
This time I really found a powerful OCR to help me solve the problem
1. The usual situation
If you need to extract text from PDF, the first software that comes to mind is Format Factory.
Just use its “PDF→Text” function. The advantage is that the software runs quickly and the processing time is short.
It takes about the same amount of time as executing a Python script to do this.

2. The particularity of this issue
However, in this PDF, the text copy permission is encrypted,
Format Factory software is relatively weak in facing this problem.
It will directly return a PDFEncryptionError error, which means that the encrypted content cannot be decoded.

3. Related work
After that, I went to Taobao and searched for “PDF to text”.
Try to find a suitable service,
to solve my problem (preferably permanently),
Then I bought this:
may change over time
This store may be updated
The original product may not be found
But it doesn’t matter
You can also find the software by looking at the software name and company name I give later.
Soon, I got the link to install the package:
https://www.123pan.com/s/cUqKVv-hkpvd.html
Extraction code: 5waF
Download, install and run FineReaderOCR.exe in the installation directory
The interface of the software is as follows:

Open the PDF file, and then, it still asks me to enter the password,
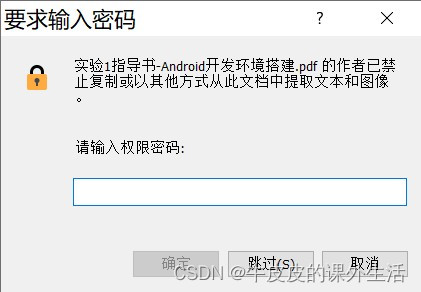
Of course I don’t know the password.
4. Solution
However, with the power of this software
I feel that this OCR is not simple
Reason: It can open PDF files for detailed processing and has many functions.
This is something that ordinary OCR that can only process images cannot do.
Without further ado, my solution to the above problems is as follows:
[1]You can still view this PDF as a file composed of multiple pictures,
This means that 33 pictures can be extracted from this 33-page PDF.
To achieve this step, I used the script I usually develop,
Note that the running environment of this script is built by Python3, and the operating system is windows.
import os
import fitz
# You should not just use pip install fitz to install fitz, but install both fitz and PyMuPDF at the same time
# Be sure to pay attention to the installation order: install fitz first, and then install pymupdf. If the order is reversed, it will not be imported.
# Also note: You cannot install only PyMuPDF. When only PyMuPDF is installed, although you can use import fitz, an error will occur when running fitz.open(), etc.
# If the number of PDF pages exceeds 10,000 pages, please make appropriate modifications to the statement "pg_str='0'*(4-len(str(pg))) + str(pg)"
class _function_:
def WinPathToLinuxPath(p):
ll = p.split('') # delete the '' of path
linux_path = '/'.join(ll) # add the '/' into path
# Determine whether there is a '/' at the end of the folder
if linux_path[-1].__eq__('/'):
return linux_path
else:
return linux_path + '/'
def pyMuPDF_fitz(pdf_path, image_path):
pdf_doc = fitz.open(pdf_path)
pic_cnt = pdf_doc.page_count
for pg in range(pic_cnt):
print(str(pg + 1) + '/' + str(pic_cnt), end='\r', flush=True)
page = pdf_doc[pg]
rotate = int(0)
# Each size is scaled by a factor of 3, which will give us an image with 9 times higher resolution.
# If no setting is made here, the default image size is: 792X612, dpi=96
zoom_x = 3 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 3
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
if not os.path.exists(image_path): # Determine whether the folder storing the image exists
os.makedirs(image_path) # If the image folder does not exist, create it
pg_str='0'*(4-len(str(pg))) + str(pg) # Change the serial number to a four-digit serial number
pix.save(image_path + 'images_' + pg_str + '.jpg') # Write the image to the specified folder
if __name__=='__main__':
print('input the pdf path of Windows:')
winPath = input()
pdfPath = _function_.WinPathToLinuxPath(winPath) # Format this path
pdfName = input('input the pdfName of the converted image:')
print('input the pic path of Windows:')
winPath = input()
picPath = _function_.WinPathToLinuxPath(winPath) # Format this path
pyMuPDF_fitz(pdfPath + pdfName + '.pdf', picPath)
# [Reference link] https://blog.csdn.net/jerryshen888/article/details/106862526 [Solution to Python fitz module import error]
# [Reference link] https://blog.csdn.net/weixin_42081389/article/details/103712181 [Several methods of converting PDF to images in python]
# [Reference link] https://blog.csdn.net/m0_54783845/article/details/125797337 [AttributeError: no attribute 'writePNG']
After running the script, enter:
The folder path where the PDF file is located The name of the PDF file (no file suffix required) Set the folder path for output images
Example:
D:\ ew folder pdfFile D:\ ew Folder\ ew Folder
[2]Now I have 33 pictures in hand,
I can then stitch them into a PDF,
A PDF like this has no encryption at all.
To implement this step, I still used the script I usually develop.
Note that the running environment of this script is built by Python3, and the operating system is windows.
import os
import img2pdf
class _function_:
def WinPathToLinuxPath(p):
ll = p.split('') # delete the '' of path
linux_path = '/'.join(ll) # add the '/' into path
# Determine whether there is a '/' at the end of the folder
if linux_path[-1].__eq__('/'):
return linux_path
else:
return linux_path + '/'
def picToPDF(pic_path_, pdf_path_, name_):
# 1. Generate address list
photo_list = os.listdir(pic_path_)
photo_list = [os.path.join(pic_path_, i) for i in photo_list]
# 2. Specify the width and height of a single page of pdf in 'mm' or 'px'
# One pixel is approximately equal to 0.35 mm
category = input('Specify unit:')
width = int(input('Specify the width of a single page of pdf: '))
high = int(input('Specify the height of a single page of pdf: '))
if category=='mm':
pass
elif category=='px':
width = int(0.35 * width)
high = int(0.35 * high)
a4inpt = (img2pdf.mm_to_pt(width), img2pdf.mm_to_pt(high))
layout_fun = img2pdf.get_layout_fun(a4inpt)
# 3. Generate pdf file
with open(pdf_path_ + name_ + '.pdf', 'wb') as f:
f.write(img2pdf.convert(photo_list, layout_fun=layout_fun, rotation=img2pdf.Rotation.ifvalid))
f.close()
# [img2pdf.convert parameter rotation=img2pdf.Rotation.ifvalid]
# Use rotation=img2pdf.Rotation.ifvalid because the following error has occurred before [this parameter can be omitted if not necessary]
# img2pdf.ExifOrientationError: Invalid rotation (0):
# use --rotation=ifvalid or rotation=img2pdf.Rotation.ifvalid to ignore
# [Reference link] https://github.com/ocrmypdf/OCRmyPDF/issues/894 [img2pdf.ExifOrientationError is easy to fix]
if __name__=='__main__':
print('input the pic path of Windows:')
winPath = input()
picPath = _function_.WinPathToLinuxPath(winPath) # Format this path
print('input the pdf path of Windows:')
winPath = input()
pdfPath = _function_.WinPathToLinuxPath(winPath) # Format this path
name = input('input the pdfName:')
picToPDF(picPath, pdfPath, name)
# [Reference link] https://blog.csdn.net/weixin_42081389/article/details/100734926 [Combining pictures into PDF under python]
# img2pdf installation command: pip3 install img2pdf
# [Reference link] https://blog.csdn.net/lqzixi/article/details/112756326 [Learn to use pip3 commands]
# To install img2pdf, you need to install the following packages: Pillow, pikepdf, lxml (version required >= 4.8), packaging, deprecation
# You can use the "pip list" command to check whether it is installed.
After running the script, enter:
The folder path where the picture is located Set the folder path for output PDF files Set the name of the PDF file Specify the unit of the side length of the image. The default is "px", which means pixels. Specify the horizontal side length of the image Specify the vertical side length of the image
Example:
D:\ ew Folder\ ew Folder D:\ ew folder newPdfFile px 1080 1920
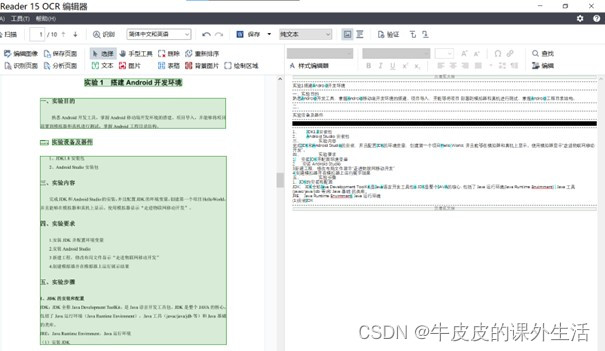
[3] Got the new PDF file and reopened it in FineReaderOCR.exe
The text recognition effect is as follows:
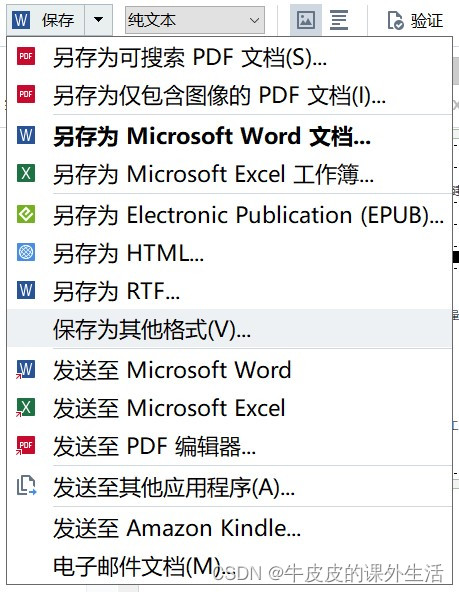
Recognition results can be saved in a variety of file formats:
5. Introduce the software
FineReaderOCR is a sub-software of FineReader.
When installing FineReader, FineReaderOCR will be installed.
FineReader is developed by a software company called ABBYY.
It can be basically determined that its OCR functions are diverse and powerful.
It is worth noting that ABBYY is a Russian company.
Just when pear blossoms are blooming all over the world
Soft gauze floats on the river
Katyusha stood on the steep shore…