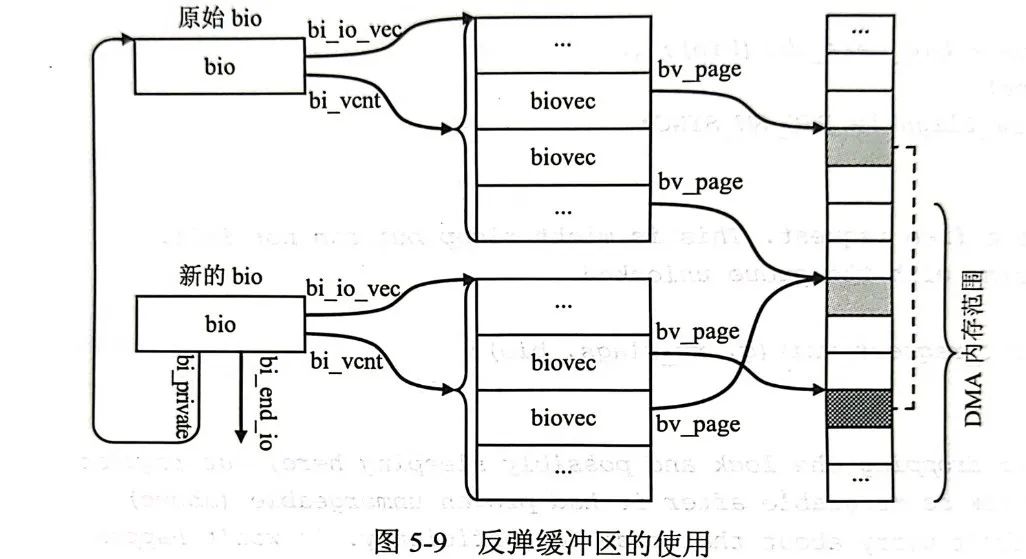
line17 ※1 Bounce buffer
The function of the blk_queue_bounce function is to try to create a bounce buffer. It is usually necessary to create such a special area when the memory area given by bio is at an address that is not reachable by the peripheral device (such as performing DMA on high-end memory) to ensure that The memory area is reachable by peripheral devices, which is a necessary condition for bio to be able to complete.
static inline void blk_queue_bounce(struct request_queue *q, struct bio **bio)
{
if (unlikely(blk_queue_may_bounce(q) & amp; & amp; bio_has_data(*bio))) // Bounce is only needed to carry data
__blk_queue_bounce(q, bio);
}
void __blk_queue_bounce(struct request_queue *q, struct bio **bio_orig)
{
struct bio *bio;
int rw = bio_data_dir(*bio_orig);
struct bio_vec *to, from;
struct bvec_iter iter;
unsigned i = 0;
bool bounce = false;
int sectors = 0;
// For each data segment of bio, check whether bounce is required
bio_for_each_segment(from, *bio_orig, iter) {
if (i + + < BIO_MAX_VECS)
sectors + = from.bv_len >> 9;
if (PageHighMem(from.bv_page))
bounce = true;
}
// There is no high-end memory and it returns directly without bounce.
if (!bounce)
return;
if (sectors < bio_sectors(*bio_orig)) {
bio = bio_split(*bio_orig, sectors, GFP_NOIO, & amp;bounce_bio_split);
bio_chain(bio, *bio_orig);
submit_bio_noacct(*bio_orig);
*bio_orig = bio;
}
// The bounce process requires a new bio
bio = bounce_clone_bio(*bio_orig);
/*
* Bvec table can't be updated by bio_for_each_segment_all(),
* so retrieve bvec from the table directly. This way is safe
* because the 'bio' is single-page bvec.
* This loop traverses the memory area associated with bio
*/
for (i = 0, to = bio->bi_io_vec; i < bio->bi_vcnt; to + + , i + + ) {
struct page *bounce_page;
// Where the peripheral device can be reached, there is no need to move it
if (!PageHighMem(to->bv_page))
continue;
bounce_page = mempool_alloc( & page_pool, GFP_NOIO);
inc_zone_page_state(bounce_page, NR_BOUNCE);
// If it is a write operation, the contents of the original unreachable memory need to be migrated to the bounce buffer.
if (rw == WRITE) {
flush_dcache_page(to->bv_page);
memcpy_from_bvec(page_address(bounce_page), to);
}
// Modify the new pointing relationship, bvec points to the new page
to->bv_page = bounce_page;
}
trace_block_bio_bounce(*bio_orig);
// Mark this as a bounce bio
bio->bi_flags |= (1 << BIO_BOUNCED);
// Replace with bounce's unique bio_end_io function, which will process the corresponding memory and then call the original bio's bio_end_io function.
if (rw == READ)
bio->bi_end_io = bounce_end_io_read;
else
bio->bi_end_io = bounce_end_io_write;
//Hide the original bio
bio->bi_private = *bio_orig;
// If you steal the beam and change the pillar, the subsequent process will handle the rebound bio
*bio_orig = bio;
}
Creating a bounce buffer actually creates a new bio. This bio replaces the memory page that the original peripheral device cannot reach with a new accessible memory page, and sets a new callback function. In the subsequent process , the new rebound bio will be used instead of the original bio for processing. In order to transfer the data to the correct location, a new bio completion callback function is provided during rebound. After the bio is completed, the contents in the rebound buffer will be copied to the original After the memory area is unreachable, the end_io function of the original bio is called.
It can be found that the introduction of the bounce buffer results in additional data transmission, but this is unavoidable.
line18 ※2 bio segmentation
The purpose of bio segmentation here is that the maximum number of data segments supported by a specific lower-layer queue is different. For extremely large bios, segmentation is required. Segmentation is to segment a bio into multiple bios and divide them into multiple bios. These bios are linked.
In this function, bio_split and bio_chain will be called. The link here does not use bi_next link. Instead, the bi_private domain is used to link the new bio that is split and special processing is required, because first, bi_next is used for bio. Merge operation, secondly, if a bio is divided into several bios, their space release should be managed by the block IO subsystem layer, and should wait for an upward layer to be able to and can only call the original bio_end_io function before all are divided The bios that come out are reported once after they are completed, so their bio_end_io functions need to be replaced. The following is the actual implementation:
void __blk_queue_split(struct bio **bio, unsigned int *nr_segs)
{
struct request_queue *q = (*bio)->bi_bdev->bd_disk->queue;
struct bio *split = NULL;
//Special processing of different bio commands will eventually call the bio_split function
switch (bio_op(*bio)) {
case REQ_OP_DISCARD:
case REQ_OP_SECURE_ERASE:
split = blk_bio_discard_split(q, *bio, & amp;q->bio_split, nr_segs);
break;
case REQ_OP_WRITE_ZEROES:
split = blk_bio_write_zeroes_split(q, *bio, & amp;q->bio_split,
nr_segs);
break;
case REQ_OP_WRITE_SAME:
split = blk_bio_write_same_split(q, *bio, & amp;q->bio_split,
nr_segs);
break;
default:
/*
* All drivers must accept single-segments bios that are <=
* PAGE_SIZE. This is a quick and dirty check that relies on
* the fact that bi_io_vec[0] is always valid if a bio has data.
* The check might lead to occasional false negatives when bios
* are cloned, but compared to the performance impact of cloned
* bios themselves the loop below doesn't matter anyway.
*/
if (!q->limits.chunk_sectors & amp; & amp;
(*bio)->bi_vcnt == 1 & amp; & amp;
((*bio)->bi_io_vec[0].bv_len +
(*bio)->bi_io_vec[0].bv_offset) <= PAGE_SIZE) {
*nr_segs = 1;
break;
}
split = blk_bio_segment_split(q, *bio, & amp;q->bio_split, nr_segs);
break;
}
if (split) {
/* there isn't chance to merge the splitted bio */
split->bi_opf |= REQ_NOMERGE;
//The bio_chain function is called here
bio_chain(split, *bio);
trace_block_split(split, (*bio)->bi_iter.bi_sector);
//Submit the newly generated bio
submit_bio_noacct(*bio);
*bio = split;
blk_throtl_charge_bio_split(*bio);
}
}
bio_split function: The function is to split the input bio into two, the size of the divided sectors is used as the first bio and returned as the return value, and the remaining size is used as the second bio, which is directly modified in the input bio structure.
struct bio *bio_split(struct bio *bio, int sectors,
gfp_t gfp, struct bio_set *bs)
{
struct bio *split;
BUG_ON(sectors <= 0);
BUG_ON(sectors >= bio_sectors(bio));
/* Zone append commands cannot be split */
if (WARN_ON_ONCE(bio_op(bio) == REQ_OP_ZONE_APPEND))
return NULL;
split = bio_clone_fast(bio, gfp, bs);
if (!split)
return NULL;
split->bi_iter.bi_size = sectors << 9;
if (bio_integrity(split))
bio_integrity_trim(split);
// Spread the original bio across the first bio
bio_advance(bio, split->bi_iter.bi_size);
if (bio_flagged(bio, BIO_TRACE_COMPLETION))
bio_set_flag(split, BIO_TRACE_COMPLETION);
return split;
}
bio_chain function: Link the bios and modify the callback function to ensure that all bios on the chain are completed before they can be reported upward.
void bio_chain(struct bio *bio, struct bio *parent)
{
BUG_ON(bio->bi_private || bio->bi_end_io);
bio->bi_private = parent; // Use bi_private to string together
bio->bi_end_io = bio_chain_endio; // Modify end_io, which will check whether everything on the chain is completed. Note that the end_io at the front of the chain will not be modified.
bio_inc_remaining(parent); // Atomic operation modifies the __bi_remaining field
}
static inline void bio_inc_remaining(struct bio *bio)
{
bio_set_flag(bio, BIO_CHAIN);
smp_mb__before_atomic();
atomic_inc( & amp;bio->__bi_remaining); // Atomic operation
}
static void bio_chain_endio(struct bio *bio)
{
bio_endio(__bio_chain_endio(bio));
}
//The function of this function is to release one of its own reference counts and return the previous bio in the chain.
static struct bio *__bio_chain_endio(struct bio *bio)
{
struct bio *parent = bio->bi_private;
// bi_status == 0 means BLK_STS_OK
if (bio->bi_status & amp; & amp; !parent->bi_status)
parent->bi_status = bio->bi_status; // Error reporting needs to be inherited
bio_put(bio); // Release one of its own reference counts
return parent;
}
Endio will check whether everything is completed:
void bio_endio(struct bio *bio)
{
again:
if (!bio_remaining_done(bio)) // Check whether the bio chain is fully completed
return;
if (!bio_integrity_endio(bio)) // Integrity protection
return;
if (bio->bi_bdev & amp; & amp; bio_flagged(bio, BIO_TRACKED))
rq_qos_done_bio(bio->bi_bdev->bd_disk->queue, bio);
if (bio->bi_bdev & amp; & amp; bio_flagged(bio, BIO_TRACE_COMPLETION)) {
trace_block_bio_complete(bio->bi_bdev->bd_disk->queue, bio);
bio_clear_flag(bio, BIO_TRACE_COMPLETION);
}
/*
* Need to have a real endio function for chained bios, otherwise
* various corner cases will break (like stacking block devices that
* save/restore bi_end_io) - however, we want to avoid unbounded
* recursion and blowing the stack. Tail call optimization would
* handle this, but compiling with frame pointers also disables
* gcc's sibling call optimization.
*/
if (bio->bi_end_io == bio_chain_endio) { // Currently not the first one in the chain!
bio = __bio_chain_endio(bio); // Will always get the first one in the chain, only its bio_end_io is true
goto again; // bio_remaining_done needs to be re-judged
}
blk_throtl_bio_endio(bio);
/* release cgroup info */
bio_uninit(bio);
if (bio->bi_end_io)
bio->bi_end_io(bio); // Call the real endio
}
static inline bool bio_remaining_done(struct bio *bio)
{
/*
* If we're not chaining, then ->__bi_remaining is always 1 and
* we always end io on the first invocation.
*/
if (!bio_flagged(bio, BIO_CHAIN)) // If it is not bio on the chain, return true directly
return true;
BUG_ON(atomic_read( & amp;bio->__bi_remaining) <= 0);
// If it is bio on the chain, atomization makes __bi_remaining -1, if it is 0, eliminate the BIO_CHAIN tag
if (atomic_dec_and_test( & amp;bio->__bi_remaining)) {
bio_clear_flag(bio, BIO_CHAIN);
return true;
}
// If it is not 0, it means there is still unfinished bio behind this chain, return false
return false;
// But there may still be unfinished bio in the front, which will jump to the recursive processing again in endio.
// After one recursion, the __bi_remaining of the entire chain of the bio before this bio will be subtracted by 1.
// If the first one is reduced to 0, endio will be called
}
line20 ※3 Integrity protection
The biggest challenge in designing a storage system is to provide the reliability and availability that users expect. Data corruption due to hardware is relatively easy to detect and discover, but “silent data corruption” caused by write errors due to software is more troublesome because the data is detected when the application finally reads back the data. , the correct data has been permanently lost.
A commonly used technique to prevent data corruption is to append some additional information after the data when traversing the IO stack to detect the integrity of the data. We call this Integrity MetaData or Protection information. Information).
In order to support integrity protection, the SCSI protocol family has added new SCSI features to allow additional protection information (Data Integrity Field, DIF) to be exchanged between the controller and the disk. The Linux kernel has been further expanded to allow files to be The system adds integrity data (Data Integrity Extension, DIX) to the IO request. The combination of DIF and DIX enables “end-to-end” data protection along the complete IO path from the application to the disk drive.
More details are not available in this article for the time being, but we know that the data requests sent by the upper layer to the block IO subsystem are expressed using bio, so the corresponding integrity data will also be associated with bio. Therefore, there is a pointer field of bio_integrity_payload type in bio, which points to the bio integrity payload that saves integrity metadata:
struct bio_integrity_payload {
struct bio *bip_bio; /* parent bio */
struct bvec_iter bip_iter; // Iterator with similar functions to bio
unsigned short bip_vcnt; /* # of integrity bio_vecs */
unsigned short bip_max_vcnt; /* integrity bio_vec slots */
unsigned short bip_flags; /* control flags */
struct bvec_iter bio_iter; /* for rewinding parent bio */
struct work_struct bip_work; /* I/O completion work queue for io completion*/
struct bio_vec *bip_vec; // Similar function to bio, data starting point
struct bio_vec bip_inline_vecs[];/* embedded bvec array */
};
This structure serves as an additional load and additionally represents the location of the integrity data in the memory and some other accounting information.
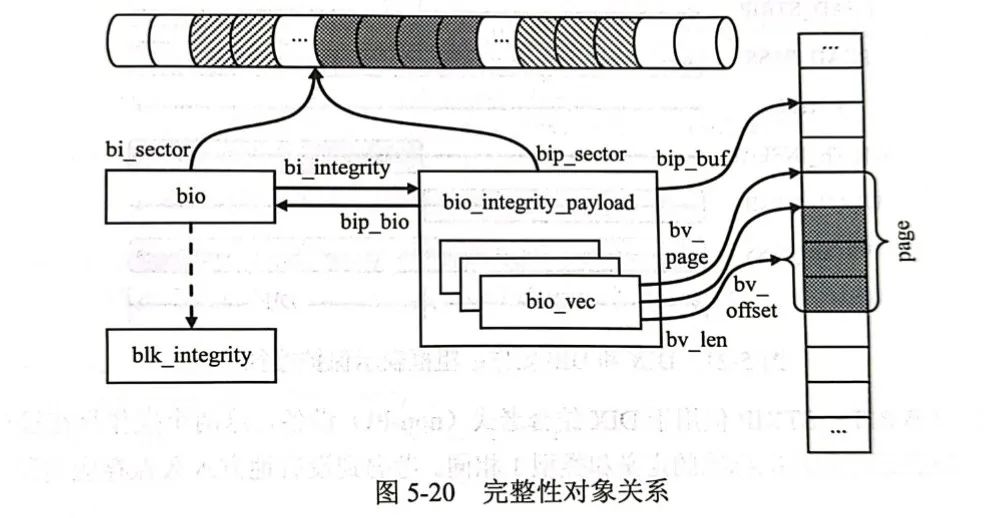
Therefore, the bio_integrity_prep(bio) function on line 20 is preparing integrity data for bio.
bool bio_integrity_prep(struct bio *bio)
{
struct bio_integrity_payload *bip;
struct blk_integrity *bi = blk_get_integrity(bio->bi_bdev->bd_disk);
void *buf;
unsigned long start, end;
unsigned int len, nr_pages;
unsigned int bytes, offset, i;
unsigned int intervals;
blk_status_t status;
if (!bi)
return true;
if (bio_op(bio) != REQ_OP_READ & amp; & amp; bio_op(bio) != REQ_OP_WRITE)
return true;
if (!bio_sectors(bio))
return true;
/* Already protected? */
if (bio_integrity(bio))
return true;
if (bio_data_dir(bio) == READ) {
if (!bi->profile->verify_fn ||
!(bi->flags & amp; BLK_INTEGRITY_VERIFY))
return true;
} else {
if (!bi->profile->generate_fn ||
!(bi->flags & amp; BLK_INTEGRITY_GENERATE))
return true;
}
intervals = bio_integrity_intervals(bi, bio_sectors(bio));
/* Apply for kernel space for integrity protection data */
len = intervals * bi->tuple_size;
buf = kmalloc(len, GFP_NOIO);
status = BLK_STS_RESOURCE;
if (unlikely(buf == NULL)) {
printk(KERN_ERR "could not allocate integrity buffer\\
");
goto err_end_io;
}
end = (((unsigned long) buf) + len + PAGE_SIZE - 1) >> PAGE_SHIFT;
start = ((unsigned long) buf) >> PAGE_SHIFT;
nr_pages = end - start;
/* Allocate bio integrity payload and integrity vectors */
bip = bio_integrity_alloc(bio, GFP_NOIO, nr_pages);
if (IS_ERR(bip)) {
printk(KERN_ERR "could not allocate data integrity bioset\\
");
kfree(buf);
status = BLK_STS_RESOURCE;
goto err_end_io;
}
bip->bip_flags |= BIP_BLOCK_INTEGRITY;
bip->bip_iter.bi_size = len;
bip_set_seed(bip, bio->bi_iter.bi_sector);
if (bi->flags & amp; BLK_INTEGRITY_IP_CHECKSUM)
bip->bip_flags |= BIP_IP_CHECKSUM;
/* Map it */
offset = offset_in_page(buf);
for (i = 0; i < nr_pages; i + + ) {
int ret;
bytes = PAGE_SIZE - offset;
if (len <= 0)
break;
if (bytes > len)
bytes = len;
ret = bio_integrity_add_page(bio, virt_to_page(buf),
bytes, offset);
if (ret == 0) {
printk(KERN_ERR "could not attach integrity payload\\
");
status = BLK_STS_RESOURCE;
goto err_end_io;
}
if (ret < bytes)
break;
buf + = bytes;
len -= bytes;
offset = 0;
}
/* Auto-generate integrity metadata if this is a write */
// For writing, the corresponding method needs to be called to generate integrity data
if (bio_data_dir(bio) == WRITE) {
bio_integrity_process(bio, & amp;bio->bi_iter,
bi->profile->generate_fn);
} else {
bip->bio_iter = bio->bi_iter;
}
return true;
err_end_io:
bio->bi_status = status;
bio_endio(bio);
return false;
}
If there is an error in the integrity check, software data corruption can be sensed in advance, which improves the reliability of the system as a whole, and more details are no longer known.
plug ※4 Accumulation
As we mentioned earlier, the design of bio is naturally mergeable, but if a bio comes, we will deal with it immediately. In other words, if there is always only one bio in our “bio pool”, what should we use to merge it? Woolen cloth? Therefore, the block device layer uses a technique called “Plugging/Unplugging” to improve throughput.
We are equivalent to using a reservoir to block bio for a period of time, so that there are multiple bios in our pool, and some bios with consecutive lba may be merged, reducing the number of issued ios and improving the overall throughput rate.
In previous Linux versions, when the request queue of a block device enabled the current accumulation, it would have a leak timer, which would leak regularly according to the set unplug_delay, and the kblockd kernel thread serving the kblockd_workqueue work queue would be awakened. , execute the corresponding q->unplug_work function to perform the leakage operation. This function will call the corresponding q->requst_fn function. This function is designed to process all requests in the request queue.
But under the current blk-mq mechanism, after checking the source code, it is no longer like this.
Under the current mechanism, the blk_start_plug function is called to initialize a blk_plug. This function indicates to the block layer the caller’s intention to submit multiple IO requests in batches. Based on this prompt, the block layer can defer the caller’s IO requests until blk_finish_plug() is called. before the function. However, the block layer can also submit requests in advance under some special circumstances:
-
The number of plug ios exceeds the maximum;
-
io size exceeds maximum.
Anyway, the common current storage and discharge methods are as follows:
int blkdev_issue_discard(struct block_device *bdev, sector_t sector,
sector_t nr_sects, gfp_t gfp_mask, unsigned long flags)
{
struct bio *bio = NULL;
struct blk_plug plug;
int ret;
blk_start_plug( & amp;plug);
ret = __blkdev_issue_discard(bdev, sector, nr_sects, gfp_mask, flags,
&bio);
if (!ret & amp; & amp; bio) {
ret = submit_bio_wait(bio);
if (ret == -EOPNOTSUPP)
ret = 0;
bio_put(bio);
}
blk_finish_plug( & amp;plug);
return ret;
}
blk_start_plug and blk_finish_plug are always used in pairs. During actual execution, the blk_mq_flush_plug_list function is finally called to submit the request to the IO scheduling queue.
void blk_finish_plug(struct blk_plug *plug)
{
if (plug != current->plug)
return;
blk_flush_plug_list(plug, false);
current->plug = NULL;
}
void blk_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
flush_plug_callbacks(plug, from_schedule);
if (!list_empty( & amp;plug->mq_list))
blk_mq_flush_plug_list(plug, from_schedule);
}
void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
LIST_HEAD(list);
if (list_empty( & amp;plug->mq_list))
return;
list_splice_init( & amp;plug->mq_list, & amp;list);
if (plug->rq_count > 2 & amp; & amp; plug->multiple_queues)
list_sort(NULL, & amp;list, plug_rq_cmp);
plug->rq_count = 0;
do {
struct list_head rq_list;
struct request *rq, *head_rq = list_entry_rq(list.next);
struct list_head *pos = & amp;head_rq->queuelist; /* skip first */
struct blk_mq_hw_ctx *this_hctx = head_rq->mq_hctx;
struct blk_mq_ctx *this_ctx = head_rq->mq_ctx;
unsigned int depth = 1;
list_for_each_continue(pos, & amp;list) {
rq = list_entry_rq(pos);
BUG_ON(!rq->q);
if (rq->mq_hctx != this_hctx || rq->mq_ctx != this_ctx)
break;
depth + + ;
}
list_cut_before( & amp;rq_list, & amp;list, pos);
trace_block_unplug(head_rq->q, depth, !from_schedule);
blk_mq_sched_insert_requests(this_hctx, this_ctx, & amp;rq_list,
from_schedule);
} while(!list_empty( & amp;list));
}
It can be seen that the result of the current accumulation finally calls the blk_mq_sched_insert_requests function to enter the io scheduling link.
During the accumulation process, a merge may occur. For example, in the blk_mq_submit_bio function above, the blk_attempt_plug_merge function is first called to attempt a merge operation.
The blk_attempt_plug_merge function will eventually be called:
static enum bio_merge_status blk_attempt_bio_merge(struct request_queue *q,
struct request *rq,
struct bio *bio,
unsigned int nr_segs,
bool sched_allow_merge)
{
if (!blk_rq_merge_ok(rq, bio))
return BIO_MERGE_NONE;
switch (blk_try_merge(rq, bio)) {
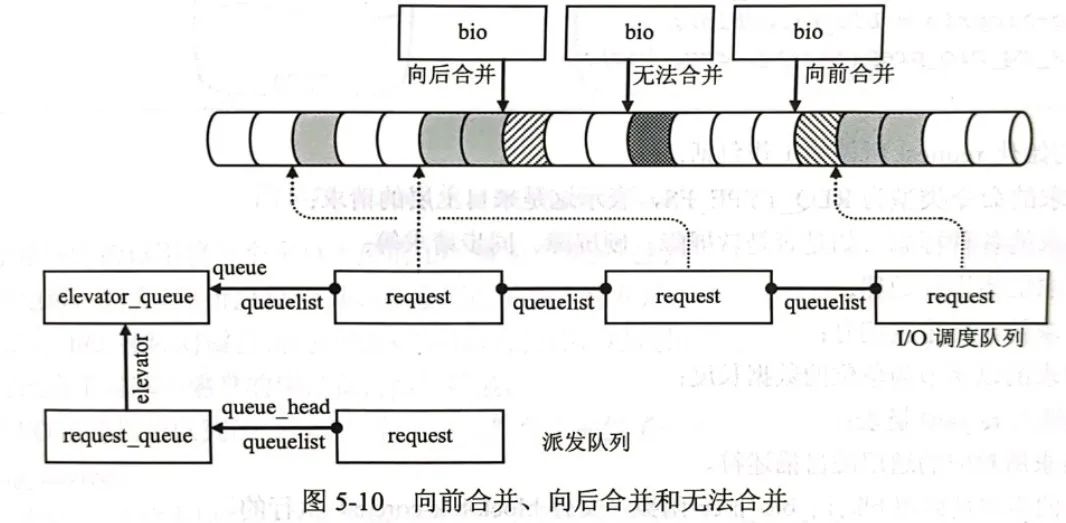
case ELEVATOR_BACK_MERGE: // Merge backwards
if (!sched_allow_merge || blk_mq_sched_allow_merge(q, rq, bio))
return bio_attempt_back_merge(rq, bio, nr_segs);
break;
case ELEVATOR_FRONT_MERGE: // merge forward
if (!sched_allow_merge || blk_mq_sched_allow_merge(q, rq, bio))
return bio_attempt_front_merge(rq, bio, nr_segs);
break;
case ELEVATOR_DISCARD_MERGE: // DISCARD mode merge
return bio_attempt_discard_merge(q, rq, bio);
default:
return BIO_MERGE_NONE;
}
return BIO_MERGE_FAILED;
}
enum elv_merge blk_try_merge(struct request *rq, struct bio *bio)
{
if (blk_discard_mergable(rq))
return ELEVATOR_DISCARD_MERGE;
else if (blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector)
return ELEVATOR_BACK_MERGE;
else if (blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector)
return ELEVATOR_FRONT_MERGE;
return ELEVATOR_NO_MERGE;
}
Correspond to the following situations respectively: