this way, the construction of our Trie is completed. Assume that the string length is m, and a total of n insertions are made. The time complexity of each insertion is O(m). The total time complexity is O(nm)
String query
The query of a string is also a traversal of the string.
The query algorithm is implemented as follows:
- Define the current node cur as the root node root of the dictionary tree, and traverse the given string s;
- For the i-th character s[i] of the string, query whether the current node has the child node s[i];
- If it does not exist, return false;
- If it exists, it will not be processed;
- Update the current node to the i-numbered child node of the original current node;
- After traversing the string s, determine whether there is an end mark for the current node cur. If it exists, it returns true, otherwise it returns
false;
We still use the previous dictionary tree as an example to query “test”. We first search for ‘t’ from the root, reach node 1, then search for ‘e’ at node 1, reach node 4, and then search for ‘s’ at node 4. Reach node 7, then search for ‘t’ at node 7, and reach node 8. At this point, the string traversal ends, and node 8 has an end mark, so “test” is in the dictionary tree

But if we query “tes”, we find that it ends at node 7, but node 7 has no end mark, so “tes” is not in the dictionary tree.

Implementation of dictionary tree
Our characters are sometimes uppercase and lowercase letters, sometimes numbers, and sometimes both are used. But for different situations, we can choose a more suitable Trie implementation. Here we introduce two types: character set array method and character set Mapping method.
Character set array method
Each node saves an array with a length fixed to the character set size (for example, 26), with characters as subscripts, and saves the subscript of the node pointed to (the pointer is not stored because the pointer is 8 bytes on the 64-bit platform, and int Only 4 bytes), the space complexity is O (number of nodes * character set size), and the time complexity of the query is O (word length)
Suitable for smaller character sets, or dictionaries with short words and dense distribution
For dictionary trees, we need to design two classes: node class and dictionary tree class.
Node class structure design
For the node class, we need to store three pieces of information: end tag, word frequency statistics, and child node array.
Here is a special explanation for the child node array. The child node array can directly store the address of the child node. This is a relatively simple and intuitive implementation method.
But here I put all the created nodes in an array in the dictionary tree class, so that we can complete the indirect indexing of the child nodes by storing the subscripts of the child nodes in the node, because on the 64-bit platform, int is 4 bytes, while the pointer is 8 bytes, which saves space.
The code is defined as follows:
template <class HashFunc>//Character subscript mapping, discussed later
struct TrieNode
{
TrieNode();//Constructor
bool isexist(int idx);//Subnode query
bool isword();//Whether the current node is the end of a word
void addnode(int idx, int node_idx);//Add a child node, the subscript of the child node is node_idx
int getNode(int idx);//Get the subscript of the child node
void setword();//Set to the end of the word
void addcnt();//Increase word frequency
bool _isword;//Word end mark
int _cnt;//word frequency
vector<int> _nodes;//array of child nodes
};
- _isword is the word end mark, a bool type variable. After completing the insertion of a string, the corresponding end node is marked as true.
- Let the string from the root node to the current node be s, then _cnt is the number of strings prefixed with s in the dictionary tree
- _nodes is a continuous array that stores the subscript of each child node.
Node interface
| Interface name | Interface description |
|---|---|
| isexist | Judge whether the character corresponding to idx is in the child node |
| isword | Judge whether the current node is the end of a word |
| addnode | Add the child node of the character corresponding to idx |
| getnode | Get the child node pointer of the character corresponding to idx |
| setword | Set the current node to the end of the word |
Character mapping
Characters have corresponding ASCII values, which obviously cannot be used directly as subscripts. They usually need to be converted. We choose to encapsulate the corresponding mapping method into a functor, and then use the functor selection as our template parameter, thus achieving generalized.
Lowercase subscript mapping
typedef struct HashLower // Lowercase letter mapping
{
int operator()(char ch)
{
return ch - 'a';
}
static const int _capacity;
} Lower;
Capital letter subscript mapping
typedef struct HashUpper // Uppercase letter mapping
{
int operator()(char ch)
{
return ch - 'A';
}
static const int _capacity;
} Upper;
Mixed case subscript mapping
typedef struct Hash_U_L // Mixed mapping of upper and lower case letters
{
int operator()(char ch)
{
if (ch >= 'a' & amp; & amp; ch <= 'z')
return ch - 'a';
return ch - 'A' + 26;
}
static const int _capacity;
}U_L;
Numeric character subscript mapping
typedef struct HashDigit // digital character mapping
{
int operator()(char ch)
{
return ch ^ 48;
}
static const int _capacity;
} Digit;
Settings for mapping capacity
We found that several functors store a static integer constant such as _capacity. This is because there are 26 uppercase and lowercase letters each, and there are 52 mixed uppercase and lowercase letters, and only 10 numeric characters, so they are different. Character selection corresponds to different capacities, and this problem can be solved well by setting static variable storage capacity in different functors. The maintainability of class methods is also very strong.
const int HashLower::_capacity = 26; const int HashUpper::_capacity = 26; const int Hash_U_L::_capacity = 52; const int HashDigit::_capacity = 10;
Code implementation of node class
template <class HashFunc>
struct TrieNode
{
TrieNode() : _isword(false), _cnt(0), _nodes(HashFunc::_capacity, -1)
{
}
~TrieNode()
{
}
bool isexist(int idx)
{
return _nodes[idx] != -1;
}
bool isword()
{
return _isword;
}
void addnode(int idx, int node_idx)
{
_nodes[idx] = node_idx;
}
int getNode(int idx)
{
return _nodes[idx];
}
void setword()
{
_isword = true;
}
void addcnt()
{
_cnt + + ;
}
bool _isword;
int _cnt;
vector<int> _nodes;
};
Dictionary tree structure design
template <class HashFunc>
class Trie
{
private:
HashFunc hash_id;//Character mapping used
typedef TrieNode<HashFunc> Node;
public:
Trie(): _root(1, Node())//Initialize the root node
{
}
void insert(const string & amp;str);//Insert string
bool search(const string & amp;str);//String query
Node *root();//Encapsulate the root node
Node *to_Node(int node_idx);//Get the node with the subscript node_idx
Node *genNode(int curidx);//Generate a new node and return the node address subscripted by curidx
private:
vector<Node>_root;
};
| Interface | Interface description |
|---|---|
| insert | Insert string |
| search | String query |
| root | Encapsulate the root node |
| to_Node | Get the node with the subscript node_idx |
| genNode | Generate a new node and return the node address of curidx subscript |
Dictionary tree interface implementation
Insert
The insertion algorithm has been described previously, so just look at the code.
Traverse the string, create a node if there is no corresponding character in the child node, move the current node to the child node, and increase the word frequency
Here is an explanation of why cur needs to be repositioned every time a node is created, because vector is a container that dynamically increases its capacity. The bottom layer uses T* for storage. Each time the capacity is increased, the original elements will be destructed and re-created. As a result, our cur may become invalid, so we need to relocate it. (In fact, you can directly use Node* instead of vector, just pay attention to increasing the capacity. I have obsessive-compulsive disorder here and like to use vector, but it is actually not very good)
void insert(const string & amp;str)
{
int idx, curidx = 0;
Node *cur = root();
for (auto ch : str)
{
idx = hash_id(ch);
if (!cur->isexist(idx))
{
cur = genNode(curidx);
cur->addnode(idx, _root.size() - 1);
}
curidx = cur->getNode(idx);
cur = to_Node(curidx);
cur->addcnt();
}
cur->setword();
}
Query
Traverse the string and determine whether it exists
bool search(const string & amp;str)
{
int idx;
Node *cur = root();
for (auto ch : str)
{
idx = hash_id(ch);
if (!cur->isexist(idx))
{
return false;
}
cur = to_Node(cur->getNode(idx));
}
return cur->isword();
}
Other simple interfaces are given directly
Node *root()
{
return &_root[0];
}
Node *to_Node(int node_idx)
{
return &_root[node_idx];
}
Node *genNode(int curidx)
{
_root.emplace_back(Node());
return &_root[curidx];
}
Character set mapping method (wide applicability)
Although the previous character set array method has been generalized, its applicability is still somewhat limited. The character set array on each node is changed to a map (unordered_map), and the space complexity is O (total number of text characters). , the time complexity of the query is O (word length), but the constant is slightly larger and has wider applicability.
Node class structure design
struct TrieNode
{
TrieNode();//Constructor
bool isexist(int idx);//Subnode query
bool isword();//Whether the current node is the end of a word
void addnode(int idx, int node_idx);//Add a child node, the subscript of the child node is node_idx
int getNode(int idx);//Get the subscript of the child node
void setword();//Set to the end of the word
void addcnt();//Increase word frequency
bool _isword;//Word end mark
int _cnt;//word frequency
unordered_map<char, int> _nodes;//child node mapping
};
_nodes has been changed from numbers to mappings, so there is no need for HashFunc to map character subscripts, nor does it need to handle capacity separately.
Code implementation of node class
Since the code is basically the same as before, the code is given directly.
struct TrieNode
{
TrieNode() : _isword(false), _cnt(0)
{
}
~TrieNode()
{
}
bool isexist(char ch)
{
return _nodes.count(ch);
}
bool isword()
{
return _isword;
}
void addnode(char ch, int node_idx)
{
_nodes[ch] = node_idx;
}
int getNode(char ch)
{
return _nodes[ch];
}
void setword()
{
_isword = true;
}
void addcnt()
{
_cnt + + ;
}
bool _isword;
int _cnt;
unordered_map<char, int> _nodes;
};
Dictionary tree structure design
Similarly, the dictionary tree class just deletes the mapping functor.
class Trie
{
private:
typedef TrieNode Node;
public:
Trie() : _root(1, Node())
{
}
void insert(const string &str)
{
int idx, curidx = 0;
Node *cur = root();
for (auto ch : str)
{
if (!cur->isexist(ch))
{
cur = genNode(curidx);
cur->addnode(ch, _root.size() - 1);
}
curidx = cur->getNode(ch);
cur = to_Node(curidx);
cur->addcnt();
}
cur->setword();
}
bool search(const string &str)
{
int idx;
Node *cur = root();
for (auto ch : str)
{
if (!cur->isexist(ch))
{
return false;
}
cur = to_Node(cur->getNode(ch));
}
return cur->isword();
}
Node *root()
{
return &_root[0];
}
Node *to_Node(int node_idx)
{
return &_root[node_idx];
}
Node *genNode(int curidx)
{
_root.emplace_back(Node());
return &_root[curidx];
}
private:
vector<Node>_root;
};