The article comes from the column of Wang Zheng, a former Google engineer at Geek Time.
The bottom layer of binary search relies on the random access characteristics of arrays, so it can only be implemented using arrays. If the data is stored in a linked list, is it really impossible to use the binary search algorithm?
We can slightly modify the linked list to support a search algorithm similar to “binary”. The modified data structure is called “Skip list”
Jump table is a dynamic data structure with excellent performance in all aspects. It can support fast insertion, deletion, and search operations. It is not complicated to write and can even replace the red-black tree.
Question: Why does Redis choose to use jump lists to implement ordered collections?
How to understand jump table?
For a singly linked list, even if the data stored in the linked list is ordered, looking for certain data can only traverse the linked list from beginning to end. The time complexity is O(n).
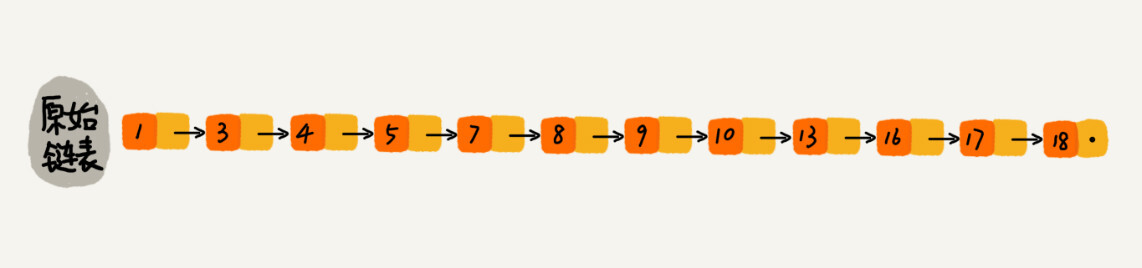
How to improve search efficiency?
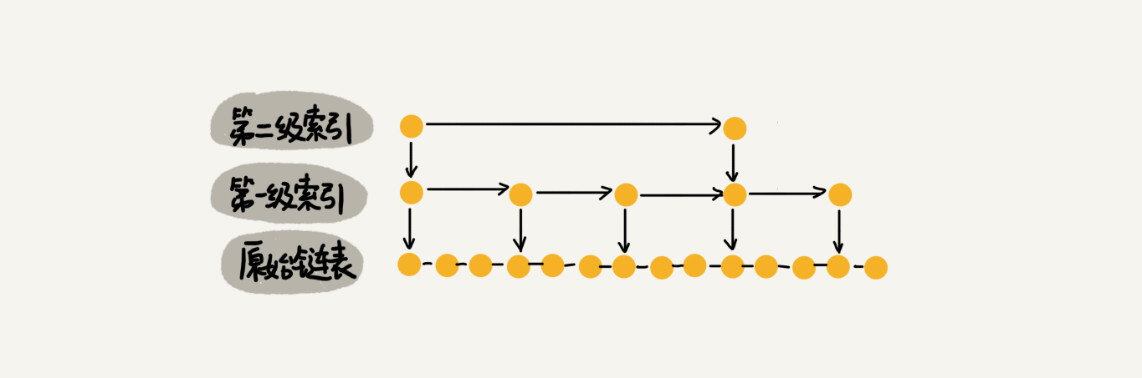
As shown in the figure, create a first-level “index” for the linked list, and extract one node from every two nodes to the upper level. We call the extracted level index or Index layer. down represents the down pointer, pointing to the next level node.

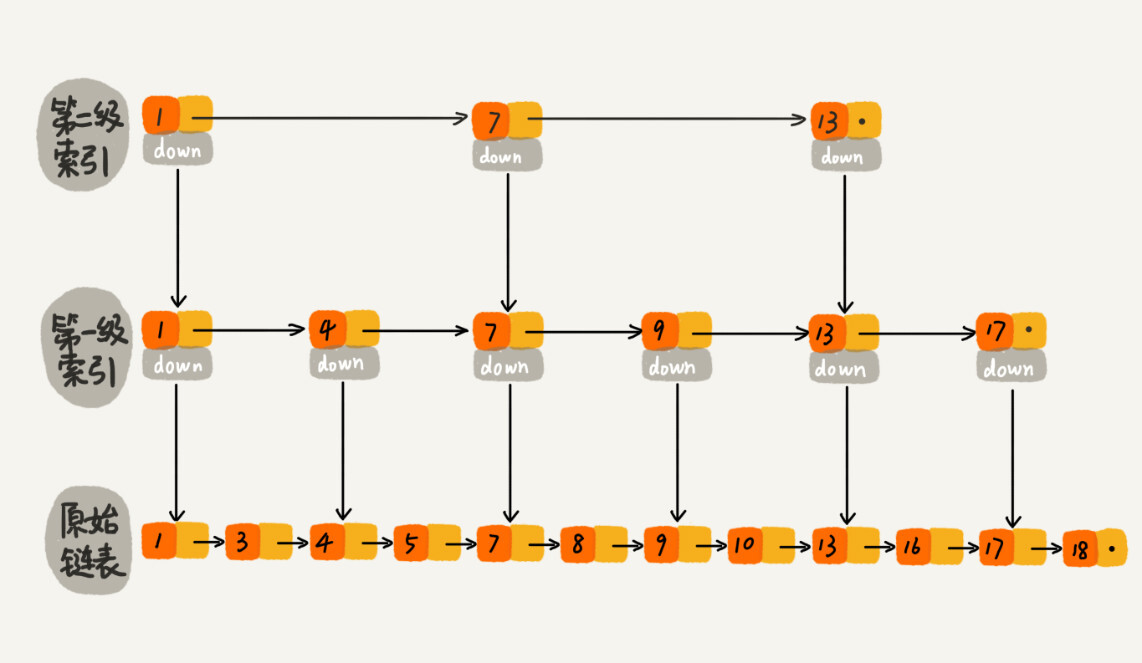
After adding a layer of index, the number of nodes that need to be traversed to find a node is reduced, which means that the search efficiency is improved. What if we add another level of index? Will efficiency be improved even more?
Based on the first-level nodes, one node is extracted from every two nodes to the second-level index. Now let’s find 16. We only need to traverse 6 nodes.
As shown in the figure below, a process with a large amount of data is simulated, and a 5-level index is established, containing a linked list of 64 nodes.
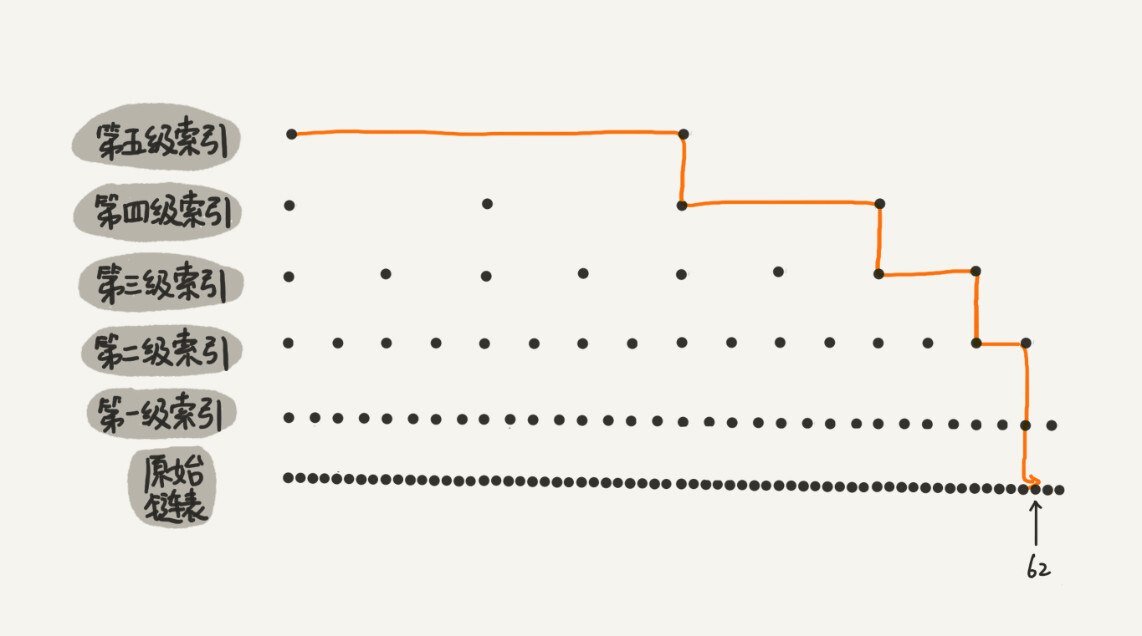
As can be seen from the figure, when there was no index, 62 nodes needed to be traversed to find 62, but now only 11 nodes need to be traversed. Therefore, when the length n of the linked list is relatively large, such as 1000 or 10000, after building the index, the search efficiency will be greatly improved.
This structure of linked list plus multi-level index is called skip list.
How fast is it to use skip table query?
Measured by time complexity. The time complexity of querying a certain data in a singly linked list is O(n). So what is the time complexity of querying a certain data in a skip table with multi-level indexes?
Assume that the linked list has n nodes, and every two nodes are used as nodes of the upper level index. The number of nodes in the first level index is approximately n/2, the second level is n/4, and the kth level The number of nodes in the index is n/(2^k).
Assume that the index has h levels, and the highest level index has 2 nodes. Through the formula, we can get n/(2^h)=2, and thus find h=log2n-1. If the original linked list level is included, the height of the entire skip list is log2n. When we query a certain data in the skip table, if each layer has to traverse m nodes, then the time complexity of querying a data in the skip table is O(m*logn).
So what is the value of m? According to the previous index structure, we only need to traverse a maximum of 3 nodes at each level of the index, which means m=3. Why? As shown below
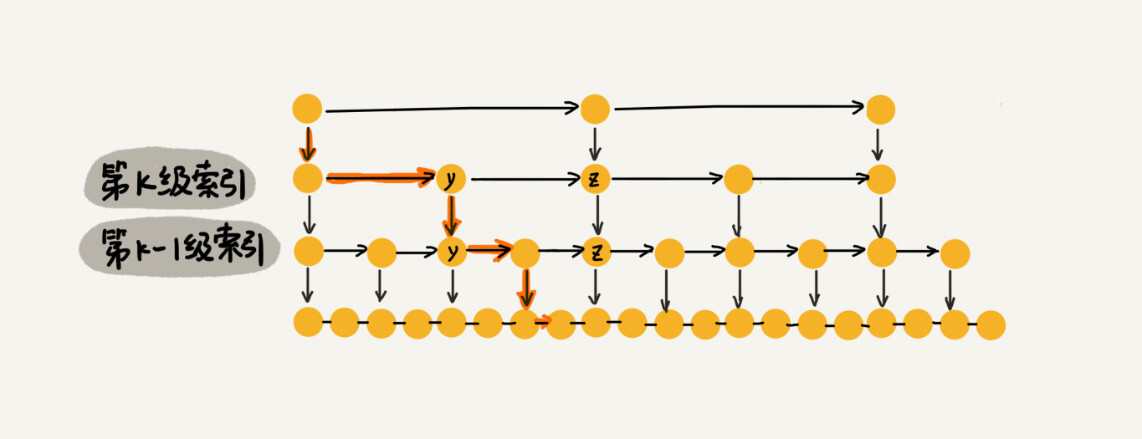
Because m=3, the time complexity of querying any data in the skip table is O(logn). The time complexity of this search is the same as that of binary search. In other words, we actually implemented binary search based on a singly linked list. This improvement in query efficiency requires the establishment of many levels of indexes, which is also a manifestation of the idea of exchanging space for time.
Is skipping a table a waste of memory?
Analyze the space complexity of skip lists.

The sum of the index nodes is the sum of the geometric sequence, n/2 + n/4 + n/8 + … + 8 + 4 + 2=n-2, so the space complexity of the skip table is O(n)
In other words, if a singly linked list containing n nodes is formed into a skip list, we need to use additional storage space of nearly n nodes. So is there any way we can reduce the memory space occupied by the index?
If we extract one node for every three nodes or five nodes to the upper-level index, will we not need so many index nodes?

The total index nodes are approximately n/3 + n/9 + n/27 + … + 9 + 3 + 1=n/2. Although the space complexity is still O(n), compared with the above index construction method of extracting one node for every two nodes, the index node storage space is reduced by half.
In software development, we don’t have to worry too much about the extra space occupied by indexes. When talking about data structures and algorithms, we are accustomed to treating the data to be processed as integers.However, in actual software development, the original linked list may store large objects, and the index nodes only Key values and several pointers need to be stored, but objects do not need to be stored. Therefore, when the object is much larger than the index node, the extra space occupied by the index can be ignored.
Efficient dynamic insertion and deletion
Insert
Jump tables not only support search operations, but also dynamic insertion and deletion operations. The time complexity of insertion and deletion operations is also O(logn)
Singly linked list, once the position to be inserted is located, the time complexity of inserting the node is very low, which is O(1). However, the search operation is time-consuming.
For a purely singly linked list, each node needs to be traversed to find the insertion position. However, for jump tables, the time complexity of finding a node is O(logn), so the method of finding the location where a certain data should be inserted is similar, and the time complexity is also O(logn).
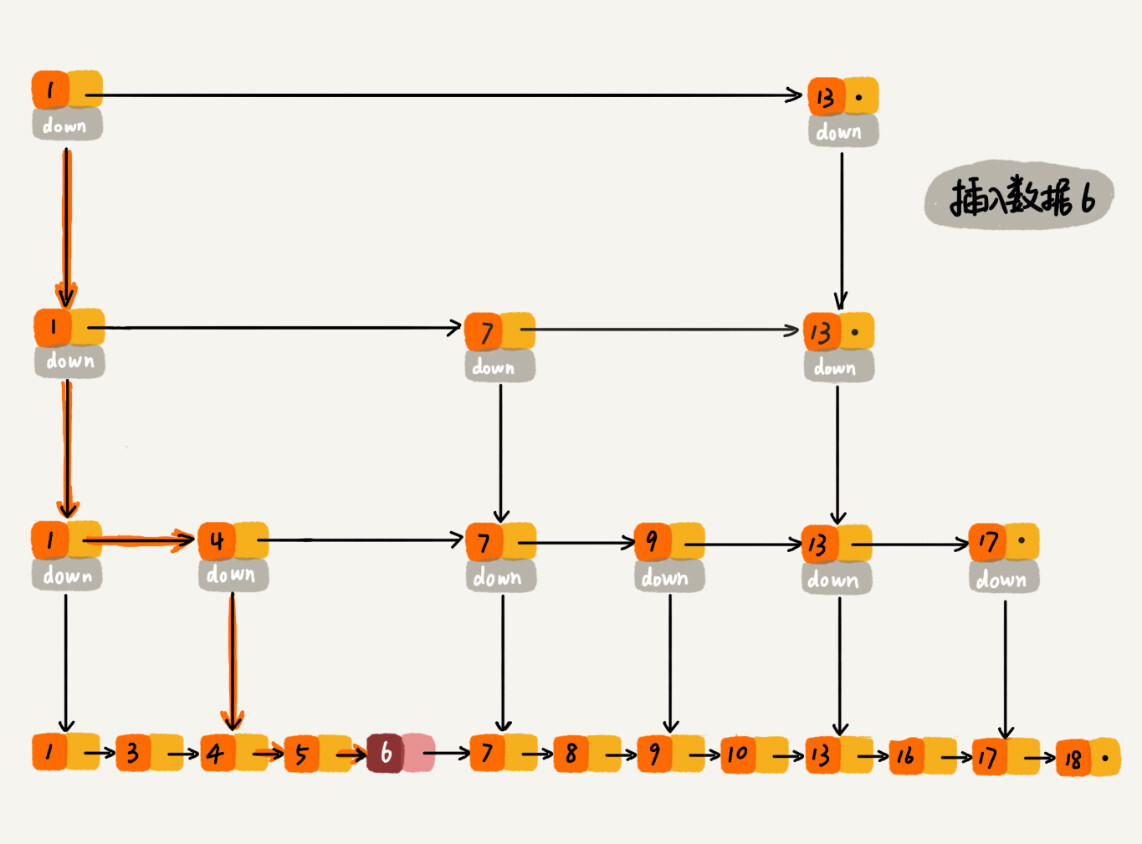
Delete
If this node also appears in the index, we not only need to delete the node in the original linked list, but also delete it in the index.
The deletion operation in a singly linked list requires getting the predecessor node of the node to be deleted, and then completing the deletion through pointer operation. If it is a doubly linked list, there is no need to consider it.
Dynamic update of skip table index
When we keep inserting data into the jump table, if we do not update the index, there may be a lot of data between two index nodes. In extreme cases, the skip list will degenerate into a singly linked list.
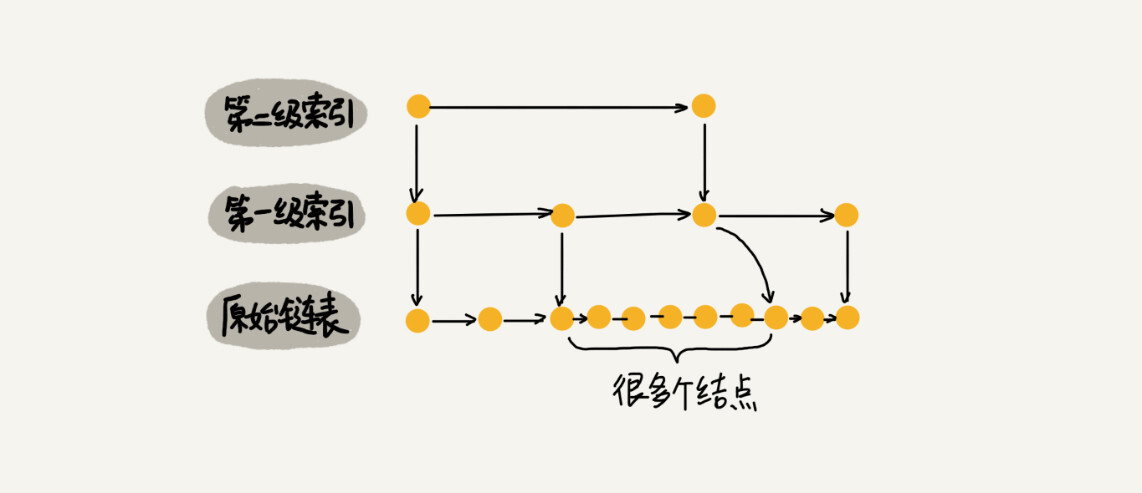
**As a dynamic data structure, we need some means to maintain a balance between the index and the original linked list size. **Avoid complexity degradation and performance degradation in search, insertion, and deletion operations.
The skip list maintains “balance” through random functions.
When we insert data into the jump table, we can choose to insert this data into some index layers at the same time. What index layers should I choose to add?
We use a random function to decide which level of index to insert this node into. For example, if the random function generates the value k, then we will add this node to the k-level index from the first level to the k-th level.

The selection of the random function is very particular. From a probability perspective, it can ensure the balance between the index size and data size of the jump table and avoid excessive performance degradation.
Jump table java implementation see Github
Answer opening
Ordered sets in Redis are implemented through skip lists and hash tables are also used. The core operations supported by ordered sets in Redis mainly include the following:
- insert a data
- delete a data
- Find a data
- Find data according to intervals (for example, find data with values between [100,356])
- Iterate over an ordered sequence
When searching for data according to intervals, the efficiency of red-black trees is not as high as that of jump tables. The skip list can locate the starting point of the interval with O(logn) time complexity, and then traverse sequentially in the original linked list. This is very efficient.
There are several reasons why Redis uses jump tables to implement ordered collections:
- Jump tables are easier to implement in code, have good readability, and are less prone to errors.
- Skip tables are more flexible and can effectively balance execution efficiency and memory consumption by changing the index construction strategy.
Skip lists cannot completely replace red-black trees. Red-black trees appeared early, and the Map types in many languages are implemented through red-black trees. You can use it directly for business development. If you want to use jump tables, you must implement it yourself.
Thinking
If every three or five nodes are extracted as a superior index, what is the corresponding time complexity of querying data in the jump table?
Jump table java implementation
/**
* An implementation method of skip table.
* Positive integers are stored in the jump list and are stored without duplication.
*
* Author:ZHENG
*/
public class SkipList {
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // Headed linked list
private Random r = new Random();
public Node find(int value) {
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null & amp; & amp; p.forwards[i].data < value) {
p = p.forwards[i];
}
}
if (p.forwards[0] != null & amp; & amp; p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
public void insert(int value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; + + i) {
update[i] = head;
}
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null & amp; & amp; p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;// use update save node in search path
}
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; + + i) {
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
}
//update node hight
if (levelCount < level) levelCount = level;
}
public void delete(int value) {
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null & amp; & amp; p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;
}
if (p.forwards[0] != null & amp; & amp; p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null & amp; & amp; update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
}
//Random level times, if it is an odd number of levels + 1, to prevent pseudo-randomness
private int randomLevel() {
int level = 1;
for (int i = 1; i < MAX_LEVEL; + + i) {
if (r.nextInt() % 2 == 1) {
level + + ;
}
}
return level;
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
public class Node {
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}