After AstBuilder processing, the Unresolved LogicalPlan was obtained. There are two objects that have not been resolved in the logical operator tree: UnresolvedRelation and UnresolvedAttribute. The main role of the Analyzer is to parse these two nodes or expressions into typed objects. In this process, Catalog related information is needed.
Because it inherits from the RuleExecutor class, the Analyzer execution process will call the run method implemented in its parent class RuleExecutor. The main difference is that the Analyzer redefines a series of rules, namely the member variable batches in the RuleExecutor class, as shown below shown.

In Spark version 2.1, Analyzer defines 6 Batch by default, with a total of 34 built-in rules plus additional implemented extended rules (extendedResolutionRules in the figure above). Before analyzing the Analyzed LogicalPlan generation process, these batches will be briefly introduced, and readers can read them in conjunction with the code.
Note: There are many rules used in Analyzer, and it is inconvenient to analyze them one by one due to space limitations. This section only provides an overview of these rules and introduces the main role of the rules from a macro level, aiming to grasp the outline of the rule system. Subsequent chapters will explain the commonly used important rules during specific query analysis.
(1)Batch Substitution
As the name suggests, Substitution means substitution, so this Batch acts like a substitution operation on nodes. Currently, in the Substitution Batch, 4 rules are defined, namely CTESubstitution, WindowsSubstitution, EliminateUnions and SubstituteUnresolvedOrdinals.
- CTESubstitution: CTE corresponds to the With statement, which is mainly used for subquery modularization in SQL, so the CTESubstitution rule is used to process the With statement. In the process of traversing the logical operator tree, when the With(child, relations) node is matched, the child LogicalPlan is replaced with the parsed CTE. Due to the existence of CTE, SparkSqlParser will generate multiple LogicalPlans after parsing SQL statements from left to right. The function of this rule is to merge multiple LogicalPlans into one LogicalPlan.
- WindowsSubstitution: Search the current logical operator tree. When the WithWindowDefinition(windowDefinitions, child) expression is matched, convert the unresolved window function expression (Unresolved-WindowExpression) in its child node into a window function expression (WindowExpression). ).
- EliminateUnions: When the Union operator node has only one child node, the Union operation does not actually play a role. In this case, the Union node needs to be eliminated. In the process of traversing the logical operator tree, this rule will replace Union(children) with the children.head node when it matches Union(children) and the number of children is only 1.
- SubstituteUnresolvedOrdinals: Starting from version 2.0, Spark supports using constants to represent column subscripts in the “Order By” and “Group By” statements. For example, assuming a row of data includes 3 columns A, B, and C, then 1 corresponds to column A, 2 corresponds to column B, and 3 corresponds to column C; in this case, “Group By 1, 2” is equivalent to “Group By A, B” statement. Before version 2.0, this writing method would be directly ignored as a constant. In the new version, this feature is set through the configuration parameters “spark.sql.orderByOrdinal” and “spark.sql.groupByOrdinal”. The default is true, indicating that this feature is enabled. The function of the SubstituteUnresolvedOrdinals rule is to replace the subscript with the UnresolvedOrdinal expression based on these two configuration parameters to map to the corresponding column.
(2)Batch Resolution
This Batch contains the most common parsing rules in Analyzer, as shown in the table below. The order from top to bottom of the rules in the table is also the order in which the rules are executed by RuleExecutor.
According to the table, 25 analysis rules have been added to Resolution, as well as an extendedResolutionRules extended rule list to support Analyzer subclasses in adding new analysis rules to the extended rule list. Generally speaking, these rules in the table involve common data sources, data types, data conversion and processing operations, etc. It is easy to see from the rule names that these rules are targeted at specific operator nodes. For example, the ResolveUpCast rule is used for data type conversion from DataType to DataType. Considering that these rules will be involved in subsequent specific query analysis, the analysis will not be carried out here.
(3)Batch Nondeterministic?PullOutNondeterministic
This Batch only contains the PullOutNondeterministic rule, which is mainly used to extract the nondeterministic (uncertain) expressions of non-Project or non-Filter operators in LogicalPlan, and then place these expressions in the inner Project operator or in the final Project operator.
(4)Batch UDF?HandleNullInputsForUDF
For the UDF rule, Batch is mainly used to perform some special processing on user-defined functions. The Batch only has one rule, HandleNullInputsForUDF, in the Spark2.1 version. The HandleNullInputsForUDF rule is used to handle the situation where the input data is Null. The main idea is to traverse expressions from top to bottom (transform ExpressionsUp). When an expression of the ScalaUDF type is matched, an If expression will be created to convert the Null value. examine.

(5)Batch FixNullability?FixNullability
This Batch only contains one rule, FixNullability, which is used to uniformly set the nullable attribute of expressions in LogicalPlan. In programming interfaces such as DataFrame or Dataset, user code may change the nullability attribute of certain columns (AttribtueReference), resulting in abnormal results in subsequent judgment logic (such as isNull filtering, etc.). In the FixNullability rule, perform the transform Expressions operation on the parsed LogicalPlan. If a column comes from its child node, its nullability value is set according to the output information corresponding to the child node.
(6)Batch Cleanup?CleanupAliases
This Batch only contains the CleanupAliases rule, which is used to delete useless alias information in LogicalPlan. Generally speaking, only the highest-level expressions of Project, Aggregate or Window operators in the logical operator tree (corresponding to project list, aggregate expressions and window expressions respectively) require aliases. CleanupAliases uses the trimAliases method to delete aliases in expression execution.
The above content introduces the overall analysis rules built into Spark 2.1 version Analyzer. During the evolution of different versions, these rules will also change, and readers can analyze them by themselves. Now go back to the Unresolved LogicalPlan generated in the previous case query. The following content will focus on the detailed process of Analyzer analyzing the logical operator tree.
As you can see in the QueryExecution class, what triggers the execution of Analyzer is the execute method, that is, the execute method in RuleExecutor. This method will call the rules cyclically to analyze the logical operator tree.
val analyzed: LogicalPlan = analyzer.execute(logical)
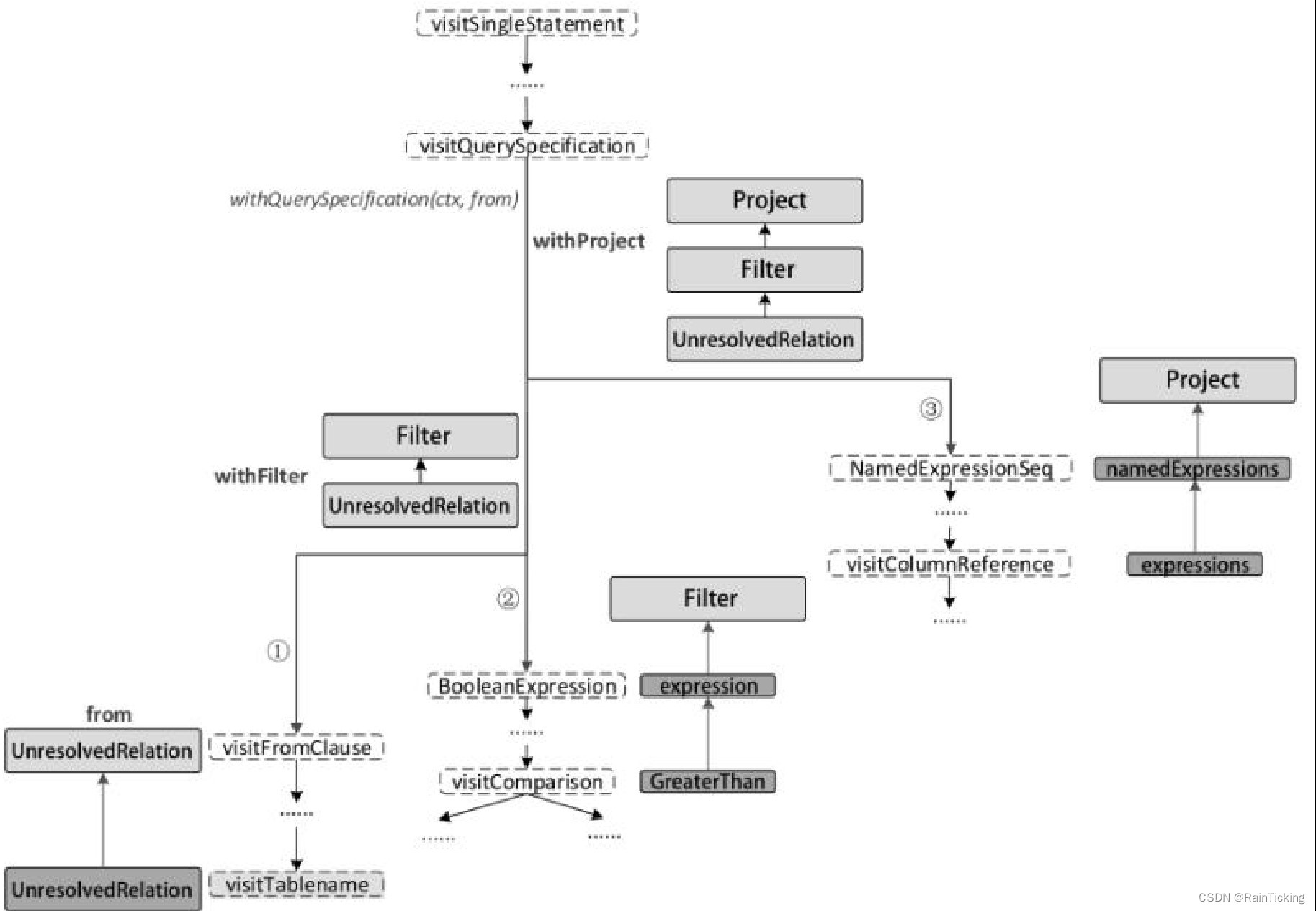
For the Unresolved LogicalPlan in the above figure, the first thing matched in the Analyzer is the ResolveRelations rule. The execution process is shown in the figure below, which is also the first step in Analyzed LogicalPlan generation.

object ResolveRelations extends Rule[LogicalPlan] {<!-- -->
private def lookupTableFromCatalog(u: UnresolvedRelation): LogicalPlan = {<!-- -->
try {<!-- -->
catalog.lookupRelation(u.tableIdentifier, u.alias)
} catch {<!-- -->
case _: NoSuchTableException => u.failAnalysis(s "Table or view not found: ${u.tableName}")
}
}
def apply(paln: LogicalPlan): LogicalPlan = plan resolveOperators {<!-- -->
case i @InsertIntoTable(u: UnresolvedRelation, parts, child, _, _)
if child.resolved => i.copy(table = EliminateSubqueryAliases(lookupTableFromCatelog(u)))
case u: UnresolvedRelation =>
val table = u.tableIdentifier
if(table.database.isDefined & amp; & amp; conf.runSQLonFile & amp; & amp; !catalog.isTemporaryTable(table)
& amp; & amp; (!catalog.databaseExists(table.database.get) || !catalog.tableExists(table))) {<!-- -->
u
} else {<!-- -->
lookupTableFromCatalog(u)
}
}
}
As can be seen from the above implementation of ResolveRelations, when the UnresolvedRelation node is matched during the traversal of the logical operator tree, in this example, the lookupTableFromCatalog method will be directly called to look up the table from the SessionCatalog. In fact, the table has been created in the previous step of the case SQL query and stored in InMemoryCatalog as LogicalPlan type. Therefore, the lookupTableFromCatalog method can directly obtain the analyzed LogicalPlan based on its table name.
It should be noted that after the Catalog table is looked up, an alias node will be inserted into the Relation node. In addition, the number after the column in Relation represents the subscript. Pay attention to its data type. Age and id are both set to Long type (“L” character) by default.
Next, enter step 2 and execute the ResolveReferences rule. The resulting logical operator tree is as shown in the figure below. It can be seen that the other nodes have not changed, mainly because the age information in the Filter node has changed from the Unresolved state to the Analyzed state (the prefix character single quote indicating the Unresolved state has been removed).

The matching logic related to this example in the ResolveReferences rule is as shown in the following code. When UnresolvedAttribute is encountered, the resolveChildren method defined in LogicalPlan is called to analyze the expression. It should be noted that resolveChildren does not guarantee a successful analysis. When analyzing the corresponding expression, it needs to be judged based on the output information of the child node of the LogicalPlan node where the expression is located. When analyzing the age attribute in the Filter expression, because the sub-node Relation of the Filter is already in the resolved state, it can succeed; when analyzing the name attribute of the expression in the Project, because the sub-node Filter of the Project is in the resolved state at this time It is still in the unresolved state (Note: Although the age column has been analyzed, there is still a Literal constant expression “18” in the entire Filter node that has not been analyzed), so the parsing operation cannot succeed and will be parsed in the next round of rule calls. .
object ResolveReferences extends Rule[LogicalPlan] {<!-- -->
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {<!-- -->
case q: LogicalPlan =>
q transformExpressionsUp {<!-- -->
case u @UnresolvedAttribute(nameParts) =>
val result = withPosition(u) {<!-- -->
q.resolveChildren(nameParts, resolver).getOrElse(u)
}
result
case UnresolvedExtractValue(child, fieldExpr)
if child.resolved => ExtractValue(child, fieldExpr, resolver)
}
}
}
After completing step 2, the ImplicitTypeCasts rule in the TypeCoercion rule set will be called to implicitly convert the data type in the expression. This is the third step generated by Analyzed LogicalPlan, as shown in the figure below. Because in Relation, the data type of the age column is Long, and the value “18” in Filter is generated as IntegerType in Unresolved LogicalPlan, so the constant “18” needs to be converted to Long type.

The above analysis and conversion process is shown in the figure above. You can see that the constant expression “18” is replaced by the “cast(18 as bigint)” expression (Note: In the Spark SQL type system, BigInt corresponds to the Long type in Java) . The processing process of the case’s logical operator tree by the ImplicitTypeCasts rule is as shown in the following code. For BinaryOperator expressions, this rule calls findTightestCommonTypeOfTwo to find the best common data type for the left and right expression nodes. After parsing the rule, you can see that the Filter node in the above figure has changed to the Analyzed state, and the node character prefix single quote has been removed.
object ImplicitTypeCasts extends Rule[LogicalPlan] {<!-- -->
def apply(plan: LogicalPlan): LogicalPlan = plan resolvedExpressions {<!-- -->
case b @BinaryOperator(left, right)
if left.dataType != right.dataType =>
findTightestCommonTypeOfTwo(left.dataType, right.dataType).map {<!-- -->
commonType =>
if(b.inputType.acceptsType(commonType)) {<!-- -->
val newLeft = if(left.dataType == commonType) left else Cast(left, commonType)
val newRight = if(right.dataType = commonType) right else Cast(right, commonType)
b.withNewChildren(Seq(newLeft, newRight))
} else {<!-- -->
b
}
}.getOrElse(b)
}
}
After the analysis of the above three rules, the remaining rules have no effect on the logical operator tree. At this time, there are still Project nodes in the logical operator tree that have not been parsed, and the next round of rules will be applied. The fourth and final step is to execute the ResolveReferences rule again.
As shown in the figure below, the Filter node is already in the resolved state after the previous step, so the Project node in the logical operator tree can complete the resolution. The “name” of the Project node is parsed as “name#2”, where “2” represents the subscript of name in all columns.

At this point, Analyzed LogicalPlan is completely generated. As can be seen from the above steps, the analysis of logical operator trees is a continuous iterative process. In fact, users can set the number of rounds of RuleExecutor iterations through the parameter (spark.sql.optimizer.maxIterations). The default configuration is 50 rounds. For some special SQL with deep nesting, the number of rounds can be increased appropriately.