This blog is a previous article:
- Elasticsearch: RAG using Open AI and Langchain – Retrieval Augmented Generation (1)
- Elasticsearch: RAG using Open AI and Langchain – Retrieval Augmented Generation (2)
-
Elasticsearch: RAG using Open AI and Langchain – Retrieval Augmented Generation (3)
’s continuation. In this article, we will learn how to pass search results from Elasticsearch to big data models to get better results.

If you haven’t created your own environment yet, please refer to the first article for detailed installation.
For large text documents, we can use the following architecture:
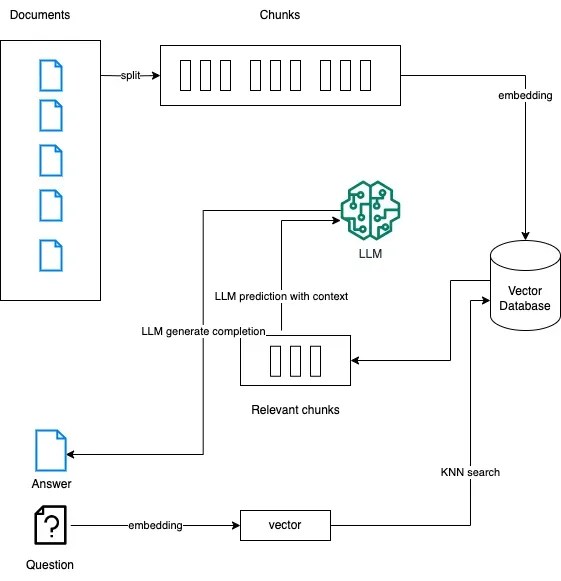
Create an application and display it
Installation package
#!pip3 install langchain
Import package
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.runnable import RunnableLambda
from langchain.schema import HumanMessage
from urllib.request import urlopen
import os, json
load_dotenv()
openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
elastic_index_name='langchain-rag'
Add documents and divide documents into paragraphs
with open('workplace-docs.json') as f:
workplace_docs = json.load(f)
print(f"Successfully loaded {len(workplace_docs)} documents")

metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append({
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions":doc["rolePermissions"]
})
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)

Index Documents using ELSER – SparseVectorRetrievalStrategy()
from elasticsearch import Elasticsearch
url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
connection = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
es = ElasticsearchStore.from_documents(
docs,
es_url = url,
es_connection = connection,
es_user=elastic_user,
es_password=elastic_password,
index_name=elastic_index_name,
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)

If you have not configured your own ELSER, please refer to the previous article “Elasticsearch: RAG using Open AI and Langchain – Retrieval Augmented Generation (3)”.
After executing the above command, we can view it in Kibana:

Show results
def showResults(output):
print("Total results: ", len(output))
for index in range(len(output)):
print(output[index])
Search
r = es.similarity_search("work from home policy")
showResults(r)

RAG with Elasticsearch – Method 1 (Using Retriever)
retriever = es.as_retriever(search_kwargs={"k": 4})
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI()
| StrOutputParser()
)
chain.invoke("vacation policy")

RAG with Elasticsearch – Method 2 (Without Retriever)
Add Context
def add_context(question: str):
r = es.similarity_search(question)
context = "\\
".join(x.page_content for x in r)
return context
Chain
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": RunnableLambda(add_context), "question": RunnablePassthrough()}
| prompt
| ChatOpenAI()
| StrOutputParser()
)
chain.invoke("canada employees guidelines")

Compare with RAG and without RAG
q = input("Ask Question: ")
## Question to OpenAI
chat = ChatOpenAI()
messages = [
HumanMessage(
content=q
)
]
gpt_res = chat(messages)
# Question with RAG
gpt_rag_res = chain.invoke(q)
#Responses
s = f"""
ChatGPT Response:
{gpt_res}
ChatGPT with RAG Response:
{gpt_rag_res}
"""
print(s)


The code of the above jupyter notebook can be downloaded at the address https://github.com/liu-xiao-guo/semantic_search_es/blob/main/RAG-langchain-elasticsearch.ipynb.
The knowledge points of the article match the official knowledge files, and you can further learn relevant knowledge. Python entry skill treeHomepageOverview 383353 people are learning the system