1. Using Flask as the server framework can run in the form of python code.py, but this method cannot be used in the production environment and is unstable. For example: there is a certain probability that the connection will time out without returning.
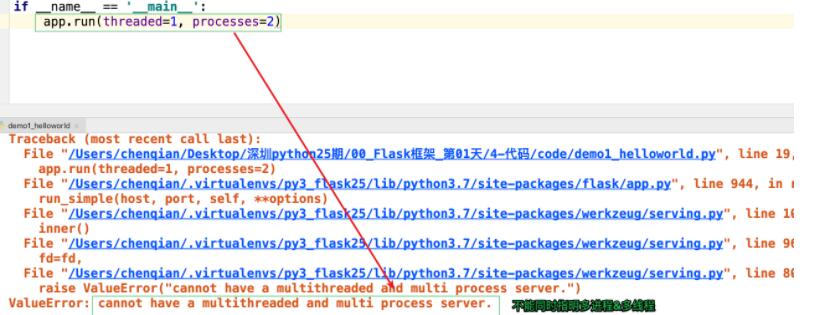
1. By setting the parameters of app.run(), the multi-process effect can be achieved. Look at the specific parameters of app.run:

Note: threaded and processes cannot be opened at the same time. If they are set at the same time, the following error will occur:
2. Use gevent as a coroutine to solve the problem of high concurrency:
# Ctrip’s third-party package – choose gevent here, of course you can also choose eventlet
pip install gevent
# The specific code is as follows:
from flask import Flask
from gevent.pywsgi import WSGIServer
from gevent import monkey
# Replace the python standard io method with the method of the same name in gevent, and gevent will automatically switch between coroutines when encountering io blockage
monkey. patch_all()
# 1. Create the project application object app
app = Flask(__name__)
# Initialize the server
WSGIServer(("127.0.0.1", 5000), app).serve_forever()
# To start the service --- this is to run the project in a coroutine way to improve concurrency
python code.py
3. Package the app in the form of Gunicorn (with gevent) to start the service [recommended]
Install the gunicorn server that follows the WSGI protocol — commonly known as: green unicorn
pip install gunicorn
View command line options: After installing gunicorn successfully, you can view the usage information of gunicorn through the command line.
$ gunicorn -h

Specify process and port number: -w: indicates process (worker) –bind: indicates binding ip address and port number (bind) -threads multithreading -k asynchronous scheme
# Use gevent to do asynchronously (the default worker is synchronous)
gunicorn -w 8 –bind 0.0.0.0:8000 -k ‘gevent’ run file name: Flask program instance name
Run scheme 2: Load the running information into the configuration file
Use gunicorn + gevent to enable high concurrency
import multiprocessing """gunicorn + gevent configuration file""" # Preload resources preload_app = True # bind bind = "0.0.0.0:5000" # number of processes workers = multiprocessing.cpu_count() * 2 + 1 # Threads threads = multiprocessing.cpu_count() * 2 # The maximum length of the waiting queue, connections exceeding this length will be rejected backlog = 2048 # Operating mode # worker_class = "egg:meinheld#gunicorn_worker" worker_class = "gevent" # The maximum number of concurrent client clients, which has an impact on the work of workers using threads and coroutines worker_connections = 1200 # process name proc_name = 'gunicorn.pid' # Process pid record file pidfile = 'app_run.log' # log level loglevel = 'debug' # log file name logfile = 'debug.log' # Access to records accesslog = 'access.log' # access record format access_log_format = '%(h)s %(t)s %(U)s %(q)s' # run mode command line gunicorn -c gunicorn_config.py flask_server:app
Use meinheld + gunicorn + flask to enable high concurrency artifact
Prerequisites Install meinheld in a virtual environment:
pip install meinheld import multiprocessing """gunicorn + meinheld configuration file""" # Preload resources preload_app = True # bind bind = "0.0.0.0:5000" # Number of processes: number of cups * 2 + 1 workers = multiprocessing.cpu_count() * 2 + 1 # Number of threads, number of cups * 2 threads = multiprocessing.cpu_count() * 2 # The maximum length of the waiting queue, connections exceeding this length will be rejected backlog = 2048 # Operating mode worker_class = "egg:meinheld#gunicorn_worker" # The maximum number of concurrent client clients, which has an impact on the work of workers using threads and coroutines worker_connections = 1200 # process name proc_name = 'gunicorn.pid' # Process pid record file pidfile = 'app_run.log' # log level loglevel = 'debug' # log file name logfile = 'debug.log' # Access to records accesslog = 'access.log' # access record format access_log_format = '%(h)s %(t)s %(U)s %(q)s' # run mode command line gunicorn -c gunicorn_config.py flask_server:app
expand
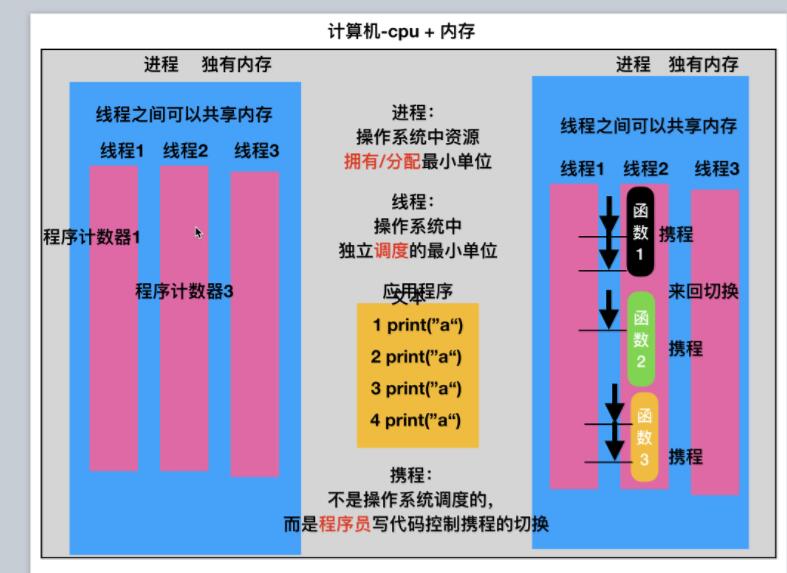
Concept: Coroutine is a program that works together, not a process or a thread. It is understood as a function call without a return value.
Coroutine: coroutine, also known as micro-thread, fiber.
This “suspend” and “wake-up” mechanism of coroutines essentially divides a process into several sub-processes, giving us a flat way to use the event callback model. Advantages: The context of the shared process, a process can create millions, tens of millions of coroutines.
Both yield in python and the third-party library greenlet can implement coroutines.
Greenlet provides a way to directly switch control in the coroutine, which is more flexible and concise than the generator (yield).
Historical issues – GIL lock
1. Thread safety is in a multi-threaded environment. Thread safety can ensure that the program still runs correctly when multiple threads are executed at the same time, and it must ensure that shared data can be accessed by multiple threads, but only one can be accessed at the same time. thread to access. Each interpreter process can only be executed by one thread at the same time, to obtain related locks and access related resources. Then it is easy to find that if an interpreter process can only be executed by one thread, multi-threaded concurrency becomes impossible, even if there is no competition for resources among these threads.
2. So although CPython’s thread library directly encapsulates the native threads of the operating system, the CPython process as a whole will only have one thread that has obtained the GIL running at the same time, and other threads are in a waiting state waiting for the release of the GIL. So only single core of cpu can be used. This is why python multithreading is criticized.
Solution: Python’s high concurrency recommends multi-process + coroutine
io multiplexing
IO multiplexing means that once the kernel finds that one or more IO conditions specified by a process are ready to be read, it notifies the process.
1. select (thread unsafe): It monitors an array of multiple file descriptors through a select() system call. When select() returns, the ready file descriptors in the array will be modified by the kernel. Allows the process to obtain these file descriptors for subsequent read and write operations.
2. poll (thread unsafe): It is not much different from select in essence, but poll has no limit on the maximum number of file descriptors
3. epoll (thread-safe): epoll can support both horizontal triggering and edge triggering (Edge Triggered, only tells the process which file descriptors have just become ready, it only says it once, if we don’t take action, then it won’t Again, this method is called edge triggering), theoretically the performance of edge triggering is higher, but the code implementation is quite complicated.
Python asynchronous implementation
Multi-process + coroutine + callback (io multiplexing for event-driven)
Coroutine third-party packaging library:
-
gevent = greenlet + python.monkey (the bottom layer uses libevent time complexity: O(N * logN))
-
meinheld = greenlet + picoev (time complexity: O(N) )
-
eventlet
picoev and libevent
Both meinheld and gevent can be asynchronous, but the performance of meinheld is much better than gevent in the evaluation, but because meinheld supports less, it is generally used with gunicorn. Let’s analyze the main reasons for the performance gap between meinheld and gevent, using picoev and lievent respectively.
# libevent
Main implementation: use the heap (priority queue) as the algorithm (nlogn) of the timer event, and the implementation of IO and signals both use a two-way queue (implemented with a linked list).
Time complexity: O(N * logN)
#picoev
picoev: According to the author’s introduction, there are two main optimization points.
1. The main consideration is that fd (file descriptors) is represented by relatively small positive integers in Unix, so store all the relevant information of fd in an array, which makes the search fast, and it will be more convenient when operating the socket state fast.
2. The second point is the algorithm optimization of the timer event. Through the implementation of the ring buffer (128) and bit vector to view part of the source code, it can be seen that the main implementation is that each time point corresponds to a location in the buffer, and each cache The area uses a bit vector to represent the value of fd, which is equivalent to a hash mapping, so the time complexity is (o(n)), and n is the number of fd stored in that buffer area.
Time complexity: O(N)
Performance: picoev > libevent
Understanding—-coroutine & amp; thread & amp; process