
This article mainly introduces the details of automated testing of the Python + requests + unittest execution interface. The article provides a detailed introduction around the topic, which has certain reference value. Friends in need can refer to it.
1. Install requests, xlrd, json, unittest libraries
<1>Pip command installation:
pip install requests
pip install xlrd
pip install json
pip install unittest
2. Create six types of Python Packages
Use the Page Object Model design concept to create six types of Python Packages (can also be implemented according to project requirements)

3. Create a Base_Page.py
First create a Base_Page.py in the base package

<1>Import the module and create a Base class to encapsulate various request methods
import requests #Import requests module
classBase():
def method_post(self, url, params = None, data = None, headers = None, files = None):
return requests.post(url = url,params = params,data = data,headers = headers,files = files)
def method_get(self, url, params = None, data = None, headers = None, files = None):
return requests.get(url = url,params = params,data = data,headers = headers,files = files)
def method_put(self, url, params = None, data = None, headers = None, files = None):
return requests.put(url = url,params = params,data = data,headers = headers,files = files)
def method_delete(self,url,params = None,data = None,headers = None,files = None):
return requests.delete(url = url,params = params,data = data,headers = headers,files = files
Because every request will have params parameters or data parameters, but it is impossible for both to exist, so None is used here, and so on.
<2>Adapted to the execution of interface use cases, when reading the Excel table, various types of requests are judged, and when they match which one, which one is executed
def requests_type(self, method, url, params = None, data = None, headers = None, files = None):
if method =='post' or method =='POST':
return self.method_post(url = url,params = params,data = data,headers = headers,files = files)
elif method =='get' or method =='GET':
return self.method_get(url = url,params = params,data = data,headers = headers,files = files)
elif method =='put' or method =='PUT':
return requests.put(url = url,params = params,data = data,headers = headers,files = files)
elif method =='delete' or method =='DELETE':
return requests.delete(url = url,params = params,data = data,headers = headers,files = files)
<3> Simply debug several requests. If the debugging is successful, then we can proceed to the next item

You can also encapsulate and save the interface that needs to get the cookie:
def Get_Login_cookie(self,data):
res = self.method_post(url = "Request URL",data = data)
return {"userId":str(res.json()['result']['userId']),"sessionId":res.json()['result'][ 'sessionId']}
After that, we need to clear these codes for base page verification, otherwise these interfaces will always be adjusted.
4. Create common class
Create the commons.py file under the common class and create the common class

<1> Encapsulation log method
Here I added a data package to store the xlrd table, as well as the html report storage path and log storage path.
log_path = r'D:\PycharmProjects\Automation Interface\Automation Interface Test\report\logs'
report_html = r'D:\PycharmProjects\Automation Interface\Automation Interface Test\report\html'
read_xlrd = r'D:\PycharmProjects\Automation Interface\Automation Interface Test\data'
class Common():
#Encapsulation log method
def get_logs(self,path = log_path):
import logging,time
logs = logging.getLogger()
logs.setLevel(logging.DEBUG)
path = path + '/' + time.strftime('%Y-%m-%d-%H-%M-%S') + '.log'
write_file = logging.FileHandler(path,'a + ',encoding='utf-8')
write_file.setLevel(logging.DEBUG)
set_logs = logging.Formatter('%(asctime)s - %(filename)s - %(funcName)s - %(levelname)s - %(message)s')
write_file.setFormatter(set_logs)
pycharm_text = logging.StreamHandler()
pycharm_text.setFormatter(set_logs)
logs.addHandler(write_file)
logs.addHandler(pycharm_text)
return logs
<2> Encapsulate the method of reading Excel table and convert it into dictionary form to facilitate reading in json format
# Read Excel table method to facilitate subsequent reading of interface use case data
def ReadExcelTypeDict(self,file_name,path = read_xlrd):
path = path + '/' + file_name
import xlrd
work_book = xlrd.open_workbook(path) #Open Excel table
sheets = work_book.sheet_names() # Get all sheets pages
DataList = []
for sheet in sheets:
sheets = work_book.sheet_by_name(sheet)
nrows = sheets.nrows
for i in range(0,nrows):
values = sheets.row_values(i)
DatasList.append(values)
title_list = DatasList[0]
content_list = DatasList[1:]
new_list = []
for content in content_list:
dic = {}
for i in range(len(content)):
dic[title_list[i]] = content[i]
new_list.append(dic)
return new_list #Finally returned in dictionary form with keys and values
Why do you need to convert the format?
This involves how to design an automation interface use case

The parameter values of the use case must be written in json format without spaces.
The expected result parameters must also be written in json format.
If there is no ‘ ‘ value, it must be wrapped with ” “
<3>Encapsulate a method of generating HTML reports
# Encapsulate an HTML report method
def GetHtmlResult(self,suite,title,path = report_html):
import HTMLTestReportCN,time
path = path + '/' + time.strftime('%Y-%m-%d-%H-%M-%S') + '.html'
with open(path,'wb + ') as f:
run = HTMLTestReportCN.HTMLTestRunner(stream=f, description='User-related interface test report', tester='Xiaobai', title = title)
run.run(suite)
If there are others that need to be added, you can continue to add them. The three I have here are basically enough.
5. Read Excel data table for joint use
Create a test case under the case package, and call the request api we encapsulated in the base page and read the Excel data table in common for joint use.
<1>Create test_login.py

<2> Import unittest, commons class under common class, ddt data driver, base_page page under Base
import unittest import ddt import automated interface testing.common.commons as common from automated interface testing.base.Base_Page import Base
<3> Build the inside of the unittest framework and fill in the methods
import unittest
import ddt
import automated interface testing.common.commons as common
from automated interface testing.base.Base_Page import Base
r = common.Common().ReadExcelTypeDict('cezxhi .xlsx') # Get specific Excel table data
@ddt.ddt #Import ddt module
class TestLogin(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None: # setupclass class method is executed once before all use cases start
cls.logs = common.Common().get_logs() # Import log method
cls.logs.debug('Start writing interface automated test cases')
@classmethod
def tearDownClass(cls) -> None:
cls.logs.debug('Automation interface use case ends')
def setUp(self) ->None:
self.logs.debug('Start this interface use case')
def tearDown(self) ->None:
self.logs.debug('End this use case')
@ddt.data(*r) #Introduce the ddt module and read the obtained data
def test_logins(self,pars): # The use case method name must start with the test pars parameter as the received table data value
import json #Import json module
dic = json.loads(pars['body parameter value']) # Convert parameter values in Excel data to json format
url = pars['interface address'] # Get the request url
yuqi = pars['Expected result'] # Get the expected result
fs = pars['request method'] # Get the request method
result = Base().requests_type(method = fs,url = url,data = dic) # Fill in the request api of the base page
self.assertEqual(result.text,yuqi) # Make assertions to see if the use case passes
<4> Generate test report after executing the test case:
if __name__ == '__main__':
load = unittest.TestLoader().loadTestsFromTestCase(TestLogin) #Use the loader loading method to find all use cases starting with test
suite = unittest.TestSuite([load,])
common.Common().GetHtmlResult(suite,'Login test case')
<5> Copy the path of the script currently to be executed and add it to the running mode of python




Finally let’s run it

The console looks like this

Why is there 400? Because some interfaces are abnormal, such as wrong url, few parameters or empty parameters are passed in, so errors will occur. This is common sense.
<6> Take a look at the generated test report
This is what happens in pycharm

Then we copy his path and view it in the browser

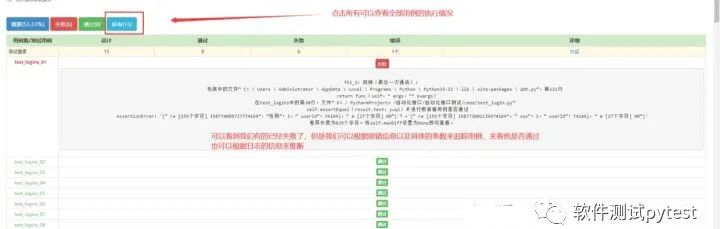
According to the information I tracked, the first failure was because the sessionId can change, and the value is different every time. I also hope that everyone can find the BUG and properly handle every problem.
This concludes this article about the details of automated testing of the Python + requests + unittest execution interface.
Take action, it’s better to be on the road than to wait and see. In the future, you will definitely thank yourself for working hard now! If you want to learn and improve but can’t find the information and there is no one to answer your questions, please join the group in time: 786229024. There are various test and development materials and technologies in which you can communicate together.
Finally: The complete software testing video tutorial below has been compiled and uploaded. Friends who need it can get it by themselves[Guaranteed 100% Free]

Software testing interview document
We must study to find a high-paying job. The following interview questions are the latest interview materials from first-tier Internet companies such as Alibaba, Tencent, Byte, etc., and some Byte bosses have given authoritative answers. After finishing this set I believe everyone can find a satisfactory job based on the interview information.



The knowledge points of the article match the official knowledge files, and you can further learn relevant knowledge. Python entry skill treeWeb crawlerrequests387195 people are learning the system