Directory
- question
- primary method
-
- Import Data
- Observation data
- Processing ideas and code
- Advanced method
-
- Import & observe data
- Processing ideas and code
-
- Step by step version:
-
- Extract column index
- Extract row index
- Extract value
- Build a new data frame
- Transpose
- Function version:
Question
Due to business requirements, Table A needs to be converted into Table B to facilitate subsequent association of other information and analysis of product delivery status.


Primary method
The key functions used are: fillna(), MultiIndex.from_product(), stack(), reset_index()
Import data
Import xlsx using pd.read_excel()
It should be noted that pandas uses the xlrd package to import xlsx, and only the old version of the xlrd (1.2.0) package supports importing xlsx files. The latest version of the xlrd package does not support xlsx but supports xls.
import pandas as pd df_raw = pd.read_excel(r'XXXXX\practice.xlsx')
Observation data
After importing the data, you need to perform corresponding operations according to the format presented by the data.
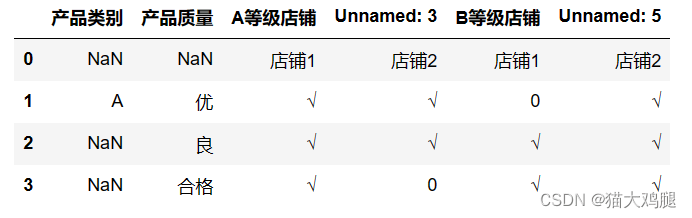
As can be seen:
- Stores that are column information in excel become row information after being read;
- The merged cells are split, and only one cell has information after the split.
Processing ideas and code
- Set the product category and product quality fields to index, then set the store level and store to multi-level columns;
- Use stack() to transpose the table. At this time, the multi-level columns also become index;
- Use reset_index() to restore index to column and that’s it.
first step:
from collections import OrderedDict #This package is used to generate a column name list with deduplication and unchanged order.
def remove_duplicates(lst):#Define a function that removes duplicates from a list and does not change the order
return list(OrderedDict.fromkeys(lst))
df = df_raw.copy()
df.fillna(method = 'ffill',inplace = True)
#Generate a second-level column list
col_index = remove_duplicates(df.iloc[0,:][df.iloc[0,:].notna()].to_list())
#Delete the first line
df = df.drop(0,axis = 0)
#set_index
df = df.set_index(['product category','product quality'])
#Add columns index
col_index2 = [x for x in df.columns.to_list() if 'Unnamed'not in x ]#Generate the first-level column name list. This step must be done after set_index, otherwise the redundant column names will be included.
columns_multiindex = pd.MultiIndex.from_product([col_index2,col_index], names=['store level', 'store'])
df.columns=columns_multiindex
After adding index and multi-level columns, the effect is as follows:

Steps 2 and 3:
#stack, convert column index into index (analogous to the row and column transposition operation in excel), and then restore all indexes to columns through reset_index df = df.stack(['store level', 'store']).reset_index() df
Effect:

PS: After such an operation, I finally have a deeper understanding of the index of dataframe, and the concepts of iloc and loc are also clear.
Advanced methods
When processing tabular data in actual work, I found that the above method only applies to the following column names with inclusion relationships (the main reason is the use of MultiIndex.from_product): 
But when the relationship becomes more complex… it doesn’t apply:

Import & Observe Data

It can still be seen:
- The column information in Excel becomes row information after reading;
- The merged cells are split, and only the leftmost cell has information after the split.
Processing ideas and code
The overall idea is similar to that in the primary method. It still operates around the index of the data frame. Before stack(), the row index, column index and value are extracted and processed respectively to build a new data frame. The overall steps and functions are instead Much simpler.

Step-by-step version:
Extract column index
Extract column indexes (including the current column index) as values and fill the rows with null values.
df_column = df.iloc[0:4,2:]
df_cols = pd.DataFrame([df_column.columns.to_list()],columns = df_column.columns.to_list(),index = [0])
df_column = pd.concat([df_cols,df_column]).reset_index(drop = True)
df_column.loc[0,df_column.loc[0,:].str.contains('Unnamed') == True] = np.nan
df_column.fillna(method = 'ffill',inplace = True,axis = 1)

Extract row index
Extract row index
df_index = df.loc[:,['Column Name 1', 'Column Name 2']] #df_index.fillna(method = 'ffill',inplace = True) df_index = df_index.drop([0,1,2,3],axis = 0).reset_index(drop = True) df_index
Note: When slicing df and passing it to a new variable df_index = df.loc[:,['Column Name 1', 'Column Name 2']], you need to use iloc or loc, otherwise it will appear SettingWithCopyWarning.
Extract value
df_value = df.iloc[4:,2:] df_value

Build a new data frame
df_value.index = df_index.T.values.tolist() df_value.columns = df_column.values.tolist() df_value.index.names = ['Column Name 1', 'Column Name 2'] #The name here is the name of the row index df_value.columns.names = ['colname1','colname2','colname3','colname4','colname5']#The name here is the name of the column index #Row index names and column index names appear as column names in the final result table

The result presented in jupyter is like this. It seems that there is no alignment, which may cause misunderstanding. In fact, it is in the desired form. You can export it to csv to verify:

Transpose
df_new = df_value.stack(['colname1','colname2','colname3','colname4','colname5']).reset_index()
NA lines are also automatically removed

Function version:
def multicolumnlevel_to_one(raw_dataframe,row_level_cnt,column_level_cnt,row_index_name,column_index_name):
#raw_dataframe: The pending table dataframe requires deletion of unnecessary columns
#row_level_cnt: Number of row index columns in the original table int
#column_level_cnt: Number of column name levels in the original table int
#row_index_name: The column name of the column that needs to be set as the row index. The order of the list is from left to right. The name of the column to be used as the row index.
#column_index_name: column index name list order is different column names from top to bottom
if column_level_cnt >= 2:
#step 1 Extract column index
df_column = raw_dataframe.iloc[:(column_level_cnt-1),row_level_cnt:]
df_cols = pd.DataFrame([df_column.columns.to_list()],columns = df_column.columns.to_list(),index = [0])
df_column = pd.concat([df_cols,df_column]).reset_index(drop = True)
df_column.loc[0,df_column.loc[0,:].str.contains('Unnamed') == True] = np.nan
df_column.fillna(method = 'ffill',inplace = True,axis = 1)
#step 2 Extract row index
df_index = raw_dataframe.loc[:,row_index_name]
df_index.fillna(method = 'ffill',inplace = True)
df_index = df_index.drop(list(range(column_level_cnt-1)),axis = 0).reset_index(drop = True)
#step 3 Extract value
df_value = raw_dataframe.iloc[(column_level_cnt-1):,row_level_cnt:]
#step 4 Build a new data frame
df_value.index = df_index.T.values.tolist()
df_value.columns = df_column.values.tolist()
df_value.index.names = row_index_name
df_value.columns.names = column_index_name
#step 5 Transpose
df_new = df_value.stack(column_index_name).reset_index()
else: #If there is only one row of column names
df_new = raw_dataframe.set_index(row_index_name)
df_new.columns.name = column_index_name[0]
df_new = df_new.stack().reset_index()
return df_new
The function also satisfies the following transposition of tables:

End
