Process, thread, fiber
Dry information | Processes, threads, and coroutines are explained clearly in 10 pictures! – Zhihu (zhihu.com)
Process:
Process is the basic unit of OS allocation of resources. One process corresponds to a port number, and the OS will independently allocate a portion of resources to each process. Usually every time we run a program, a process will be generated.
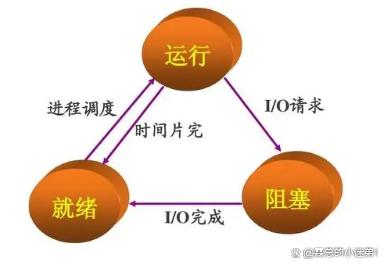
A process has three major states:ready state, running state, and death state.
Methods of inter-process communication
1. Pipeline:
Pipes mainly include unnamed pipes and named pipes: Pipes can be used for communication between parent and child processes with affinity. In addition to having the functions of pipes, named pipes also allow communication between unrelated processes.
2.Message queue
The message queue is a linked list of messages, stored in the kernel. A message queue is marked by an identifier (queue ID). Processes with write permissions can add new information to the message queue according to certain rules; processes with read permissions can read information from the message queue;
3.Semaphore
A semaphore is a counter that can be used to control access to shared resources by multiple processes. Semaphores are used to achieve mutual exclusion and synchronization between processes. To transfer data between processes, shared memory needs to be combined.
4. signal signal
Signals are a relatively complex communication method used to notify the receiving process that an event has occurred.
5. Shared Memory
It allows multiple processes to access the same memory space, and different processes can see updates to the data in the shared memory in each other’s process in a timely manner. This method requires some kind of synchronization operation, such as mutex locks and semaphores.
6. Socket SOCKET:
Socket is also an inter-process communication mechanism. Unlike other communication mechanisms, it can be used for process communication between different hosts.
Thread:
It is the basic unit for CPU to perform scheduling. A thread is a subtask of a process. A process contains multiple threads. Threads share the memory space of the process. It does not have an independent memory space. Hospot virtual machine threads correspond to system threads one-to-one. There is actually no concept of threads on Linux. Threads are just lightweight processes.
What mechanism manages thread switching
CPU manages thread switching through time allocation algorithm
The cpu context includes: If you are standing in a thread scenario, the answer is the thread’s private memory, virtual machine stack and program counter.
Synchronization method between threads
1.Semaphore
A semaphore is a special variable that can be used for thread synchronization. It only takes natural values and supports only two operations:
P(SV): If the semaphore SV is greater than 0, decrement it by one; if the SV value is 0, suspend the thread.
V(SV): If there are other processes that are suspended because they are waiting for SV, wake them up and then set SV + 1; otherwise, set SV + 1 directly.
2. Mutex
Also known as a mutex lock, it is mainly used for thread mutual exclusion and cannot guarantee sequential access. It can be synchronized with conditional locks. When entering the critical section, the mutex needs to be obtained and locked; when leaving the critical section, the mutex needs to be unlocked to wake up other threads waiting for the mutex.
3.Conditional variables
Also known as conditional lock, it is used to synchronize the value of shared data between threads. Condition variables provide an inter-thread communication mechanism: when a certain shared data reaches a certain value, wake up one or more threads waiting for this shared data. At this time, locking is required when operating shared variables.
How to understand that thread switching causes overhead
There are two steps for switching: Thread switching requires saving A’s private memory and loading B thread’s private memory. The CPU is required to perform these two steps, and the switching consumption is serial with the CPU execution of thread B. To sum up, the cost is the time cost of saving and loading.
Scenarios that cause switching
- After the time slice of the current execution task is used up, the system CPU schedules the next task normally.
- If the currently executing task encounters IO blocking, the scheduler suspends the task and continues with the next task.
- Multiple tasks seize lock resources. The current task does not seize the lock resources and is suspended by the scheduler. Continue to the next task.
- User code suspends the current task to give up CPU time
- hardware interrupt
4 types of lock mechanisms
Mutex lock: mutex, used to ensure that only one thread can access the object at any time. When the lock acquisition operation fails, the thread will go to sleep and be awakened when waiting for the lock to be released.
Read-write lock: rwlock, divided into read lock and write lock. When in read operation, multiple threads can be allowed to obtain read operations at the same time. But only one thread can obtain the write lock at the same time. Other threads that fail to acquire the write lock will enter the sleep state until they are awakened when the write lock is released. Note: Write locks will block other read and write locks. When a thread acquires a write lock and is writing, the read lock cannot be acquired by other threads; writers have priority over readers (once there is a writer, subsequent readers must wait, and writers are given priority when waking up). It is suitable for situations where the frequency of reading data is much greater than the frequency of writing data.
Spin lock: spinlock, only one thread can access the object at any time. But when the lock acquisition operation fails, it will not go to sleep, but will spin in place until the lock is released. This saves the consumption of threads from sleep state to waking up, which will greatly improve efficiency in environments with short locking time. But if the locking time is too long, it will waste CPU resources.
RCU: Read-copy-update. When modifying data, you first need to read the data, then generate a copy, and modify the copy. After the modification is completed, update the old data to new data. When using RCU, readers require almost no synchronization overhead. They neither need to obtain locks nor use atomic instructions, which will not cause lock competition, so there is no need to consider deadlock issues. The writer’s synchronization overhead is relatively large. It needs to copy the modified data and must also use a lock mechanism to synchronize and parallelize the modification operations of other writers. It is very efficient when there are a large number of read operations and a small number of write operations.
When writing multi-threaded programs on a single-core machine, do I need to consider locking?
Writing multi-threaded programs on a single-core machine still requires thread locks. Because thread locks are usually used to achieve thread synchronization and communication. In multi-threaded programs on single-core machines, there is still the problem of thread synchronization. Because in a preemptive operating system, each thread is usually allocated a time slice. When a thread’s time slice is exhausted, the operating system will suspend it and then run another thread. If these two threads share some data, modification of the shared data may cause conflicts without using thread locks.
How to communicate between threads
1. Critical section:
Access public resources or a piece of code through multi-threaded serialization, which is fast and suitable for controlling data access;
2. Mutex Synchronized/Lock:
Using a mutually exclusive object mechanism, only threads that own mutually exclusive objects have permission to access public resources. Because there is only one mutex object, it can be guaranteed that public resources will not be accessed by multiple threads at the same time.
3. Semaphore Semphare:
Designed to control a limited number of user resources, it allows multiple threads to access the same resource at the same time, but generally it is necessary to limit the maximum number of threads that can access this resource at the same time.
4. Event (signal), Wait/Notify:
Multi-thread synchronization is maintained through notification operations, and multi-thread priority comparison operations can be easily implemented.
Thread status switching
Thead.State enumeration class
Thread status
Get thread status

Thread status: managed by JVM, but JVM management must also be done through the operating system

/**
* Six states of threads:
* NEW: Created by new keyword
* RUNNABLE: call start()
* BLOCKED: A thread blocked waiting for the monitor lock is in this state
* WAITING: A thread that is waiting for another thread to perform a specific action is in this state.
* TIMED_WAITING: A thread that is waiting for another thread to perform an action for the specified waiting time is in this state.
* TERMINATED: The exited thread is in this state.
*
* @author: BlackSoil
* @date: 2022-11-18 09:43
* @version: 1.0
*/
public class T01_State {
public static void m() {
LockSupport.park();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static synchronized void n() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> m(),"Thread 1");
// The thread thread executed new and observed the NEW status
System.out.println(thread.getName() + "State after new: " + thread.getState());
// The thread thread executed start and observed the RUNNABLE status
thread.start();
System.out.println(thread.getName() + "After start method: " + thread.getState());
// The thread thread executed LockSupport.park() and observed the WAITING state
Thread.sleep(500);
System.out.println(thread.getName() + "State after LockSupport.park(): " + thread.getState());
LockSupport.unpark(thread); //Wake up the thread
// The thread thread executed sleep(long) and observed the TIMED_WAITING state
Thread.sleep(500);
System.out.println(thread.getName() + "State after sleep(long): " + thread.getState());
// Thread execution ends, observe the TERMINATED status
thread.join();
System.out.println(thread.getName() + "Execution completion status: " + thread.getState());
//Test BLOCKED status
Thread thread2 = new Thread(() -> n(),"Thread2");
Thread thread3 = new Thread(() -> n(),"Thread3");
thread2.start();
Thread.sleep(500); // Let thread2 execute first
thread3.start();
Thread.sleep(500); // Ensure that the thread has been executed
System.out.println(thread3.getName() + "Execution completion status: " + thread3.getState());
}
}
Fiber:
The JVM runs in user space. When it new a Thread, it will start a thread (kernel space) in the OS, so this is called a heavyweight thread. There are multiple fibers in user mode. The operating system does not schedule fibers. Compared with threads, coroutine switching does not require the operating system to save and restore the CPU context, its own cached data, etc., because all coroutines exist in the same thread, soCoroutine switching is only a simple CPU context switch (no kernel space involved), and the overhead is very small. A thread contains multiple fibers, also called coroutines, but coroutines are a concept, and fibers are a specific implementation of coroutines in the Windows system.
The coroutine also has a scheduler, but it is passively scheduled. That is to say, only when the currently running coroutine actively gives up the CPU, the scheduler will call the next coroutine from the coroutine pool. This is also the biggest difference between coroutines and the above ones: the scheduling method of coroutines is cooperative, which can also be called non-preemptive (Non-Preemptive); while the above three are all preemptive scheduling (Preemptive).
Why are fibers faster than threads?
As mentioned above, fibers are in user space and do not need to deal with the kernel. They are implemented at the language level. So why is the efficiency of threads that deal with the kernel relatively low? This is because once the program involves the conversion from user mode to kernel mode, the following steps must be performed, which is inefficient.

Concurrency and parallelism
Concurrency: Refers to the macroscopic view that two programs are running at the same time, such as multitasking on a single-core CPU. But from a microscopic perspective, the instructions of the two programs are interleaved and run. Your instructions are interspersed with my instructions, and my instructions are interspersed with yours. Only one instruction is executed in a single cycle. This concurrency does not improve computer performance, it can only improve efficiency.
Parallelism: refers to simultaneous operation in a strict physical sense, such as a multi-core CPU. Two programs run on two cores respectively. The two do not affect each other. Each program runs its own instructions in a single cycle. That is, two instructions are run. In this way, parallelism does improve the efficiency of computers. Therefore, current CPUs are developing towards multi-core.
The connection and difference between process and program
① A program is an ordered collection of instructions. It itself has no meaning of operation and is a static concept. A process is an execution process of a program on a processor, and it is a dynamic concept.
② A program can exist for a long time as a kind of software data, while a process has a certain life span. Programs are permanent, processes are temporary.
Note: A program can be regarded as a recipe, and a process is the process of cooking according to the recipe.
③ Processes and programs have different compositions: a process is composed of three parts: program, data and process control block.
④ Correspondence between processes and programs: Through multiple executions, one program can correspond to multiple processes; through calling relationships, one process can include multiple programs.
The difference between processes and threads
1.Threads depend on processes for their existence. A thread can only belong to one process, and a process can have multiple threads, but there must be at least one thread.
2. The process has an independent memory unit during execution, and multiple threads share the memory of the process.
(Resources are allocated to processes, and all threads in the same process share all resources of the process. Multiple threads in the same process share code segments, data segments, and heap storage. But each thread has its own stack segment, which is used to store all local variables and temporary variables)
3. Process is the smallest unit of resource allocation, and thread is the smallest unit of CPU scheduling;
4. Processes will not affect each other;
5. The overhead of creating, switching and destroying processes is relatively large, while threads are relatively small.
(Because when a process is created or destroyed, the system must allocate or reclaim resources for it, such as memory space, I/o devices, etc. Therefore, the overhead paid by the operating system will be significantly greater than when creating a process. Or the overhead when canceling threads. Similarly, when switching processes, it involves saving the CPU environment of the entire current process and setting the CPU environment of the newly scheduled process. Thread switching only requires saving and setting the contents of a small number of registers. , does not involve memory management operations. It can be seen that the cost of process switching is much greater than the cost of thread switching.)
6. Inter-process communication is relatively complex, but threads in the same process share code segments and data segments, so communication is relatively easy.
Three ways to start a thread
- Inherit Thread and override the run method
- Implement the Runnable interface and override the run method (or Lambda expression)
- Started through the thread pool (actually one of the above two)
Executor a = Executors.newCachedThreadPool();
a.execute(new Runnable() {
@Override
public void run() {
}
});
The meaning of Sleep Yield Join
sleep: sleep, the current thread is paused for a period of time, giving up the CPU for others to execute, and the lock will not be released. When sleep time is up, automatically revive

Yield: When the current thread is executing, stop and enter the ready queue. The system scheduling algorithm determines which thread continues to run (possibly itself)

Join: Join the join thread you called in its current thread. This thread waits for the calling thread to finish running, and then executes it itself. (It makes no sense to join yourself)

Deadlock
Conditions for occurrence
Deadlock refers to the phenomenon of two or more processes waiting for each other due to competition for resources during execution. The four necessary conditions for deadlock to occur are as follows:
1. Mutually exclusive condition: A resource can only be used by one process at a time.
2. Request and hold conditions: When a process is blocked due to requesting resources, it will hold on to the obtained resources.
3. Non-deprivation conditions: The resources that have been obtained by the process cannot be forcibly deprived before they are used up.
4. Cyclic waiting condition: A head-to-tail cyclic waiting resource relationship is formed between several processes.
Methods to solve deadlock
That is, to destroy one of the above four conditions, the main methods are as follows:
Resources are allocated once, thereby stripping request and hold conditions
Deprivable resources: that is, when the new resources of the process are not satisfied, the occupied resources are released, thus destroying the inalienable conditions.
Orderly allocation method of resources: The system assigns a sequence number to each type of resource, and each process requests resources according to the increasing number. The opposite is true for release, thus destroying the loop waiting conditions.
The difference between *interrupt*
java—The difference between interrupt, interrupted and isInterrupted
1. interrupt()
The interrupt method is used to interrupt the thread. The status of the thread that calls this method will be set to the “interrupted” status.
Note: The interrupt method is used to interrupt a thread. The status of the thread calling this method will be set to the “interrupted” status. Note: Thread interruptonly sets the interrupt status bit of the thread and does not stop the thread. So when a thread is in an interrupted state, if it is blocked by wait, sleep, and jion methods, the JVM will reset the thread’s interrupt flag to false and throw an InterruptedException, and then the developer can interrupt the state The essential function of “bit” is that the programmer uses the try-catch function block to capture the InterruptedException thrown by the jvm to do various processing, such as how to exit the thread. In short, the function of interrupt is to require the user to monitor the status of the thread. Bits and do the processing.”
2. interrupted() and isInterrupted()
public static boolean interrupted () {
return currentThread().isInterrupted(true);
}
public boolean isInterrupted () {
return isInterrupted(false);
}
1. interrupted is applied to the current thread, and isInterrupted is applied to the thread corresponding to the thread object that calls this method. (The thread corresponding to the thread object is not necessarily the currently running thread. For example, we can call the isInterrupted method of the B thread object in the A thread.)
2. Reflected in the parameters of the called method, the definition of the called method isInterrupted(boolean arg) (overloaded method in the Thread class):
private native boolean isInterrupted( boolean ClearInterrupted);
Local method, through the parameter name ClearInterrupted, we can know that this parameter represents whether the status bit should be cleared.
If it is true, it means that after returning the status bit of the thread, the original status bit should be cleared (restored to the original situation). If this parameter is false, it directly returns the status bit of the thread.
These two methods are easy to distinguish. Only the current thread can clear its own interrupt bit (corresponding to the interrupted() method)
The main thread main starts a sub-thread Worker, and then lets the worker sleep for 500ms, while main sleeps for 200ms. After that, main calls the interrupt method of the worker thread to interrupt the worker. After the worker is interrupted, the interrupt status is printed. The following is the execution result:
public class Interrupt {
public static void main(String[] args) throws Exception {
Thread t = new Thread(new Worker());
t.start();
Thread.sleep(200);
t.interrupt();
System.out.println("Main thread stopped.");
}
public static class Worker implements Runnable {
public void run() {
System.out.println("Worker started.");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
System.out.println("Worker IsInterrupted: " +
Thread.currentThread().isInterrupted());
}
System.out.println("Worker stopped.");
}
}
}
Results of the:
- Worker started.
- Main thread stopped.
- Worker IsInterrupted: false
- Worker stopped.
The Worker has obviously been interrupted, but the isInterrupted() method returned false. Why?
I checked the documentation for the Thread.sleep method. The doc describes this InterruptedException as follows:
- InterruptedException – if any thread has interrupted the current thread. The interrupted status of the current thread is cleared when this exception is thrown.
Java’s interrupt does not really interrupt the thread, but only sets the flag bit (interrupt bit) to notify the user. If you catch an interrupt exception, it means that the current thread has been interrupted and there is no need to continue to hold the interrupt bit.
Conclusion: The interrupt method is used to interrupt a thread, and the status of the thread calling this method will be set to the “interrupted” status. Note: Thread interrupt only sets the interrupt status bit of the thread and does not stop the thread. So when a thread is in an interrupted state, if it is blocked by wait, sleep, and jion methods, the JVM will reset the thread’s interrupt flag to false and throw an InterruptedException, and then the developer can interrupt the state The essential function of “bit” is that the programmer uses the try-catch function block to capture the InterruptedException thrown by the jvm to do various processing, such as how to exit the thread. In short, the function of interrupt is to require the user to monitor the status of the thread. Bits and do the processing.”