Table of Contents
Basic framework and interface
Constructor
No-argument construction
Iterator range construction
Initialization construction
destructor
size() | capacity()
Expanded reserve()
Problems using memcpy copy
resize() to change size
operator[]
Iterator implementation
Addition and deletion of vector
End insertion push_back()
Tail deletion pop_back()
Use insert and erase to discuss the issue of iterator failure
insert()
erase()
Implementation of deep copy
copy constructor
Assignment operator=
In the last article, we talked about vector, which is a class template that can accommodate various types of objects as its elements and can be dynamically resized. Can be understood as a dynamic array.
In this article, we will implement a simple version of vector ourselves, which can greatly deepen our understanding of vector!
Because the implementation of vector has many similarities with string, some details of the implementation process will not be detailed.
Basic framework and interface
vector.h:
#pragma once
namespace jzy //In order to distinguish it from the vector in the STL library, we put it into a custom namespace
{
template<typename T>
class vector
{
public:
typedef T* iterator;
private:
iterator_start;
iterator _finish; //finish represents the position after the last position
iterator _end_of_storage;
};
}
The three member variables here are implemented according to STL 3.0 version with reference to “STL Source Code Analysis”.

In this case, if you want to know _size or _capacity, just use member variables to subtract.
Constructor
No-parameter construction
vector()
:_start(nullptr)
,_finish(nullptr)
, _end_of_storage(nullptr)
{}
Iterator interval construction
It is constructed by passing the starting and starting range of the iterator (left closed and right open).

vector(InputIterator first, InputIterator last)
{
InputIterator it = first;
int num = 0; //Count number
while (it != last)
{
it++;
num + + ;
}
?
_start = new T[num];
for (int i = 0; i < num; i + + )
{
_start[i] = *first + + ;
}
_finish = _start + num;
_end_of_storage = _start + num;
}
Initialization construction
The object can be initialized during construction to contain n val values.

vector(int n, const T & amp; val = T()) //Note: size_t cannot be given here!
{
_start = new T[n];
for (int i = 0; i < n; i + + )
{
_start[i] = val;
}
_finish = _start + n;
_end_of_storage = _start + n;
}
Why can’t the type of n be size_t?
If it is size_t, when the two parameters passed are of int type, the test result is:
void test7()
{
vector<int> v1(5,1);
for (auto & e : v1)
{
cout << e << " ";
}
}

reason:
We know that when v1 matches the constructor, it matches based on the type of the parameter.
size_t and int do not match well, but InputIerator can match the int type, because the InputIerator itself is a template, and int can be matched without conversion.
So the constructor called by v1 is vector(InputIterator first, InputIterator last); ,
In this function, int is dereferenced, so an error is reported: illegal indirect addressing.
Destructor
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
size() | capacity()
The current three member variables cannot intuitively represent the capacity and size, so we need to implement it ourselves.
size_t size()
{
return _finish - _start;
}
?
size_t capacity()
{
return _end_of_storage - _start;
}
Expanded reserve()
The idea for expansion is:
First open a new space, then copy all the data to the new space, then release the old space and let the pointer point to the new space.
Uncorrected version of reserve:
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
?
T* tmp = new T[n];
int a = size();
if (_start)
{
memcpy(tmp, _start, sz* sizeof(T));
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storage = _start + n;
}
}
Let’s test it:
void test10()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
?
for (auto & e : v)
{
cout << e << " ";
}
cout << endl;
}

Looks like it’s done. But is it really OK?
If we use a custom type, such as vector
void test9()
{
vector<string> v;
v.push_back("happy");
v.push_back("happy");
v.push_back("happy");
v.push_back("happy");
v.push_back("happy");
?
for (auto & e : v)
{
cout << e << " ";
}
cout << endl;
?
}

The program actually crashed!
In fact, this is all the fault of memcpy.
Problems using memcpy copy
?memcpy can only perform shallow copies, so if you are copying built-in types, you are happy to use memcpy.
If it is a custom type and involves resource management, memcpy cannot be used, otherwise it may cause memory leaks or even program crashes.
Now let’s explain why the vector
When calling push_back, if there is not enough space, push_back will call reserve internally to open up space. The problem lies in this reserve. Let’s take a look at how reserve is implemented:
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
?
T* tmp = new T[n];
int a = size();
if (_start)
{
memcpy(tmp, _start, sz* sizeof(T)); //Use memcpy when copying data
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storage = _start + n;
}
}
As you can see, reserve is used to adjust memcpy to copy data, and _start is released after copying.
The principle of memcpy copy is shallow copy, which directly copies the value. If the elements in the vector are int or char, then there is no problem in directly copying them. But at this time, the vector in the vector is a string. We know that if we want to find the string, we need to know the address of the first element. Therefore, the vector container stores the addresses of the first elements. At this time, shallow copying will be like this:
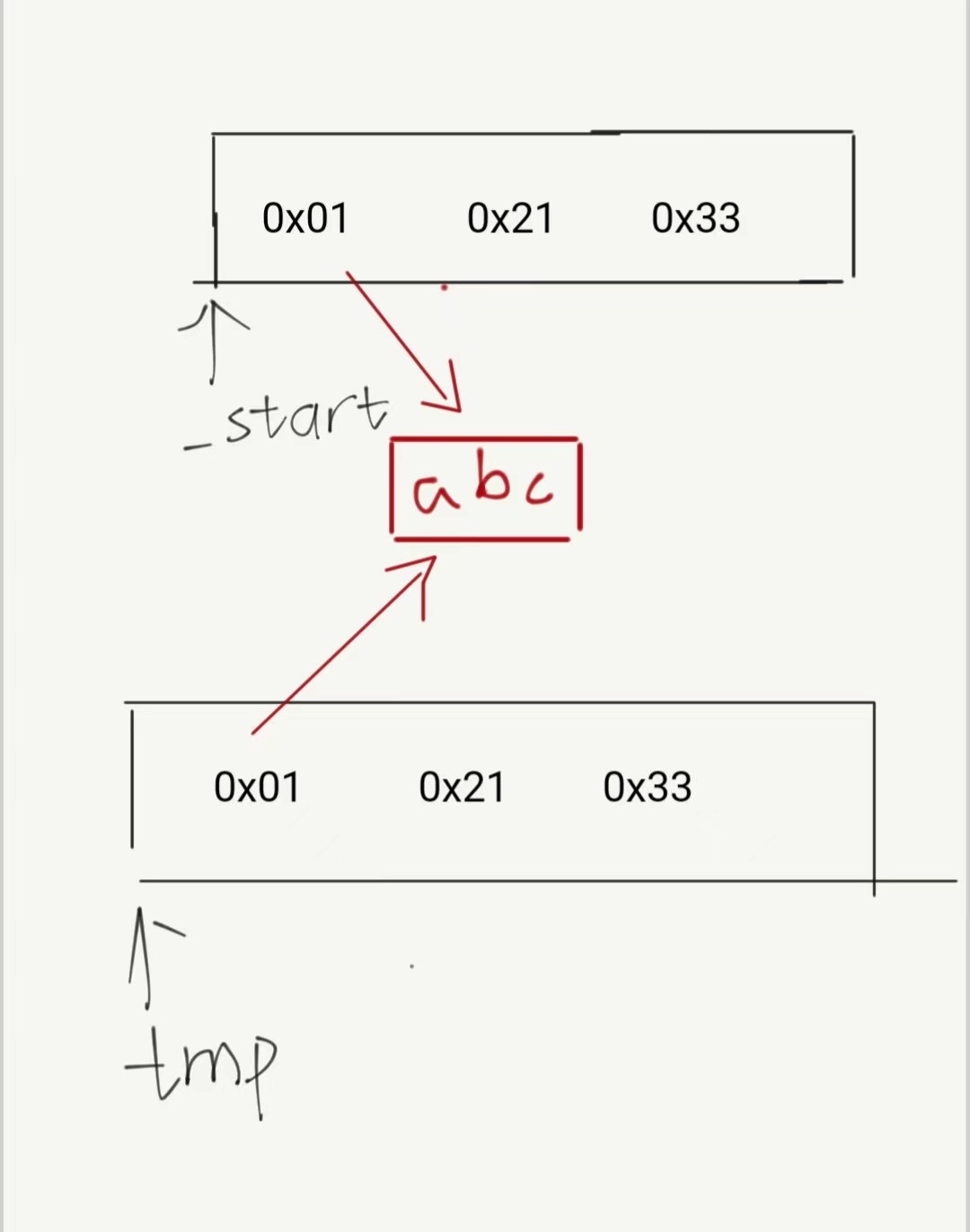
The content of tmp is copied from the memcpy value and points to the same space as _start. When _start is deleted, the tmp space is also released.
Therefore, if the object involves resource management, you must not use memcpy to copy between objects. You still have to copy it honestly yourself.
Modified reserve:
void reserve(size_t n)
{
if (n > capacity())
{
//open space
T* tmp = new T[n];
//copy data
iterator begin = _start;
int i = 0;
while (begin != _finish)
{
tmp[i + + ] = *begin + + ;
}
//Release, assignment
delete[] _start;
_start = tmp;
_finish = tmp + i;
_end_of_storage = tmp + n;
}
}
Test again at this time:

resize() that changes the size
void resize(size_t n , T val = T())
{
if (n < size())
{
_finish = _end_of_storage = _start + n;
}
else
{
reserve(n);
for (int i = size(); i < n; i + + )
{
_start[i] = val;
}
_finish = _start + n;
}
}
operator[]
T & amp; operator[] (size_t pos)
{
assert(pos < size());
return *(_start + pos);
}
Iterator implementation
begin() | end() of ordinary iterator:
typedef T* iterator;
iterator begin()
{
return _start;
}
?
iterator end()
{
return _finish;
}
begin() | end() of const iterator:
After being modified by const, it can only be read, not written.
typedef const T* const_iterator;
const_iterator begin() const
{
return _start;
}
?
const_iterator end() const
{
return _finish;
}
About scope for:
As long as the iterator is implemented, the range for can be used without having to implement it specially:
void test1()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
?
for (auto e : v) //Traverse with range for
{
cout << e << " ";
}
cout << endl;
}
In fact, the underlying principle of range for is iterator. It relies on begin() and end() to implement, and only knows begin() and end().
If I change the name of begin() to Begin(), the iterator will still work, but the range for won’t work: it doesn’t know Begin(). . .
vector additions and deletions
Tail insert push_back()
void push_back(const T & amp; val)
{
//First consider whether the capacity is enough
if (size() == capacity())
{
reserve(capacity() == 0 ? 4 : 2 * capacity());
}
?
*_finish = val;
_finish + + ;
}
Note here: the formal parameter must be modified by const and passed by reference.
It is more labor-saving to pass by reference, otherwise deep copying will be expensive; with const, formal parameters can receive constant strings.
Tail delete pop_back()
void pop_back()
{
assert(_start<_finish);
_finish--;
}
Use insert and erase to discuss the issue of iterator failure
insert()
void insert(iterator pos, const T & amp; val)
{
assert(pos >= _start);
assert(pos <= _finish);
//First consider whether there is enough space
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : 2 * capacity());
}
//Move data
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
//insert
*pos = val;
_finish + + ;
}
Writing this way is actually not enough. Problems will arise once expansion is involved. Let’s test it out:
void test2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.pop_back();
v.insert(v.begin(), 10);
v.insert(v.begin(), 11);
v.insert(v.begin(), 12);
?
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}

A random value appears!
The reason is actually that there was an omission in the reserve expansion step, which made the iterator pos invalid.
This is the iterator invalidation problem.

In other words, after the expansion, the iterator pos needs to be updated: so that pos that originally pointed to the old space now points to the same position in the new space.
After modification:
void insert(iterator pos, const T & amp; val)
{
int flag_pos = pos - _start; //Record the relative position of pos first so that pos can be updated later
?
assert(pos >= _start);
assert(pos <= _finish);
//Consider whether there is enough space
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : 2 * capacity());
pos = _start + flag_pos; //Update pos based on the position just recorded
}
?
//Move data
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
//insert
*pos = val;
_finish + + ;
}
Now you can insert successfully:

Expanded thinking: If v.begin() is passed to pos, is it feasible to pass parameters by reference?
void insert(iterator & amp; pos, const T & amp; val);Not feasible. This question tests our basic knowledge of classes and objects.
Let’s take a look at begin():
iterator begin() { return _start; }It returns by value, and what is returned is not _start, but its copied temporary object.
The temporary object is permanent, so pos cannot be its alias. We can only copy it and save it in pos.
erase()
void erase(iterator pos)
{
assert(pos >= _start & amp; & amp; pos < _finish ); //Note here: cannot <=_finish! Because it points to the position after the last element
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
begin++;
}
_finish--;
}
but! The seemingly calm erase() actually contains hidden dangers: erase will also have the problem of iterator failure.
Now we use an example to show its problem: we are now required to delete all even numbers.
v is divided into two groups, namely A: {1,2,3,4,5}; B: {1,2,3,4}.
A:
void test3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
?
vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
v.erase(it);
}
it++;
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}

Deletion successful. But if v is 1 2 3 4, it won’t work.
B:
void test3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
…
}
The program crashed:

This is because the iterator is invalid. We use a diagram to illustrate the reason:

And {1,2,3,4,5} is just a coincidence. The deleted even number is followed by an odd number, so no error is exposed.
So how do the experts who write C++ deal with the failure of the iterator in erase?
The processing idea is: change the return value from void to iterator, and return the position of pos after deletion. In this case, the iterator will still point to pos after deletion, and the comparison of pos positions will not be missed.

Modified erase:
iterator erase(iterator pos)
{
assert(pos >= _start & amp; & amp; pos < _finish ); //Note here: cannot <=_finish! Because it points to the position after the last element
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
begin++;
}
_finish--;
return pos;
}
test:
void test3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
?
//Request to delete all even numbers
vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0) //Use if else statement. After deletion, the iterator will still stop at pos position and will not increase by itself.
{
it = v.erase(it);
}
else
{
it++;
}
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}

Pay attention to the way the test is written here! ! After v.erase(), use an iterator to receive its return value, and use an if else statement to increase it. This prevents the program from crashing due to accessing an invalid iterator.
If you still write it this way:
void test5() { vector<int> v1; v1.push_back(1); v1.push_back(2); v1.push_back(3); v1.push_back(4); vector<int>::iterator it = v1.begin(); while (it != v1.end()) { if (*it % 2 == 0) { v1.erase(it); } it++; } for (auto e : v1) { cout << e << " "; } }That would still crash the program! !
In fact, no error will be reported when the iterator is invalid. The error is reported because the invalid iterator is accessed.
Therefore, be careful when using erase.
In order for the program to run normally, firstly, the underlying implementation must return an iterator;
Second, when using erase, use an if else statement, and use an iterator to receive the return value of the function.
Written question about iterator failure
Use the knowledge you just learned to answer this question!
What is the result of running the following program?
int main()
{
int ar[] ={1,2,3,4,0,5,6,7,8,9};
int n = sizeof(ar) / sizeof(int);
vector<int> v(ar, ar + n);
vector<int>::iterator it = v.begin();
while(it != v.end())
{
if(*it != 0)
cout<<*it;
else
v.erase(it);
it++;
}
return 0;
}
A. The program crashes
B.1 2 3 4 5 0 6 7 8 9
C.1 2 3 4 5 6 7 8 9
D.1 2 3 4 6 7 8 9
We have just emphasized that when using erase, the writing method is very particular. If else statement + use an iterator to receive the return value, the program can run normally. Written this way, the program will crash due to accessing an invalid iterator. Choose A.
implementation of deep copy
copy constructor
If we use the default copy constructor to perform a shallow copy of the vector:
void test4()
{
vector<int> v1;
vector<int> v2(v1);
}

This is because a shallow copy can only copy the value, not the same space.
In this way, v1 and v2 point to the same space. When v1 and v2 are destructed, the same space is destructed twice, so the program crashes.
Therefore, we need to manually implement the copy construction of vector and implement deep copy.
Way1 traditional writing method: open space and copy data honestly.
vector(vector<T> & amp; v)
:_start(new T[v.capacity()])
, _finish(_start + v.size())
, _end_of_storage(_start + v.capacity())
{
memcpy(_start, v._start, sizeof(T) * v.size());
}
Way2 modern writing method: The essence is to reuse existing code, “construct a new object + swap yourself with the new object”.
vector(const vector<T> & amp; v)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
vector<T> tmp(v.begin(), v.end());
swap(_start, tmp._start);
swap(_finish, tmp._finish);
swap(_end_of_storage, tmp._end_of_storage);
}
assignment operator=
vector<T> & amp; operator=(vector<T> v) //Because parameters are passed by value, v is already a copy of the actual parameters, so there is no need to construct tmp again.
{
swap(_start, v._start);
swap(_finish, v._finish);
swap(_end_of_storage, v._end_of_storage);
return *this;
}