Springboot uses pdfbox to extract PDF images
- Introduction to PDFBox
- Springboot integrates PDFBox
- 1. Extract the pdf home page as an image
-
- 1. Realize the requirements
- 2. Item code
- 3. Execution result
- 2. Convert all pdf content to images
-
- 1. Realize the requirements
- 2. Item code
- 3. Execution result
- 4. Precautions
-
- 1. Optimize project code
- 2. Increase Java heap size
Introduction to PDFBox
PDFBox is a Java library for creating and manipulating PDF documents. It can create, read, modify and extract content from PDF documents using Java code.
Features of PDFBox:
Extract Text – With PDFBox you can extract Unicode text from PDF files.
Split & Merge – With PDFBox you can split a single PDF file into multiple files and merge them into one.
Fill Forms – With PDFBox you can fill form data in documents.
Print – With PDFBox you can print PDF files using the standard Java printing API.
Save as Image – With PDFBox you can save a PDF as an image file such as PNG or JPEG.
Create PDFs – Using PDFBox, you can create new PDF files by creating Java programs, which can also include images and fonts.
Signing – With PDFBox you can add digital signatures to PDF files.
Springboot integrates PDFBox
In addition to the dependency of pdfbox, this project also introduces other dependencies to solve image problems.
For example: jai-imageio-jpeg2000 and jai-imageio-core are to solve the error when converting images: Cannot read JPEG2000 image: Java Advanced Imaging (JAI) Image I/O Tools are not installed
The jbig2-imageio dependency is introduced to solve the background report Cannot read JBIG2 image: jbig2-imageio is not installed error when using pdfbox2.0 to convert PDF to image
<!-- pdf extraction cover dependency -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.22</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.22</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jbig2-imageio</artifactId>
<version>3.0.2</version>
</dependency>
<!-- Solve the problem of failure to extract pdf "Cannot read JPEG2000 image" cover -->
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-core</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-jpeg2000</artifactId>
<version>1.3.0</version>
</dependency>
1. Extract the pdf homepage as an image
1. Realize requirements
Extract the first page of pdf individually or in batches as the cover, or extract specified pdf pages as images
2. Item code
Core tool class method: PdfUtils.getPdfFirstImage
package com.zhouquan.utils;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.IOException;
/**
* @author ZhouQuan
* @description pdf tool class
* @date 2023/6/17 9:52
*/
@Slf4j
public class PdfUtils {<!-- -->
/**
* Extract the first page of the pdf as the cover
*
* @param pdfFile
* @param dpi the DPI (dots per inch) to render at
* @return
*/
public static BufferedImage getPdfFirstImage(File pdfFile, float dpi) {<!-- -->
long startTime = System. currentTimeMillis();
if (!pdfFile.isFile() || !pdfFile.exists()) {<!-- -->
return null;
}
try (PDDocument document = PDDocument. load(pdfFile)) {<!-- -->
PDFRenderer pdfRenderer = new PDFRenderer(document);
// Set the number of pages (the first page starts from 0), dots per inch, picture type
BufferedImage bufferedImage = pdfRenderer.renderImageWithDPI(0, dpi, ImageType.RGB);
log.info("Extraction time: {}ms", System.currentTimeMillis() - startTime);
return bufferedImage;
} catch (Exception e) {<!-- -->
log. error(e. getMessage());
e.printStackTrace();
return null;
}
}
}
The service method class is responsible for writing the bufferedImage object of the read pdf into the specified image object
package com.zhouquan.service.impl;
import com.zhouquan.service.PdfService;
import com.zhouquan.utils.PdfUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.apache.pdfbox.tools.imageio.ImageIOUtil;
import org.springframework.stereotype.Service;
import java.awt.image.BufferedImage;
import java.io.File;
/**
* @author ZhouQuan
* @description pdf extracts related classes
* @date 2023/6/17 9:40
*/
@Slf4j
@Service
public class PdfServiceImpl implements PdfService {<!-- -->
/**
* Extract the storage path of the cover
*/
private static String coverPath = "D:/pdf_test/cover";
/**
* Extract the file suffix of the cover
*/
private static final String coverExt = "png";
/**
* pdf extract cover
*
* @param pdfFile pdf file
*/
@Override
public void pickupCover(File pdfFile) {<!-- -->
//The DPI (dots per inch) to be rendered can be understood as the definition of the generated image, the higher the value, the higher the generated quality
int dpi = 300;
try {<!-- -->
//Extract the cover tool class
BufferedImage bufferedImage = PdfUtils.getPdfFirstImage(pdfFile, dpi);
//Get the pdf file name
String fileName = FilenameUtils. getBaseName(pdfFile. getName());
String currentCoverPath = coverPath + "/" + fileName + "." + coverExt;
// Create image file object
FileUtils.createParentDirectories(new File(currentCoverPath));
// write the image to the image object
ImageIOUtil.writeImage(bufferedImage, currentCoverPath, dpi);
byte[] coverByte = PdfUtils.bufferedImageToByteArray(bufferedImage);
log.info("The extracted cover size is: {}MB", String.format("%.2f", coverByte.length / 1024 / 1024.0));
} catch (Exception e) {<!-- -->
log. error(e. getMessage());
}
}
}
test class
package com.zhouquan;
import com.zhouquan.service.PdfService;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.io.File;
@SpringBootTest
public class PdfTests {<!-- -->
@Resource
public PdfService pdfService;
/**
* Extract single file cover
*/
@Test
public void pickupCover() {<!-- -->
String pdfFilePath = "D:/pdf_test/pdf/Three-Body Trilogy-Liu Cixin.pdf";
pdfService.pickupCover(new File(pdfFilePath), 0);
}
/**
* Batch single file cover
*/
@Test
public void batchPickupCover() {<!-- -->
String pdfFilePath = "E:/Development Project/h Chemical Press/opt";
File[] files = new File(pdfFilePath).listFiles();
if (files != null & amp; & amp; files. length > 0) {<!-- -->
for (File file : files) {<!-- -->
pdfService.pickupCover(file, 0);
}
}
}
}
3. Execution result
1. Extract the cover of a single pdf
 2. Batch extract pdf cover
2. Batch extract pdf cover
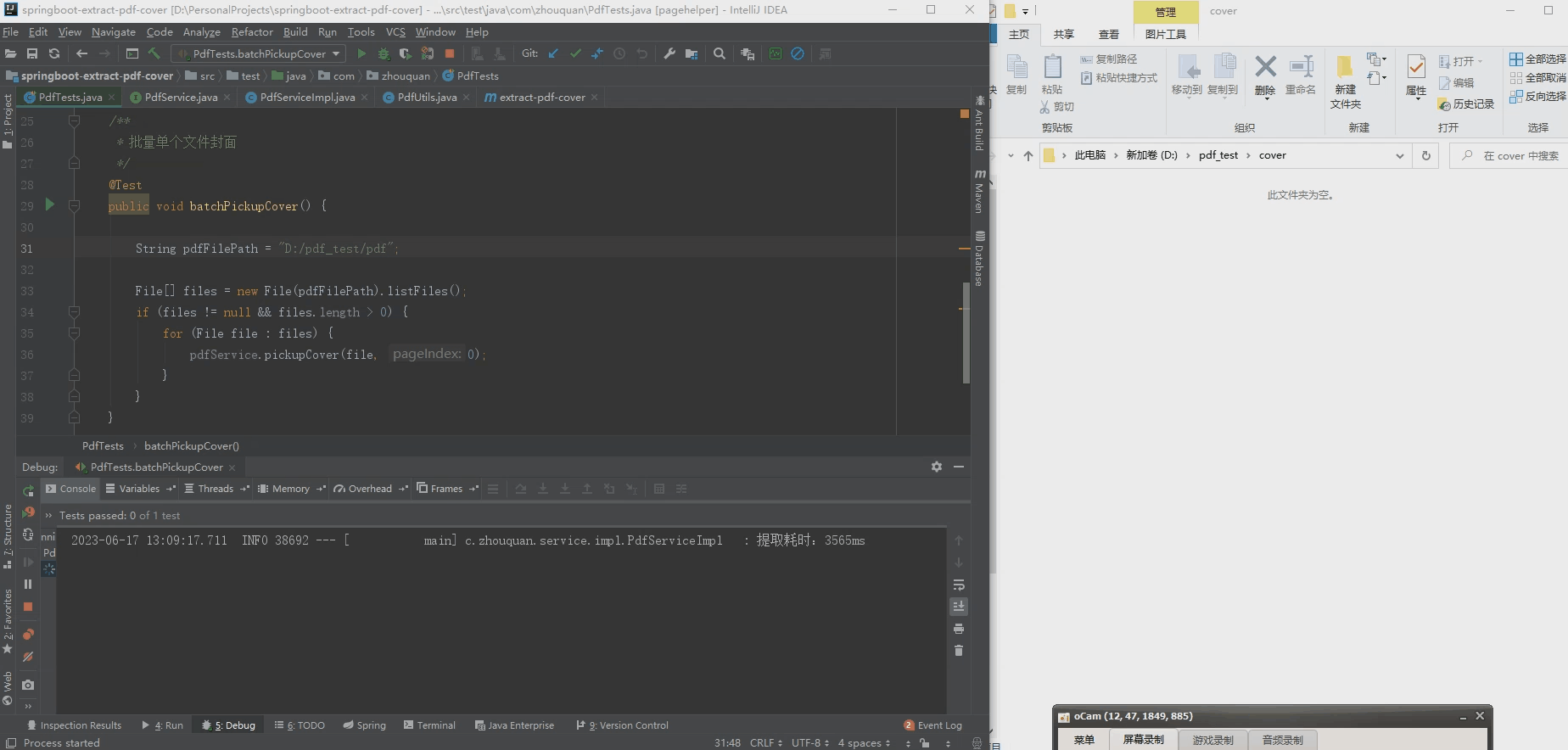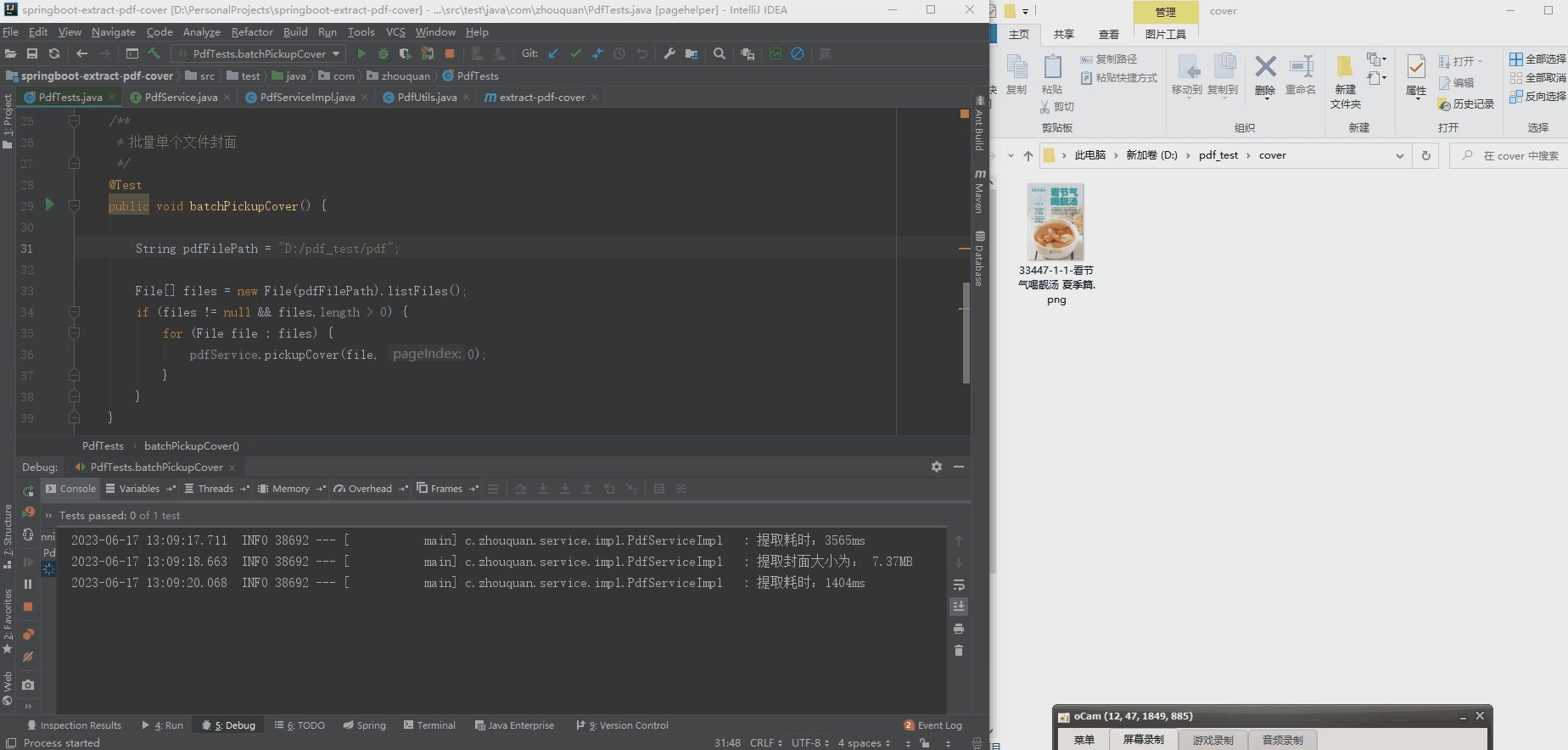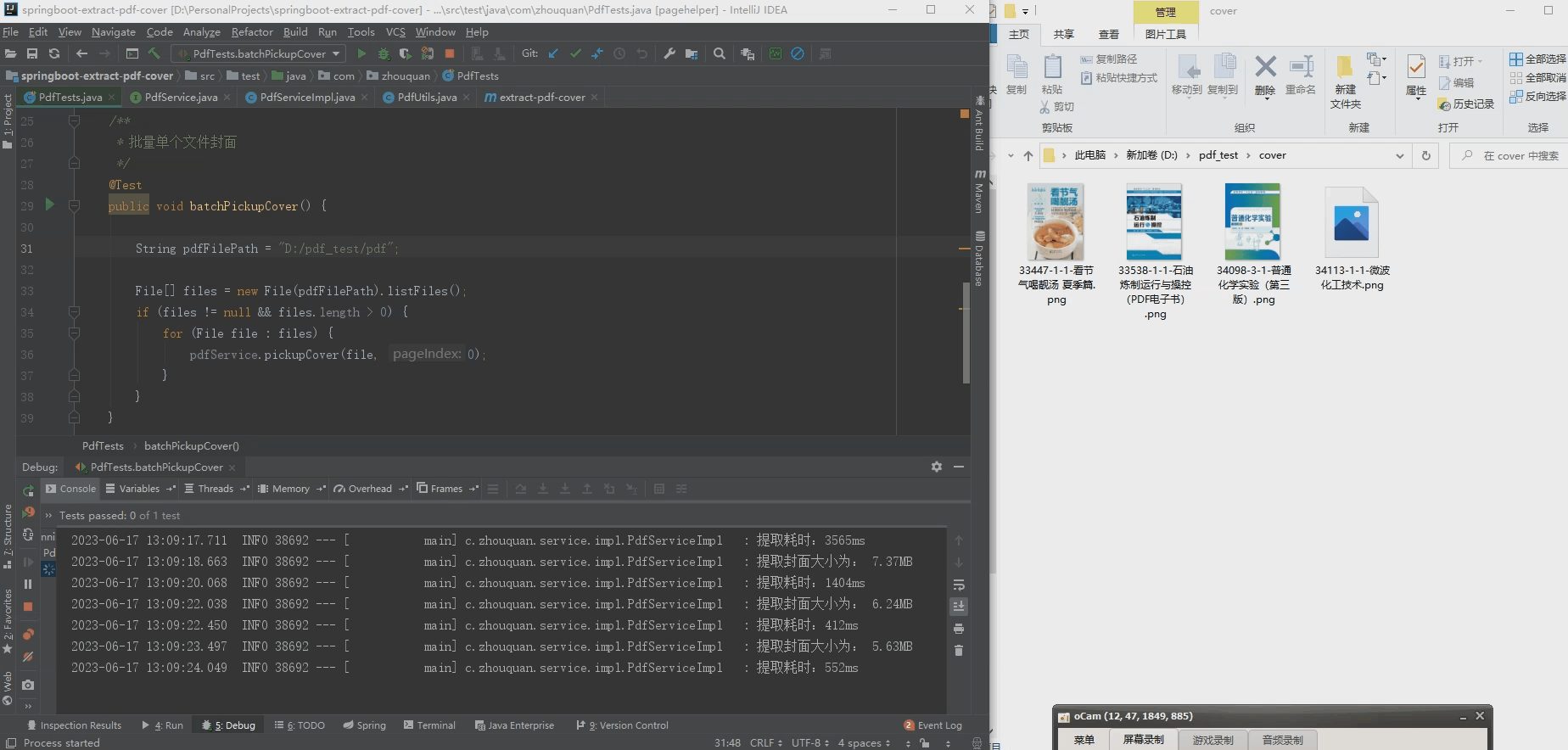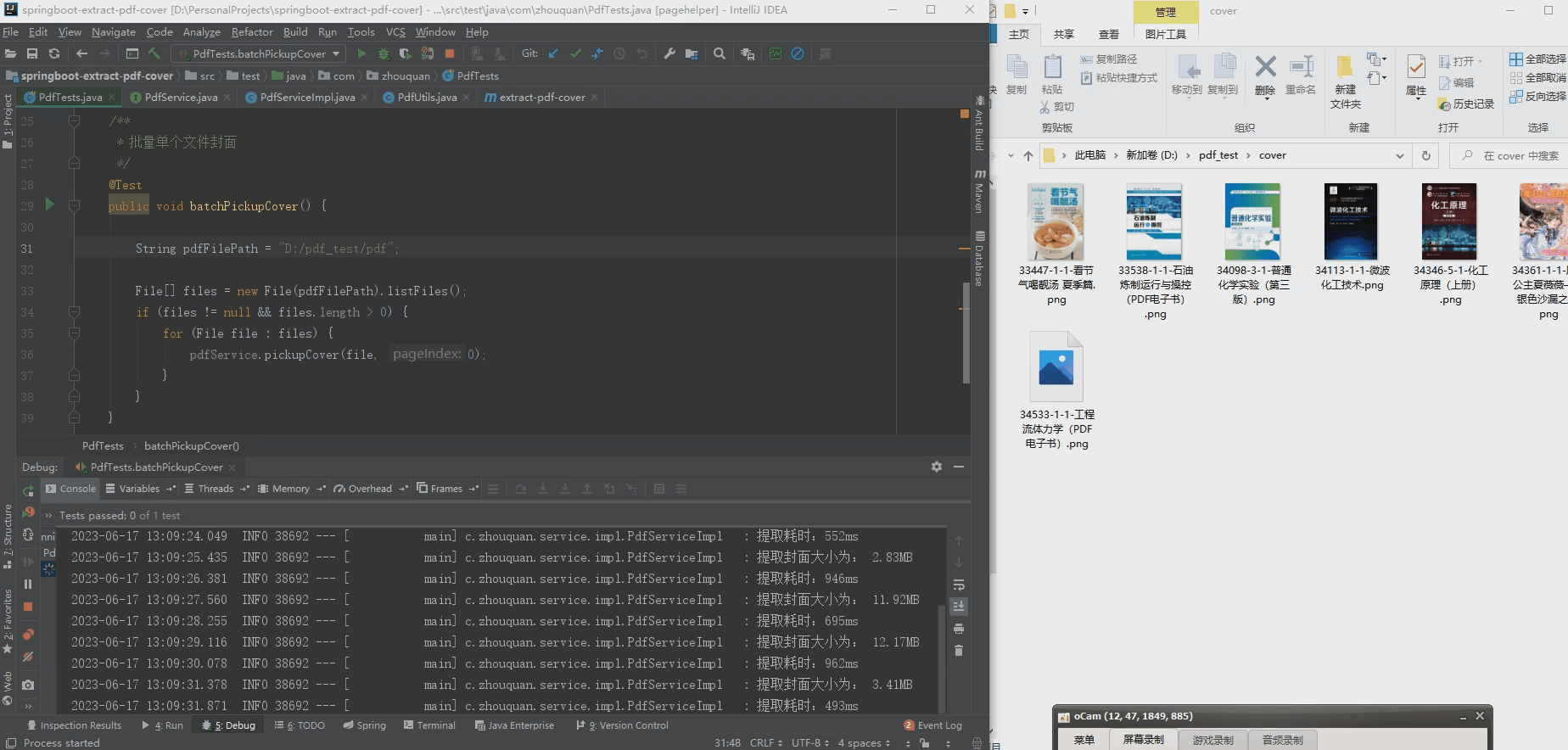
2. Convert all pdf content to images
1. Realize requirements
Convert all pages in pdf to images
2. Item code
Core tool class method: PdfUtils.getPdfAllImage
/**
* Load and read pdf and return all BufferedImage objects
*
* @param pdfFile pdf file object
* @param dpi the DPI (dots per inch) to render at
* @return
*/
public static List<BufferedImage> getPdfAllImage(File pdfFile, float dpi) {<!-- -->
if (!pdfFile.isFile() || !pdfFile.exists()) {<!-- -->
return null;
}
//Create a PDFDocument object and load the PDF file
try (PDDocument document = PDDocument. load(pdfFile)) {<!-- -->
//Create a PDFRenderer object and pass the PDDocument object to it
PDFRenderer pdfRenderer = new PDFRenderer(document);
List<BufferedImage> bufferedImages = new ArrayList<>();
BufferedImage bufferedImage;
for (int pageIndex = 0; pageIndex < document. getNumberOfPages(); pageIndex ++ ) {<!-- -->
System.out.println("pageIndex:" + pageIndex);
// Set the number of pages (the first page starts from 0), dots per inch, picture type
bufferedImage = pdfRenderer.renderImageWithDPI(pageIndex, dpi, ImageType.RGB);
bufferedImages.add(bufferedImage);
}
return bufferedImages;
} catch (Exception e) {<!-- -->
log. error(e. getMessage());
e.printStackTrace();
return null;
}
}
The service method class is responsible for writing the bufferedImage list objects of the read pdf into the image files in the specified directory in order
@Override
public void pickupPdfToImage(File pdfFile) {<!-- -->
//The DPI (dots per inch) to be rendered can be understood as the definition of the generated image, the higher the value, the higher the generated quality
int dpi = 100;
try {<!-- -->
//Extract the cover tool class
List<BufferedImage> pdfAllImage = PdfUtils.getPdfAllImage(pdfFile, dpi);
log.info("Extracted to {} page",pdfAllImage.size());
String fileName = FilenameUtils. getBaseName(pdfFile. getName());
String currentCoverPath;
for (int i = 0; i < pdfAllImage. size(); i ++ ) {<!-- -->
currentCoverPath = coverPath + "/" + fileName + "th " + i + "page" + "." + coverExt;
// Create image file object
FileUtils.createParentDirectories(new File(currentCoverPath));
// write the image to the image object
ImageIOUtil.writeImage(pdfAllImage.get(i), currentCoverPath, dpi);
}
} catch (Exception e) {<!-- -->
log. error(e. getMessage());
}
}
test class
/**
* Extract file covers in batches
*/
@Test
public void pickupPdfToImage() {<!-- -->
String pdfFilePath = "D:/pdf_test/pdf/Three-Body Trilogy-Liu Cixin.pdf";
pdfService.pickupPdfToImage(new File(pdfFilePath));
}
3. Execution result

4. Precautions
Since the pdf extraction is to load the pdf file into the heap memory for operation, it is easy to cause heap memory overflow Java heap space during the extraction process. Simply put, when creating a new object, the heap memory There is not enough space in the object to hold the newly created object, causing this problem to occur.
The solution is as follows:
1. Optimize project code
Locate the code that consumes a lot of memory according to the error message, and then refactor it or optimize the algorithm. If it is in a production environment, be sure to increase the log information output in the code that consumes too much memory, otherwise it is easy to locate the problem overnight like me
2. Increase Java heap size
Increase the heap memory space setting, which is easy to operate. The current problem can be solved quickly, but generally speaking, it is still necessary to find the problem in the project code to be the optimal solution, after all, the memory is always limited
Allocate space according to your own hardware configuration, for example, the memory parameters of 8G memory configuration:
-Xms4096m -Xmx4096m
Good learning documents about pdfbox:
https://iowiki.com/pdfbox/pdfbox_overview.html