Concurrent synchronization
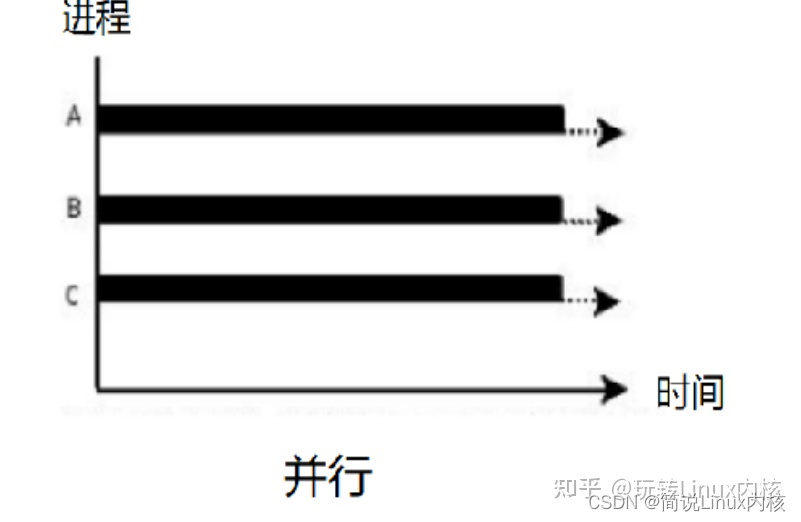
Concurrency refers to the ability to process multiple tasks within a certain period of time, while parallelism refers to the ability to process multiple tasks at the same time. Concurrency and parallelism look similar, but they are actually different, as shown in the following picture (picture from the Internet):

The picture above means that there are two queues queuing up to buy coffee, and only one coffee machine is processing, while two coffee machines are processing in parallel. The greater the number of coffee machines, the stronger the parallelism. The above two queues can be regarded as two processes. Concurrency means that only a single CPU is processing, while two CPUs are processing in parallel. In order to allow two processes to be executed on a single-core CPU, the general method is to let each process execute alternately for a period of time, for example, let each process execute for a fixed period of 100 milliseconds, and then switch to other processes for execution after the execution time is used up. There is no such problem in parallel, because there are two CPUs, so two processes can be executed at the same time. As shown below:
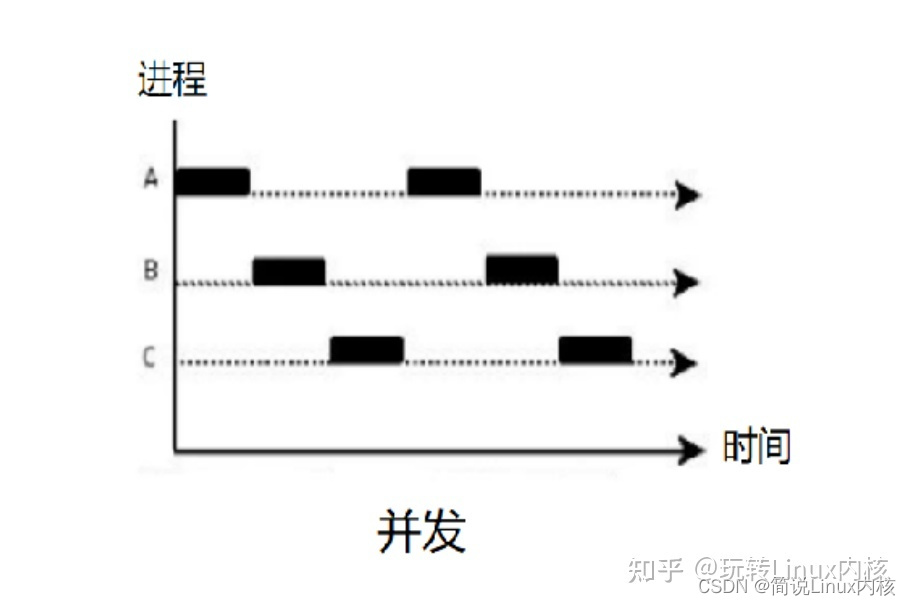
As mentioned above, concurrency may interrupt the currently executing process, and then switch to other processes for execution. If two processes add one to a shared variable count at the same time, the count ++ operation in C language will be translated into the following instructions:
mov eax, [count] inc eax mov [count], eax
Then in the case of concurrency, the following problems may occur:

Assuming the initial value of the count variable is 0:
-
After process 1 executes mov eax, [count], the register eax stores the value of count 0.
-
Process 2 is scheduled for execution. Process 2 executes all instructions of count ++ and writes the accumulated count value 1 back to memory.
-
Process 1 is scheduled to execute again, and the accumulated value of count is still 1, which is written back to the memory.
Although process 1 and process 2 perform count ++ operations twice, the final value of count is 1, not 2. To solve this problem, you need to use atomic operations. Atomic operations refer to operations that cannot be interrupted. In a single-core CPU, an instruction is an atomic operation. For example, in the above question, the count ++ statement can be translated into the instruction inc [count]. Linux also provides such atomic operations, such as atomic_inc() for adding integers:
static __inline__ void atomic_inc(atomic_t *v)
{
__asm__ __volatile__(
LOCK "incl %0"
:"=m" (v->counter)
:"m" (v->counter));
}
In a multi-core CPU, an instruction is not necessarily an atomic operation. For example, the inc [count] instruction requires the following process in a multi-core CPU:
-
\1. Read count data from memory to cpu.
-
\2. Accumulate the read value.
-
\3. Write the modified value back to the count memory.
Intel x86 CPU provides a lock prefix to lock the bus, which allows instructions to be guaranteed not to be interrupted by other CPUs, as follows:
lock inc [count]
lock
Atomic operations can ensure that the operation will not be interfered by others, but sometimes a complex operation needs to be implemented by multiple instructions, then atomic operations cannot be used, and locks can be used at this time. The locks in computer science are somewhat similar to the locks in daily life. For example, if you want to go to a public toilet, first find an empty toilet, and then lock the toilet door. If other people want to use it, they must wait for the current person to use it and unlock the door before using it. In a computer, when operating on a public resource, the public resource must be locked before it can be used. If it is not locked, it may lead to data confusion.
In the Linux kernel, the more commonly used locks are: spin locks, semaphores, read-write locks, etc. The following introduces the implementation of spin locks and semaphores.
Spin lock
Spin locks can only be used in multi-core CPU systems. The core principle is atomic operations. The principle is as follows:
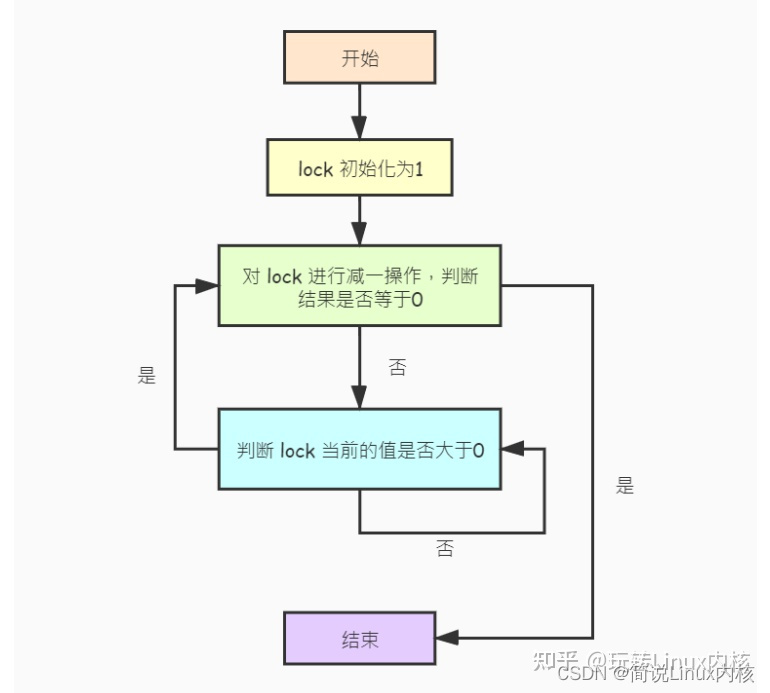
When using a spin lock, the spin lock must be initialized first (set to 1), and the locking process is as follows:
-
\1. Subtract one from the spin lock lock, and judge whether the result is equal to 0. If it is, it means that the lock is successful and returns.
-
\2. If it is not equal to 0, it means that other processes have already locked it. At this time, it is necessary to continuously compare whether the value of the spin lock lock is equal to 1 (indicating that it has been unlocked).
-
\3. If the spin lock lock is equal to 1, jump to the first step to continue the lock operation.
Since the spin lock of Linux is implemented in assembly, it is rather bitter and difficult to understand. Here we use C language to simulate it:
void spin_lock(amtoic_t *lock)
{
again:
result = --(*lock);
if (result == 0) {
return;
}
while (true) {
if (*lock == 1) {
goto again;
}
}
}
The above code regards result = –(*lock); as an atomic operation, and the unlocking process only needs to set lock to 1. Since the spin lock will continue to try to lock the operation and will not schedule the process, it may cause 100% CPU usage in a single-core CPU. In addition, optional locks are only suitable for operations with relatively small granularity. If the granularity of operations is relatively large, you need to use semaphores, which are schedulable process locks.
Information through train: the latest Linux kernel source code documentation + video information
Kernel learning address: Linux kernel source code/memory tuning/file system/process management/device driver/network protocol stack
Semaphore
Unlike spin locks, when the current process locks the semaphore, if other processes have already locked it, the current process will go to sleep and wait for others to unlock the semaphore. The process is as follows:

In the Linux kernel, the semaphore is represented by struct semaphore, which is defined as follows:
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
The functions of each field are as follows:
-
lock : spin lock, used to synchronize multi-core CPU platforms.
-
count : The counter of the semaphore, which is decremented by one when it is locked (count–). If the result is greater than or equal to 0, it means that the lock is successful, and if it is less than 0, it means that it has been locked by other processes.
-
wait_list : A queue of processes waiting for the semaphore to be unlocked.
The semaphore is locked through the down() function, the code is as follows:
void down(struct semaphore *sem)
{
unsigned long flags;
spin_lock_irqsave( & sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
spin_unlock_irqrestore( & amp;sem->lock, flags);
}
As can be seen from the above code, the down() function first performs a spin lock operation on the semaphore (in order to avoid multi-core CPU competition), and then compares whether the counter is greater than 0. If it is to subtract one from the counter, it returns, otherwise it calls __down () function to proceed to the next step.
The __down() function is implemented as follows:
static noinline void __sched __down(struct semaphore *sem)
{
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
static inline int __down_common(struct semaphore *sem,
long state, long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
// Add the current process to the waiting queue
list_add_tail( &waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = 0;
for (;;) {
...
__set_task_state(task, state);
spin_unlock_irq( &sem->lock);
timeout = schedule_timeout(timeout);
spin_lock_irq( &sem->lock);
if (waiter.up) // Does the current process acquire a semaphore lock?
return 0;
}
...
}
The __down() function finally calls the __down_common() function, and the __down_common() function operates as follows:
-
Add the current process to the semaphore’s waiting queue.
-
Switch to another process to run until it is woken up by another process.
-
If the current process acquires the semaphore lock (passed by the unlocking process), then the function returns.
Next, look at the unlocking process. The unlocking process is mainly implemented through the up() function. The code is as follows:
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave( & sem->lock, flags);
if (likely(list_empty( & amp;sem->wait_list))) // If there is no waiting process, directly add one to the counter
sem->count + + ;
else
__up(sem); // If there is a waiting process, then call the __up() function to wake up
raw_spin_unlock_irqrestore( & sem->lock, flags);
}
static noinline void __sched __up(struct semaphore *sem)
{
// Get the first process in the waiting queue
struct semaphore_waiter *waiter = list_first_entry(
&sem->wait_list, struct semaphore_waiter, list);
list_del( & amp;waiter->list); // delete the process from the waiting queue
waiter->up = 1; // Tell the process that the semaphore lock has been acquired
wake_up_process(waiter->task); // wake up the process
}
The unlocking process is as follows:
-
Determine whether the current semaphore has a waiting process. If there is no waiting process, directly operate the counter
-
If there is a waiting process, get the first process in the waiting queue.
-
Remove the process from the waiting queue.
-
Tells the process that the semaphore lock has been acquired
-
wake up process