When I first learned the operating system, I was always confused, why there is a semaphore mechanism in the process synchronization and mutual exclusion mechanism, and there is a semaphore mechanism in the process communication, and then you look at the summary of various interview questions or blogs on the Internet, You will find that many of the same process communication mechanisms are there? Few people care about process synchronization and mutual exclusion mechanisms. After reading too much, I want to screen CSDN…, I finally know the truth, I just want to say why I can’t write things clearly in a blog, it’s really a waste of time without beginning and end.
I hope this article can save a friend who was stunned like me for a certain period of time. I have already talked about the synchronization and mutual exclusion mechanism between processes in the last article. It is better for you friends to look at process communication after reading this.
The contextual mind map of the full text is as follows:

1. What is process communication
As the name implies, InterProcess Communication (IPC) refers to the exchange of information between processes. In fact, process synchronization and mutual exclusion are essentially a kind of process communication (this is why we will see semaphore and PV operations in the process communication mechanism later), but it only transmits semaphores. By modifying the semaphore, the processes can establish a connection, coordinate with each other and work together, but it lacks the ability to transfer data.
Although there are some situations where the amount of information exchanged between processes is very small, such as only a certain state information is exchanged, the synchronization and mutual exclusion mechanisms of such processes are fully capable of this job. But in most cases, a large amount of data needs to be exchanged between processes, such as transferring a batch of information or an entire file, which requires a new communication mechanism, which is the so-called process communication.
Let’s look at some process communication intuitively from the operating system level: We know that in order to ensure security, the user address space of each process is independent. Generally speaking, a process cannot directly access the address space of another process, but the kernel space is Each process is shared, so information exchange between processes must go through the kernel.
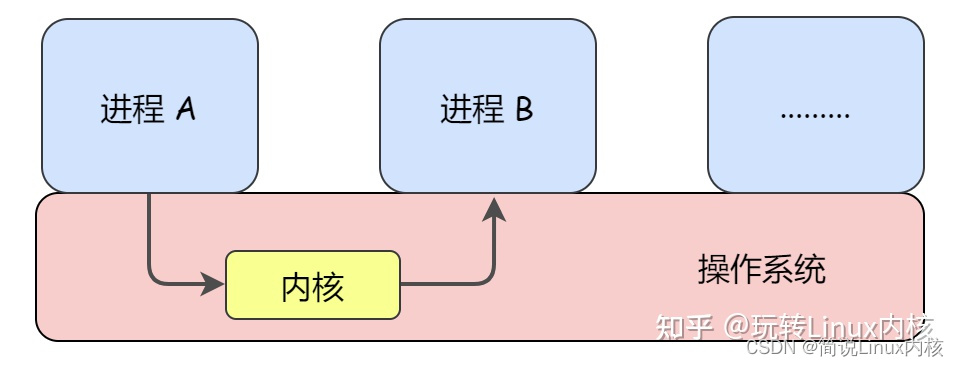
Let’s list the common process communication mechanisms provided by the Linux kernel:
-
pipes (also known as shared files)
-
Message Queuing (also known as Messaging)
-
Shared memory (also known as shared storage)
-
Semaphore and PV operations
-
Signal
-
Socket
2. Pipeline
anonymous pipe
If you have learned Linux commands, you must be familiar with pipelines. Linux pipelines use vertical bars | to connect multiple commands, which is called the pipeline symbol.
$ command1 | command2
The above line of code constitutes a pipeline. Its function is to use the output of the previous command (command1) as the input of the next command (command2). From this function description, we can see that the data in the pipeline can only be One-way flow, that is, half-duplex communication, if we want to achieve mutual communication (full-duplex communication), we need to create two pipes.
In addition, the pipe created by the pipe character | is an anonymous pipe, which will be automatically destroyed when it is used up. Also, anonymous pipes can only be used between processes that have an affinity (parent-child process). In other words, anonymous pipes can only be used for communication between parent and child processes.
In the actual coding of Linux, the anonymous pipe is created through the pipe function. If the creation is successful, it returns 0, and if the creation fails, it returns -1:
int pipe (int fd[2]);
This function takes an array of file descriptors with storage space 2:
-
fd[0] points to the read end of the pipe, fd[1] points to the write end of the pipe
-
The output of fd[1] is the input of fd[0]
Roughly explain the steps to implement inter-process communication through anonymous pipes:
1) The parent process creates two anonymous pipes, pipe 1 (fd1[0] and fd1[1]) and pipe 2 (fd2[0] and fd2[1]);
Because the data of the pipeline flows in one direction, two pipelines are required to achieve two-way data communication, one in each direction.
2) The parent process forks out the child process, so for the two anonymous pipes, the child process also has two file descriptors pointing to the read and write ends of the anonymous pipe;
3) The parent process closes the read end fd1[0] of pipe 1 and the write end fd2[1] of pipe 2, and the child process closes the write end fd1[1] of pipe 1 and the read end fd2[0] of pipe 2. In this way, Pipe 1 can only be used for parent process writing and child process reading; pipe 2 can only be used for parent process reading and child process writing. The pipeline is implemented with a ring queue, and data flows in from the write end and out from the read end, which realizes two-way communication between the parent and child processes.

After reading the above descriptions, let’s understand what the essence of the pipeline is: for the processes at both ends of the pipeline, the pipeline is a file (this is why the pipeline is also called a shared file mechanism), but it is not Ordinary files do not belong to a certain file system, but stand on their own, constitute a file system alone, and only exist in memory.
To put it simply, the essence of the pipeline is that the kernel opens up a buffer in the memory, which is associated with the pipeline file, and the operation on the pipeline file is converted by the kernel into an operation on this buffer.
famous pipeline
Since anonymous pipes have no names, they can only be used for communication between parent and child processes. In order to overcome this shortcoming, the well-known pipeline is proposed, also known as FIFO, because the data is transmitted in a first-in, first-out manner.
The so-called named pipe is to provide a path name associated with it, so that even processes that have no relationship with the process that created the named pipe can communicate with each other through the named pipe as long as they can access the path.
Use the Linux command mkfifo to create named pipes:
$ mkfifo myPipe
myPipe is the name of the pipe. Next, we write data to the named pipe myPipe:
$ echo "hello" > myPipe
After executing this line of command, you will find that it stops here. This is because the content in the pipeline has not been read, and the command can exit normally only after the data in the pipeline has been read. So, we execute another command to read the data in this well-known pipe:
$ cat < myPipe hello
3. Message queue
It can be seen that although the process communication method of the pipeline is simple to use, the efficiency is relatively low, and it is not suitable for frequent data exchange between processes, and the pipeline can only transmit unformatted byte streams. For this reason, the message passing mechanism (called message queue in Linux) was applied. For example, if process A wants to send a message to process B, process A can return normally after putting the data in the corresponding message queue, and process B can read data from the message queue by itself when needed. The same is true for process B to send a message to process A.

The essence of the message queue is a linked list of messages stored in memory, and the message is essentially a user-defined data structure. If a process reads a message from the message queue, the message will be deleted from the message queue. Compare the pipeline mechanism:
-
A message queue allows one or more processes to write to or read messages from it.
-
The message queue can realize the random query of messages, and it is not necessary to read the messages in the order of first-in-first-out, but also read them according to the type of the message. Advantages over the first-in-first-out principle of well-known pipes.
-
For message queues, before a process writes a message to a queue, another process does not need to wait for a message to arrive on the message queue. For pipes, unless the reading process already exists, it is meaningless for the writing process to write first.
-
The life cycle of the message queue depends on the kernel. If the message queue is not released or the operating system is not shut down, the message queue will always exist. The anonymous pipe is established with the creation of the process and destroyed with the end of the process.
It is important to note that message queues are useful for exchanging smaller amounts of data because there is no need to avoid collisions. However, when a user process writes data to the message queue in the memory, the process of copying data from the user state to the kernel state will occur; similarly, when another user process reads the message data in the memory, it will copy the data from the kernel state to the message queue. The process of copying data to user mode. Therefore, if the amount of data is large, using the message queue will cause frequent system calls, that is, it will take more time for the kernel to intervene.
4. Shared memory
In order to avoid copying messages and making system calls as frequently as message queues, a shared memory mechanism has emerged.
As the name implies, shared memory is to allow irrelevant processes to connect the same piece of physical memory to their respective address spaces, so that these processes can access the same physical memory, and this physical memory becomes shared memory. If a process writes to shared memory, the changes immediately affect any other process that has access to the same shared memory.
Collect the content of memory management, let’s understand the principle of shared memory in depth. First of all, each process has its own process control block (PCB) and logical address space (Addr Space), and has a corresponding page table, which is responsible for comparing the logical address (virtual address) of the process with the physical address. Mapping, managed by the memory management unit (MMU). The logical addresses of two different processes are mapped to the same area of physical space through the page table, and the area they both point to is the shared memory.

Unlike the frequent system calls of the message queue, for the shared memory mechanism, the system call is only required when the shared memory area is established. Once the shared memory is established, all accesses can be used as regular memory accesses without the use of the kernel. In this way, data does not need to be copied back and forth between processes, so this is the fastest way of process communication.

5. Semaphore and PV operations
In fact, recent research on systems with multiple CPUs shows that message passing actually outperforms shared memory on such systems because message queues do not need to avoid conflicts, whereas shared memory mechanisms can. That is to say, if multiple processes modify the same shared memory at the same time, the content written by the first process will be overwritten by the later one.
Moreover, in a multi-channel batch processing system, multiple processes can be executed concurrently, but due to the limited resources of the system, the execution of the process is not consistent to the end, but stops and starts, advancing at an unpredictable speed ( asynchronicity). But sometimes we hope that multiple processes can cooperate closely and execute in a specific order to achieve a common task.
For example, if there are two processes A and B responsible for reading and writing data respectively, these two threads cooperate and depend on each other. Then writing data should happen before reading data. In fact, due to the existence of asynchrony, the situation of reading first and then writing may occur. At this time, because the buffer has not been written into data, the reading process A has no data to read, so the reading process A is blocked.

Therefore, in order to solve the above two problems, ensure that only one process is accessing shared memory at any time (mutual exclusion), and enable processes to access shared memory in a specific order (synchronization), we can use process synchronization And mutual exclusion mechanism, common such as semaphore and PV operation.
Information through train: the latest Linux kernel source code documentation + video information
Kernel learning address: Linux kernel source code/memory tuning/file system/process management/device driver/network protocol stack
Process synchronization and mutual exclusion are actually a protection mechanism for process communication. They are not used to transmit the content of real communication between processes, but because they transmit semaphores, they are also included in the category of process communication, called Low level communication.
The following content is similar to what was said in the previous article [After reading the process synchronization and mutual exclusion mechanism, I finally fully understand the PV operation]. Friends who have read it can skip directly to the next topic.
A semaphore is actually a variable. We can use a semaphore to represent the quantity of a certain resource in the system. For example, if there is only one printer in the system, a semaphore with an initial value of 1 can be set.
The user process can operate on the semaphore by using a pair of primitives provided by the operating system, so that it is very convenient to realize process mutual exclusion or synchronization. This pair of primitives is the PV operation:
1) P operation: decrement the semaphore value by 1, indicating that the application occupies a resource. If the result is less than 0, indicating that no resources are available, the process performing the P operation is blocked. If the result is greater than or equal to 0, it means that the existing resources are enough for you to use, and the process of executing the P operation continues.
It can be understood that when the value of the semaphore is 2, it means that there are 2 resources available, and when the value of the semaphore is -2, it means that there are two processes waiting to use this resource. I really can’t understand the V operation without reading this sentence. After reading it, I suddenly woke up like a dream.
2) V operation: Add 1 to the semaphore value, indicating that a resource is released, that is, the resource is returned after the resource is used up. If the value of the semaphore is less than or equal to 0 after adding, it means that some processes are waiting for the resource. Since we have released a resource, we need to wake up a process waiting to use the resource (ready state) to make it run. .
I think what I have said is simple enough, but you may still be confused about the V operation. Let’s look at two more questions and answers about the V operation:
Question: If the value of the semaphore is greater than 0, it means that there are shared resources available. Why is there no need to wake up the process at this time?
Answer: The so-called wake-up process is to wake up the process from the ready queue (blocking queue), and the value of the semaphore is greater than 0, indicating that there are shared resources available, that is to say, no process is blocked on this resource at this time, so there is no need to wake up , it can run normally.
Question: When the value of the semaphore is equal to 0, it means that there is no shared resource available. Why do you need to wake up the process?
Answer: The V operation is to add 1 to the value of the semaphore first, that is to say, the value of the semaphore becomes 0 after adding 1. Before that, the value of the semaphore is -1, that is, a process is waiting This shared resource, we need to wake it up.
The specific definitions of semaphore and PV operations are as follows:

Mutually exclusive access to shared memory
Mutually exclusive access to shared memory by different processes can be achieved in two steps:
-
Define a mutex semaphore and initialize it to 1
-
Place access to shared memory between P and V operations

P operation and V operation must appear in pairs. The lack of P operation cannot guarantee exclusive access to shared memory, and the lack of V operation will cause the shared memory to never be released, and the process in the waiting state will never be woken up.

Realize process synchronization
Looking back at process synchronization, it is necessary for each concurrent process to run in an orderly manner as required.
For example, the following two processes P1 and P2 are executed concurrently. Due to the asynchronous nature, the order in which the two progress alternately is uncertain. Assuming that “Code 4” of P2 can only be executed based on the running results of “Code 1” and “Code 2” of P1, then we must ensure that “Code 4” must be executed after “Code 2”.

If “Code 4” of P2 can only be executed based on the running results of “Code 1” and “Code 2” of P1, then we must ensure that “Code 4” must be executed after “Code 2”.
It is also very convenient to use semaphore and PV operations to realize process synchronization, three steps:
-
Define a synchronization semaphore and initialize it to the number of currently available resources
-
Execute the V operation after the higher-priority operation to release resources
-
Execute the P operation in front of the operation with lower priority to apply for resources

With the following picture to understand intuitively:

6. Signal
Notice! Signals and semaphores are two completely different concepts!
Signal is the only asynchronous communication mechanism in the process communication mechanism, which can send a signal to a process at any time. Notifies the process of the sending of an asynchronous event by sending the specified signal, forcing the process to execute the signal handler. After the signal is processed, the interrupted process will resume execution. Users, the kernel, and processes can generate and send signals.
The sources of signal events mainly include hardware sources and software sources. The so-called hardware source means that we can send signals to the process by inputting certain key combinations through the keyboard. For example, the common key combination Ctrl + C generates a SIGINT signal, indicating that the process is terminated; while the software source is to send signals to the process through the kill series of commands. For example, kill -9 1111 means to send a SIGKILL signal to the process with PID 1111 to end it immediately.
Let’s see what signals are available in Linux:

7, Socket
So far, the five methods introduced above are all used to communicate between processes on the same host. If you want to communicate with processes on different hosts across the network, what should you do? This is what Socket communication does (of course, Socket can also complete process communication with the host).

Socket originated from Unix, and its original meaning is socket. In the field of computer communication, Socket is translated as socket, which is a convention or a way of communication between computers. Through the Socket convention, a computer can receive data from other computers, and can also send data to other computers.
From the perspective of computer network, Socket socket is the cornerstone of network communication and the basic operation unit of network communication supporting TCP/IP protocol. It is an abstract representation of the endpoint in the network communication process, and contains five kinds of information necessary for network communication: the protocol used for connection, the IP address of the local host, the protocol port of the local process, the IP address of the remote host, and the protocol of the remote process port.
The essence of Socket is actually a programming interface (API), which is an intermediate software abstraction layer for communication between the application layer and the TCP/IP protocol family. It encapsulates TCP/IP. It hides the complex TCP/IP protocol suite behind the Socket interface. For users, the network connection can be realized only through a set of simple APIs.
8. Summary
Briefly summarize the process communication mechanisms provided by the above six Linux kernels:
1) First of all, the easiest way is the pipeline. The essence of the pipeline is a special file stored in memory. That is to say, the kernel opens up a buffer in the memory, and this buffer is associated with the pipeline file, and the operation on the pipeline file is converted into an operation on this buffer by the kernel. Pipes are divided into anonymous pipes and named pipes. Anonymous pipes can only communicate between parent and child processes, while famous pipes have no restrictions.
2) Although the pipeline is simple to use, its efficiency is relatively low, and it is not suitable for frequent data exchange between processes, and the pipeline can only transmit unformatted byte streams. Born for this message queue application. The essence of the message queue is a linked list of messages stored in memory, and the message is essentially a user-defined data structure. If a process reads a message from the message queue, the message will be deleted from the message queue.
3) The speed of the message queue is relatively slow, because each data writing and reading needs to go through the data copy process between the user state and the kernel state, and shared memory can solve this problem. The so-called shared memory is: the logical addresses of two different processes are mapped to the same area of physical space through the page table, and the area they point to together is the shared memory. If a process writes to shared memory, the changes immediately affect any other process that has access to the same shared memory.
For the shared memory mechanism, a system call is only required when the shared memory area is established. Once the shared memory is established, all accesses can be used as regular memory accesses without resorting to the kernel. In this way, data does not need to be copied back and forth between processes, so this is the fastest way of process communication.
4) Although the speed of shared memory is very fast, there is a conflict problem. For this reason, we can use semaphores and PV operations to achieve mutual exclusive access to shared memory, and can also achieve process synchronization.
5) Signal and semaphore are two completely different concepts! Signal is the only asynchronous communication mechanism in the process communication mechanism, which can send a signal to a process at any time. Notifies the process of the sending of an asynchronous event by sending the specified signal, forcing the process to execute the signal handler. After the signal is processed, the interrupted process will resume execution. Users, the kernel, and processes can generate and send signals.
6) The five methods described above are all used for communication between processes on the same host. If you want to communicate with processes on different hosts across the network, you need to use Socket communication. In addition, Socket can also complete the process communication with the host.