Click the Card below to follow the “Heart of Autonomous Driving” public account
ADAS giant volume of dry information is now available
>Click to enter→Heart of Autonomous Driving [Model Deployment] Technical Exchange Group
Author of the paper | EasonBob
0. Write in front
Shared memory is an important part of model deployment and acceleration. It determines how efficient the optimization can be. It is mainly divided into dynamic and static shared memory. The following will introduce shared memory and its source code in detail, as well as possible conflict!
1. Shared memory
Input size is 4096 x 4096 matmul in gpu(warmup) uses 102.768669 ms matmul in gpu(without shared memory)<<<256, 16>>> uses 101.848831 ms matmul in gpu(with shared memory(static))<<<256, 16>>> uses 63.545631 ms
In the previous case, we opened the two matrices M and N through cudaMalloc() and then moved the data from Host to Device using cudaMemcpy(). What is actually used here is Global Memory. As you can see from the picture, Global Memory In fact, it is very slow, because the closer it is to Threads in the picture, it will have a higher bandwidth, so in CUDA programming we need to use more L1 Cache and Share Memory. Shared memory is dedicated to each thread block (block).

1.1 MatmulSharedStaticKernel()
Static shared memory, the design here is to set a shared memory of the same size as the number of threads for each block. The final P_element is the same as before, or the calculations in all blocks are added up. The idea here is the same as before. The only difference is the memory accessed by each block.
In each block, the thread first gets the corresponding memory from Global Memory (M_device, N_device) to fill in the shared memory. After all is filled in (synchronized), it is taken out from the shared memory in turn to do the corresponding calculations.
__syncthreads(); This is bound to shared memory. It appears twice here. The first time is that the thread in each thread block first transfers a small piece of data (tile) from global memory (M_device and N_device). Copied to shared memory. The second time is to wait for all calculations to be completed.
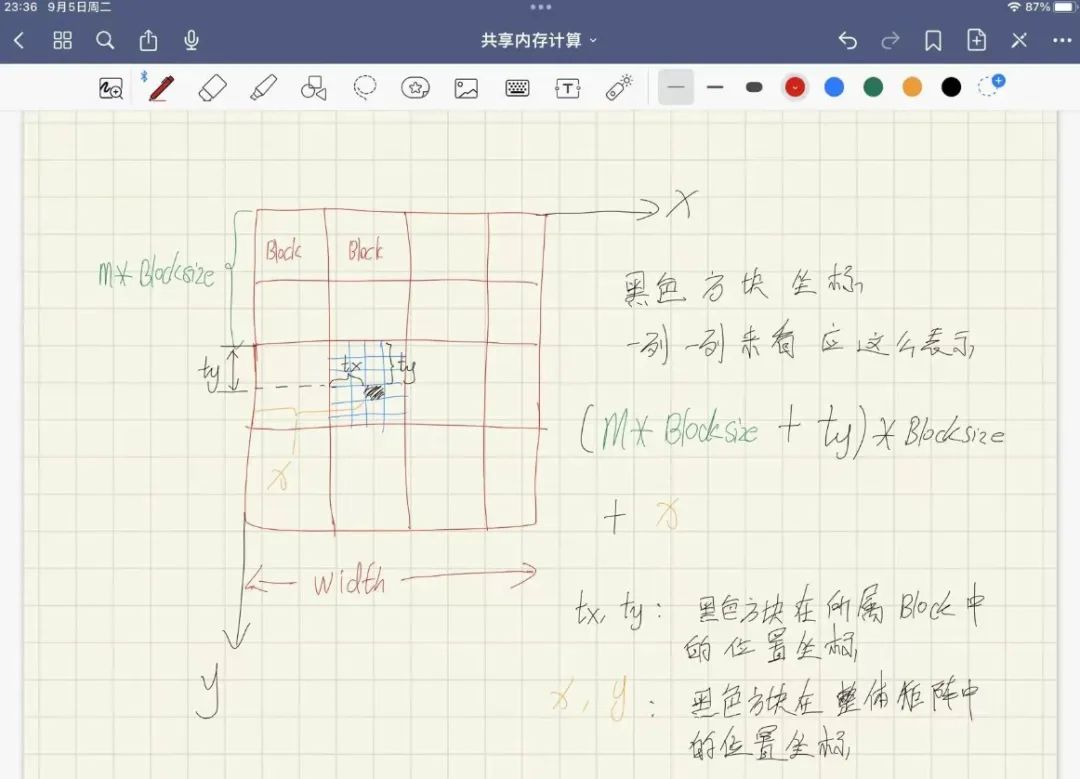
M’s shared memory is traversed to the right, and rows are obtained. It can be imagined that the purpose is to obtain each row, that is, how to obtain each element of each row in the case of y++, Use tx and y
M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];
M’s shared memory is traversed downward, and the column is obtained. It can be imagined that in order to obtain each column, that is, in the case of x + +, to obtain the elements of each column, use tx and y
N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];
/*
For x and y, index based on blockID, tile size and threadID
*/
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float P_element = 0.0;
// What appears here is the index in the block, because shared memory is exclusive to the block.
int ty = threadIdx.y;
int tx = threadIdx.x;
/* For each element of P, we only need to loop through width / tile_width times and it will be okay. This is a bit convoluted. Let’s draw a picture to understand it*/
for (int m = 0; m < width / BLOCKSIZE; m + + ) {
M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];
N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k + + ) {
P_element + = M_deviceShared[ty][k] * N_deviceShared[k][tx];
}
__syncthreads();
}
P_device[y * width + x] = P_element;
}
The result of P_device is the sum of all m
1.2 Dynamic shared memory
Generally speaking, you don’t need to use shared dynamic memory unless you have any special needs, and it may not necessarily be much faster. By Director Han
__global__ void MatmulSharedDynamicKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){
/*
When declaring dynamic shared variables, you need to add extern, and they need to be one-dimensional.
Note that there is a pitfall here, it cannot be defined like this:
__shared__ float M_deviceShared[];
__shared__ float N_deviceShared[];
Because when dynamic shared variables are defined in CUDA, their addresses will be the same no matter how many are defined.
So if you want to use it like the above, you need to use two pointers to point to different locations in the shared memory.
*/
extern __shared__ float deviceShared[];
int stride = blockSize * blockSize;
/*
For x and y, index based on blockID, tile size and threadID
*/
int x = blockIdx.x * blockSize + threadIdx.x;
int y = blockIdx.y * blockSize + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* For each element of P, we only need to loop through width / tile_width times and it will be okay */
for (int m = 0; m < width / blockSize; m + + ) {
deviceShared[ty * blockSize + tx] = M_device[y * width + (m * blockSize + tx)];
deviceShared[stride + (ty * blockSize + tx)] = N_device[(m * blockSize + ty)* width + x];
__syncthreads();
for (int k = 0; k < blockSize; k + + ) {
P_element + = deviceShared[ty * blockSize + k] * deviceShared[stride + (k * blockSize + tx)];
}
__syncthreads();
}
if (y < width & amp; & amp; x < width) {
P_device[y * width + x] = P_element;
}
}
2. Bank Conflict
Problems you may encounter when using shared memory
2.1 Bank Conflict
-
Shared memory bank organization
Shared memory is organized into banks (e.g., 32 or 64), each of which can service one memory access in one clock cycle. So, ideally, if 32 threads (one warp) access 32 different words in 32 different banks, all these accesses can be completed in one clock cycle.
-
What is Bank Conflict?
A bank conflict occurs when multiple threads access different words in the same bank in the same clock cycle. This causes access to be serialized, increasing the overall access time. For example, if two threads access two different words in the same bank, it takes two clock cycles to service the two accesses.
-
How to avoid Bank
One strategy to avoid bank conflicts is by ensuring that the memory addresses accessed by threads are distributed on different banks. This can be achieved through reasonable data layout and access patterns. For example, in matrix multiplication, bank conflicts can be reduced by using blocks of shared memory to rearrange data access patterns.
Summary Understanding and avoiding bank conflicts is an important aspect of optimizing CUDA programs, especially when using shared memory to store frequently accessed data. You can improve program performance by modifying your data access patterns and data structures to minimize bank conflicts.
2.2 Case
The simplest understanding is that it was [ty][tx] =====> [tx][ty] before. The left picture is bank conflict, and the right picture is the distribution of solving bank conflict.


2.2.1 Create bank conflict
/*
Use shared memory to store the data required to calculate a tile in blocks into memory with fast access speed.
*/
__global__ void MatmulSharedStaticConflictKernel(float *M_device, float *N_device, float *P_device, int width){
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];
/*
For x and y, index based on blockID, tile size and threadID
*/
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* For each element of P, we only need to loop through width / tile_width times and it will be okay. This is a bit convoluted. Let’s draw a picture to understand it*/
for (int m = 0; m < width / BLOCKSIZE; m + + ) {
/* In order to achieve bank conflict here, the order of tx and tx is reversed, and the index is also changed*/
M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];
N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k + + ) {
P_element + = M_deviceShared[tx][k] * N_deviceShared[k][ty];
}
__syncthreads();
}
/* Column priority */
P_device[x * width + y] = P_element;
}
2.2.2 Use pad to resolve bank conflicts
__global__ void MatmulSharedStaticConflictPadKernel(float *M_device, float *N_device, float *P_device, int width){
/* Add a padding to prevent bank conflicts from occurring. Let’s understand it with the help of the picture*/
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
/*
For x and y, index based on blockID, tile size and threadID
*/
int x = blockIdx.x * BLOCKSIZE + threadIdx.x;
int y = blockIdx.y * BLOCKSIZE + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* For each element of P, we only need to loop through width / tile_width times and it will be okay. This is a bit convoluted. Let’s draw a picture to understand it*/
for (int m = 0; m < width / BLOCKSIZE; m + + ) {
/* In order to achieve bank conflict here, the order of tx and tx is reversed, and the index is also changed*/
M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];
N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k + + ) {
P_element + = M_deviceShared[tx][k] * N_deviceShared[k][ty];
}
__syncthreads();
}
/* Column priority */
P_device[x * width + y] = P_element;
}
even though
Input size is 4096 x 4096 matmul in gpu(warmup) uses 113.364067 ms matmul in gpu(general) uses 114.303902 ms matmul in gpu(shared memory(static)) uses 73.318878 ms matmul in gpu(shared memory(static, bank conf)) uses 141.755173 ms matmul in gpu(shared memory(static, pad resolve bank conf)) uses 107.326782 ms matmul in gpu(shared memory(dynamic)) uses 90.047234 ms matmul in gpu(shared memory(dynamic, bank conf) uses 191.804550 ms matmul in gpu(shared memory(dynamic, pad resolve bank conf)) uses 108.733856 ms
It is a common optimization strategy to avoid bank conflicts by choosing appropriate data access patterns when designing kernel functions.
In CUDA programming, the generally recommended approach is:
-
Row-first access: Because CUDA’s memory is stored in row-first order, row-first access can better utilize memory bandwidth and reduce bank conflicts.
-
Proper data alignment: Bank conflicts can also be reduced by ensuring alignment of data structures. For example, padding can be used to ensure that each row of the matrix is a fixed number of words long.
① Exclusive video courses on the entire network
BEV perception, millimeter wave radar vision fusion, Multi-sensor calibration, Multi-sensor fusion, Multi-mode Dynamic 3D target detection,Point cloud 3D target detection,Target tracking,Occupancy,cuda and TensorRT model deployment< /strong>, Collaborative sensing,Semantic segmentation,Autonomous driving simulation,Sensor deployment, strong>Decision planning, trajectory prediction and other multi-directional learning videos (Scan the QR code to learn)

Video official website: www.zdjszx.com
② China’s first autonomous driving learning community
A communication community of nearly 2,000 people, involving 30+ autonomous driving technology stack learning routes. Want to know more about autonomous driving perception (2D detection, segmentation, 2D/3D lane lines, BEV perception, 3D target detection, Occupancy, multi-sensor fusion, Technical solutions in the fields of multi-sensor calibration, target tracking, optical flow estimation), autonomous driving positioning and mapping (SLAM, high-precision maps, local online maps), autonomous driving planning control/trajectory prediction, AI model deployment and implementation, industry trends, The job is posted. Welcome to scan the QR code below and join the Knowledge Planet of the Heart of Autonomous Driving.This is a place with real information. You can communicate with the big guys in the field about various problems in getting started, studying, working, and changing jobs, and share daily. Paper + code + video, looking forward to the exchange!

③【Heart of Autonomous Driving】Technical Exchange Group
The Heart of Autonomous Driving is the first autonomous driving developer community, focusing ontarget detection, semantic segmentation, panoramic segmentation, instance segmentation, key point detection, lane lines, target tracking, 3D target detection, BEV perception, multi-modal perception , Occupancy, multi-sensor fusion, transformer, large model, point cloud processing, end-to-end autonomous driving, SLAM, optical flow estimation, depth estimation, trajectory prediction, high-precision map, NeRF, planning control, model deployment and implementation, autonomous driving simulation Testing, product manager, hardware configuration, AI job search communicationetc. Scan the QR code to add Autobot Assistant WeChat invitation to join the group, note: school/company + direction + nickname (quick way to join the group)

④【Heart of Autonomous Driving】Platform Matrix, Welcome to contact us!
